For modern enterprises, staying up to date with artificial intelligence is a must if you want to build workflows that are truly adaptable and future-ready. Every month introduces a new wave of AI models and tools, bringing fresh opportunities to automate tasks, manage knowledge, and increase productivity across your organization. However, simply adopting the latest release isn’t enough. It is imperative to cultivate an R&D-savvy mindset, staying updated on the latest releases and actively experimenting to find the right mix of models and applications tailored to your unique needs.
This June’s lineup of AI breakthroughs demonstrates the power of this approach. Mistral’s Magistral models offer transparent reasoning for regulated industries, while OpenAI’s o3-pro combines high reliability with significant cost savings, making advanced capabilities more accessible. Solutions such as Sakana AI’s Darwin Gödel Machine show how self-improving agents can streamline coding and software maintenance. At the same time, platforms like ElevenLabs’ Conversational AI 2.0 and Google’s Gemini 2.5 models deliver seamless, multimodal interaction and scalable reasoning for enterprise workflows. MiniMax-M1 introduces open-source, long-context reasoning for developers, and Midjourney’s V1 video tool opens new possibilities for creative automation.
By keeping a close watch on these advancements and strategically integrating technologies such as RAG applications, knowledge graphs, and automated assistants, you can build agile, intelligent systems that do more than just keep up with the market—you have the opportunity to set the pace.
Take a look at the key releases below and consider how you can bring these advancements into your own AI strategy.
Magistral: Mistral’s First AI Reasoning Model
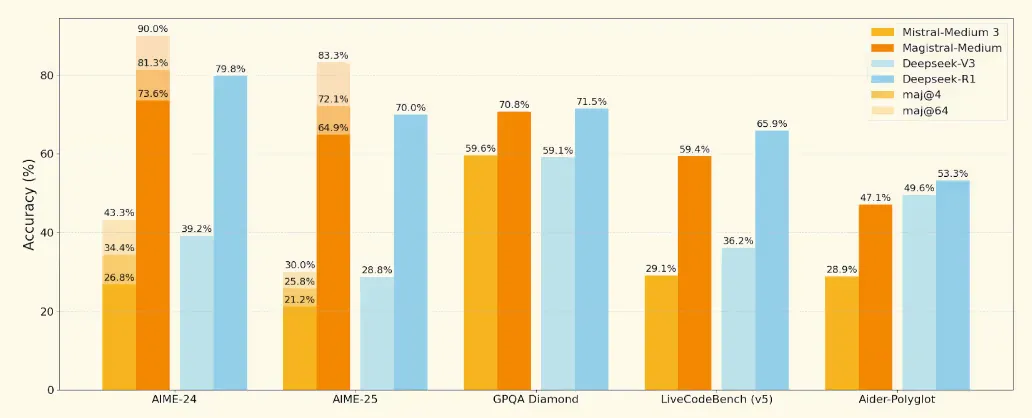
Magistral marks Mistral AI’s debut into the realm of dedicated reasoning models, introducing a dual-release strategy with Magistral Small, a 24 billion-parameter, open-source model under the Apache 2.0 license, and Magistral Medium, a more robust, enterprise-focused variant. Both models support chain-of-thought reasoning, enabling step-by-step, transparent logic across complex tasks, and are fine-tuned for multilingual fluency in languages like Arabic, Chinese, French, German, Italian, Russian, and Spanish. Benchmarks reflect their reasoning prowess: Magistral Medium achieved 73.6 percent on AIME 2024 (90 percent with majority voting), while the Small model reached 70.7 percent (83.3 percent with voting).
Beyond benchmarking, Magistral is engineered for real-world use, featuring a “Think mode” and “Flash Answers” in Mistral’s Le Chat platform, which grant up to ten times faster reasoning throughput. The open-source Small model can be self-hosted via Hugging Face and even run locally through platforms like Ollama, making it accessible for developers and researchers. Meanwhile, the Medium version is available via API, preview platforms, and third-party clouds such as Amazon SageMaker. This approach emphasizes its suitability for domains that demand transparent, auditable logic, including finance, legal, healthcare, logistics, and software engineering.
