When we think of AI in the context of films, we are reminded of genre-bending movies like ‘The Matrix’, ‘Ex Machina’, ‘Her’, and so on. Today, in 2024, we are at that moment when Text-to-Video AI technology is emerging as a game-changing tool that can generate videos and animation with just the right set of prompts. You can now convert plain text into a vivid video, complete with visuals and sound, with a stream of sentences fed into an AI tool. Very soon, we might be eating popcorn while watching full movies being streamed from an AI-powered bot.
Leading the charge in this field are giants like Microsoft, Google, and Facebook, investing billions into this transformative technology. As it stands today, Text-to-Video AI is revolutionizing industries far and wide, from making education more engaging to helping marketers with creatives. It can be a cost-effective way for businesses to create compelling video content without the need for expensive production equipment.
Adobe’s incorporation of AI into Photoshop, for example, signals the growing trend of AI-generated content. GauGAN, developed by NVIDIA, is an AI-based painting tool that can transform simple sketches into realistic landscapes.
The technology’s hyper-personalization capabilities mean content tailored specifically for you – it’s as if it’s speaking directly to you. Thanks to collaborations between tech giants and top academic institutions, the reliability and sophistication of AI-generated information are soaring.
Storyboarding with AI
If you are looking to create a storyboard for a film, some AI tools can come in handy. Let’s demonstrate this with a fun example.
Let’s imagine that you have the draft of an ancient Roman war biopic, and you would like to see it come to life. In this blog post, we’ll take you through the step-by-step process of how you can leverage the power of text-to-video AI to generate storyboarding visuals for your biopic.
We will use Text-to-Video Generative AI technology LaVie in this case. The technology is still in its early phases, but in the near future, it will transform how media production works. Let’s dive in.
LaVie - The Text-to-Video AI
LaVie stands as a powerful open-source text-to-video generation AI capable of translating words into captivating visual narratives. One of LaVie’s key strengths lies in its innovative architecture. It seamlessly combines three distinct models: a base text-to-video model, a temporal interpolation model, and a video super-resolution model. This multi-pronged approach ensures that the generated videos not only capture the essence of the textual input but also possess a natural sense of temporal progression and visual detail.
LaVie’s prowess is further bolstered by a massive dataset called Vimeo25M. This carefully curated treasure trove of 25 million text-video pairs provides the AI with a rich tapestry of real-world examples, enhancing its ability to learn and generate diverse, high-quality content. Vimeo25M prioritizes not just technical excellence but also aesthetic appeal, ensuring that LaVie-generated videos feel and look good.
Without any further delay, let’s begin.
Deployment, Inference and Results
To start with, clone the LaVie github repository, and create a Conda environment using the environment.yaml file. This file contains all the dependencies that are needed for LaVie to run.
git clone https://github.com/Vchitect/LaVie.git
conda env create -f LaVie/environment.yml
conda activate lavie
cd LaVie/pretrained_models
git lfs install
git clone https://huggingface.co/Vchitect/LaVie .
git clone https://huggingface.co/CompVis/stable-diffusion-v1-4
git clone https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler
## Should look like:
├── pretrained_models
│ ├── lavie_base.pt
│ ├── lavie_interpolation.pt
│ ├── lavie_vsr.pt
│ ├── stable-diffusion-v1-4
│ │ ├── ...
└── └── stable-diffusion-x4-upscaler
├── ...Download the following pretrained models into the ./pretrained_models folder, and organize it as is shown in the diagram.
Inference
There are three steps to inferencing and generating videos from text prompts. Combinations of these steps will generate the output in the following format:
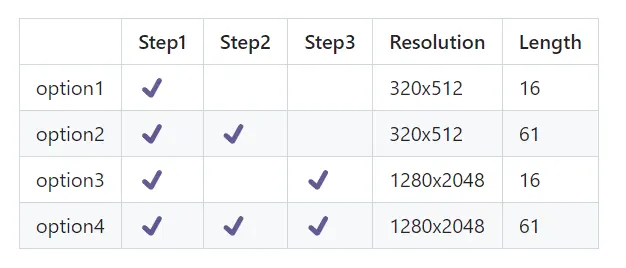
So, if we need a video of resolution 1280x2048 with 61 frames in length, we’ll have to follow all the three steps one after another.
Step 1: Base Text to Video.
cd base
python pipelines/sample.py --config configs/sample.yamlIn the following sample.yaml file, these are the meanings of the arguments.
ckpt_path: Path to the downloaded LaVie base model, default is ../pretrained_models/lavie_base.pt
pretrained_models: Path to the downloaded SD1.4, default is ../pretrained_models
output_folder: Path to save generated results, default is ../res/base
seed: Seed to be used, None for random generation
sample_method: Scheduler to use, default is ddpm, options are ddpm, ddim and eulerdiscrete
guidance_scale: CFG scale to use, default is 7.5
num_sampling_steps: Denoising steps, default is 50
text_prompt: Prompt for generationLet’s set the seed to 400, sample_method to ddpm, guidance scale to 7.0, and num_sampling_steps to 50.
DDPM stands for Denoising Diffusion Probabilistic Models, and is a powerful and increasingly popular class of generative models used to create image, audio, and even text.
They work by gradually removing noise from a randomly generated starting point (which is the seed), ultimately revealing the desired underlying data. Imagine starting with a blurry mess and progressively clearing it up until a recognizable image emerges.
Let’s decide on the text prompts that will go in the sample.yaml file to generate the video snippets for our screenplay.
- A busy roman market
- A boy in toga plays with his dog
- A sword duel between two Roman generals
- A crowd triumphantly cheers a Roman leader as he comes back home in his chariot after winning a battle
- A tense meeting in the Roman Senate
We will append the following to every prompt: Scene from 750 BC, animated sketch with watercolors (to give it the effect of a story board).
The outputs will be stored in the ./res/base folder.
Step 2 (optional): Video Interpolation.
In configs/sample.yaml, we modify input_folder to ../res/base, which is already the default. The videos should be named as prompt1.mp4, prompt2.mp4, and so on. The results will be saved under ../res/interpolation.
cd interpolation
python sample.py --config configs/sample.yamlStep 3 (optional): Video Super-Resolution
The default input video path is ./res/base and the results will be saved under ./res/vsr.
cd vsr
python sample.py --config configs/sample.yamlResults
Executing step 1, we get the following videos (encoded as gifs):




Conclusion
The provided installation and inference guide for LaVie empowers users to harness the capabilities of this advanced Text-to-Video model. By following the outlined steps, users can seamlessly set up the environment, clone the necessary repositories, and generate desired video content from text prompts. In this case we successfully created some storyboards for our Roman biopic.
As Text-to-Video AI continues to evolve, the future promises a more immersive, personalized, and accessible media experience. This creative renaissance invites us into a world where the boundaries between words and visuals beautifully blur, captivating audiences in ways never seen before.



-Feature-Image.CjBFdO7y_Z1bTNvg.webp)