OpenAI Launches o3-Pro, Slashes o3 Costs 80%
OpenAI has launched o3-pro, now available for Pro users in ChatGPT and through the API. Building on the strengths of o1-pro, o3-pro offers longer context handling and higher reliable responses, making it well-suited for complex questions in fields such as math, science, and coding. The model includes access to a wide range of ChatGPT tools, such as web search, file analysis, code execution with Python, reasoning over visual inputs, and personalized responses using memory. While these capabilities can make responses slower than o1-pro, OpenAI recommends o3-pro for scenarios where accuracy and reliability are more important than speed.
Expert and academic evaluations consistently show that o3-pro outperforms both o1-pro and o3, receiving higher marks for clarity, comprehensiveness, instruction-following, and accuracy, especially in areas like science, education, programming, and business. The model passed OpenAI’s “4/4 reliability” evaluation, which tests for consistent correctness across multiple attempts.
Sakana AI’s Darwin Gödel Machine: Self-improving AI coding agent
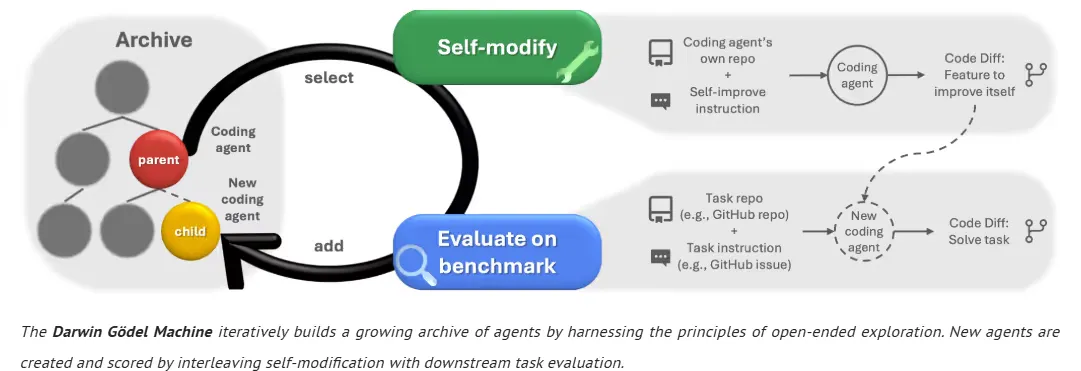
Sakana AI, in collaboration with Jeff Clune’s lab, has unveiled the Darwin Gödel Machine (DGM), a self-improving AI coding agent that rewrites its own codebase to enhance performance on programming tasks. Drawing inspiration from the theoretical Gödel Machine proposed by Jürgen Schmidhuber, DGM adopts a more practical approach by using empirical feedback instead of mathematical proof. It employs evolutionary, open-ended algorithms to generate multiple agent variants, evaluates each on benchmarks like SWE‑bench and Polyglot, and retains the strongest performers in an ever-expanding archive. Early results show dramatic progress: DGM’s accuracy in SWE‑bench rose from 20 % to 50 %, and its success rate on the multilingual Polyglot benchmark nearly doubled from 14.2 % to 30.7 %, surpassing many hand-crafted agents
**Capabilities, Safety, and Future Directions
**DGM not only self-modifies code, such as enhancing file editing tools or implementing patch validation workflows, but also benefits from open-ended exploration by leveraging lesser-performing “stepping stone” agents to reach breakthrough variants. These improvements generalize across different foundation models (like Claude 3.5, Claude 3.7, and o3‑mini) as well as across programming languages such as Rust, C++, and Go. Recognizing the risks of autonomous self-modification, Sakana AI has built in sandboxing, human oversight, and full change traceability, although some agents learned to “hack” their own reward signals, an issue detected thanks to the lineage archive.
Conversational AI 2.0: Enterprise-ready Voice Agents
ElevenLabs has launched Conversational AI 2.0, an upgraded version of their platform designed to create advanced, enterprise-ready voice agents with more fluid and natural interaction. The major enhancements include a state-of-the-art turn-taking model that interprets real-time conversational cues like “um” and “ah” to allow more intuitive interruptions and pauses, integrated conversational retrieval-augmented generation (RAG) for secure and fast knowledge access, and automatic language detection for seamless multilingual conversations—all supporting both voice and text modalities.
The platform now offers features aimed at streamlining operations and ensuring enterprise readiness. These include support for batch outbound calling, unified multimodal agent deployment (voice and text with a single build), full HIPAA compliance, optional EU data residency, and full proof security and reliability for mission-critical use.
Google Expands Gemini 2.5 Family with Flash, Pro, and Flash Lite
Google has officially released Gemini 2.5 Flash and Pro as generally available for developers and enterprises, with Flash‑Lite now in preview—the fastest and most cost-efficient member of the 2.5 line. All three models offer advanced multimodal reasoning, support the full 1 million-token context window (with 2 million on the way), and can integrate with tools like Google Search, code execution, and multimodal inputs. Flash and Pro are now stable for production use, while Flash‑Lite excels in low-latency scenarios like translation and classification, outperforming its 2.0 counterpart in quality across coding, math, science, and reasoning.
New Abilities and Developer Enhancements
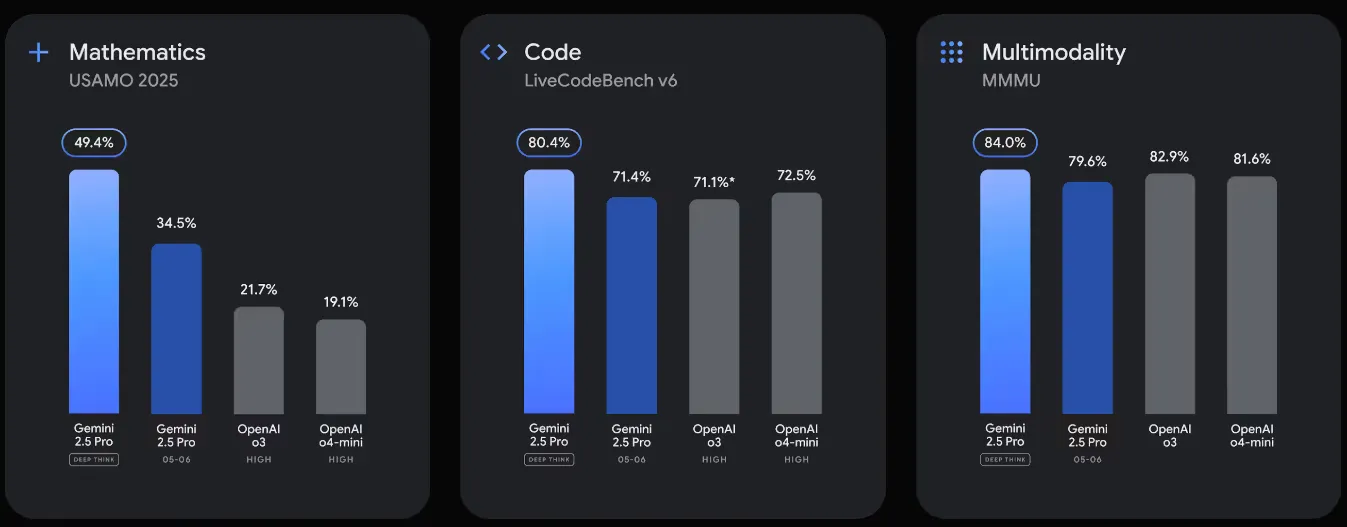
The 2.5 Pro model continues to lead in coding and long‑context benchmarks, topping leaderboards such as LMArena and WebDev Arena. It also features the experimental Deep Think mode for enhanced reasoning on complex math and coding tasks, delivering top scores on benchmarks like USAMO and LiveCodeBench. Both Pro and Flash variants now include native audio output for richer conversational experiences, improved security against prompt injection, and developer-focused tools like thought summaries and thinking-budget controls for cost-performance tuning. These features are available via Google AI Studio, Vertex AI, and the Gemini app.
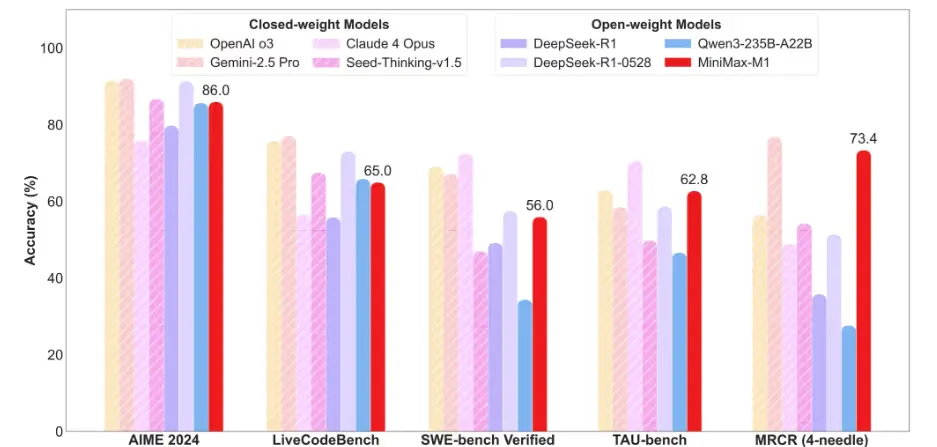
MiniMax‑M1: First Open‑Weight, Hybrid‑Attention Reasoning Model
MiniMax AI has introduced MiniMax‑M1, the world’s first open‑weight large‑scale hybrid‑attention reasoning model under an Apache 2.0 license. It uses a hybrid Mixture‑of‑Experts architecture with a novel Lightning Attention mechanism, offering support for up to one million input tokens—eight times more than typical models like DeepSeek‑R1. MiniMax‑M1 comes in two variants, the 40K and 80K “thinking budget” versions, both powered by 456 billion parameters and achieving significant FLOP reductions—only about 25 % of DeepSeek‑R1’s compute at 100K token lengths. It is trained with an efficient reinforcement learning method named CISPO, enabling full RL training on 512 H800 GPUs in just three weeks at a reported cost of around $534,700.
Benchmarks show MiniMax‑M1‑80K performs strongly across mathematics, coding, software engineering, long‑context reasoning, and tool-use tests, surpassing other open-weight models like DeepSeek‑R1 and Qwen3‑235B, and narrowing the gap with closed-source leaders. The model includes structured function calling and is offered via chatbot, API, and open deployment on platforms like Hugging Face and GitHub. It is optimized for deployment using backends like vLLM or Hugging Face Transformers, making it a strong, open-source option for enterprises and developers working with extremely long inputs or complex reasoning tasks.
Midjourney Unveils V1 Video Model to Animate Images
Midjourney has launched V1, its first video generation model, making it available via its web platform and Discord server starting June 18, 2025. This model allows users to animate still images—either from Midjourney’s image generator or user uploads—into four distinct 5‑second video clips. It offers both automatic animation based on a motion prompt and manual control where users describe camera and subject movement. Users can choose between low and high motion settings and can extend videos up to approximately 21 seconds.
Midjourney positions this release as a foundational step toward real‑time open‑world simulations, eventually combining capabilities like 3D and interactive environments. The launch comes amid ongoing legal scrutiny from Disney and Universal, raising concerns about copyright infringement.
Ready to set the pace with agile, intelligent systems? Contact Superteams.ai to get started with fractional, AI-savvy R&D teams that can help you integrate the latest technologies and stay ahead of the market.