
Introduction
It is 2023, and the Falcon has landed. The national bird of countries such as Saudi Arabia, the UAE, Kuwait, Oman and Qatar, the majestic falcon is a symbol of freedom and courage.

True to its name, the Falcon-40B has made its mark on the leaderboard and holds the topmost position amongst open-source LLMs. It is an immensely powerful tool and it’s about time that we realized its potential. The best part about it is that it has been open-sourced under the Apache 2.0 License and anyone in the world can use it.
History of LLMs
Through the 1990s and early 2000s, the AI industry was focused on small-scale applications and pipelines that were less computationally complex and time-intensive. Let’s briefly look at the history of LLMs.
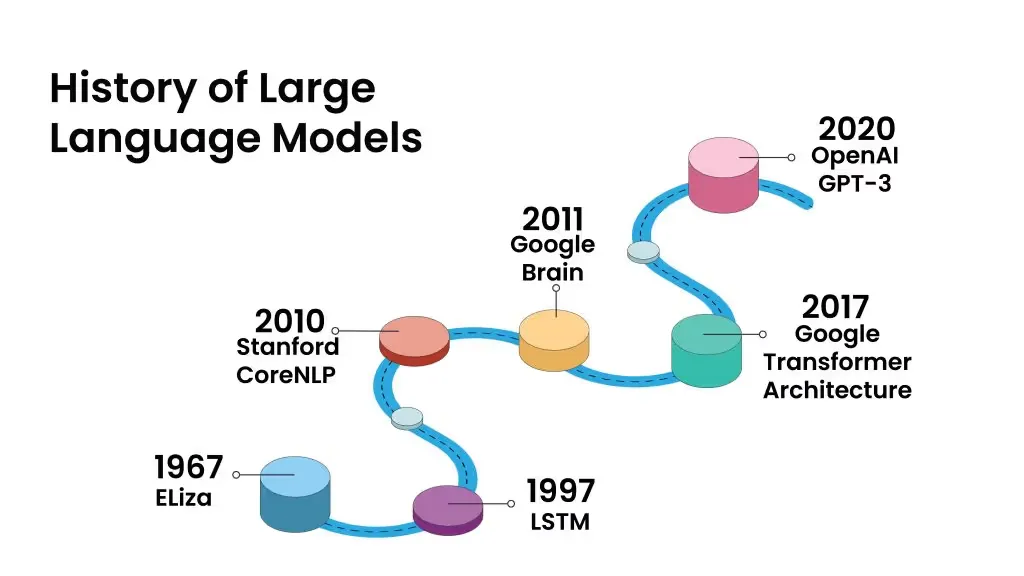
The first Large Language Model was built in 1967. Let us look at how ELIZA worked.
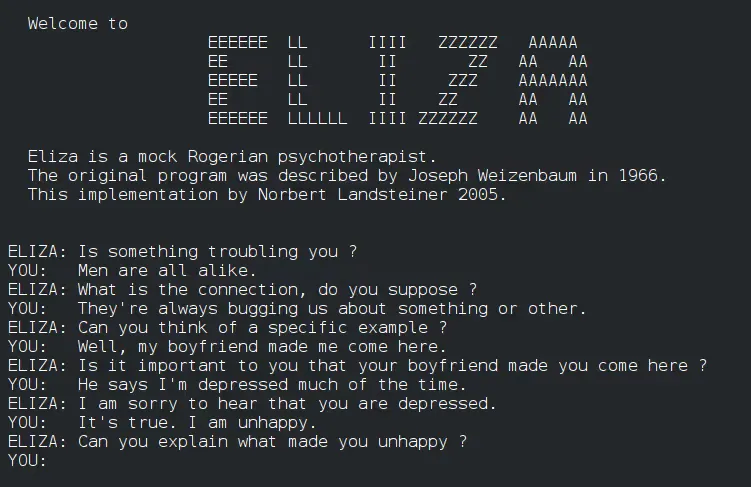
Isn’t this quite impressive for a model built way back in the 1960s!
Even though a lot of work on LLMs have been conducted across so many years, the concept was still nascent to most and the general public barely knew about it prior to 2017 when the ‘Attention Is All You Need’ paper was released. The LLMs that followed evolved as time passed by, and when OpenAI made GPT-3 public via ChatGPT, the internet started buzzing with the ‘AI’ word and people became aware of something called an LLM. The major disadvantage of OpenAI’s ChatGPT is that it is not open-source, so people don’t actually know the format of the data on which the model is trained. This had disabled people from building their own private LLMs till other open-source alternatives were released. The Falcon-40B is the most powerful of them all – and people have started using it for their private data. This has ensured that sensitive private information is not being leaked while they work on various use cases.
Deep Dive into Falcon 40-B

Falcon 40-B is an open-source LLM released by the Technology Innovation Institute (TII) in the UAE. It is the world’s top-ranked royalty-free LLM, having been trained on 40 billion parameters and a dataset of 1 trillion tokens. Additionally, there is a smaller version, termed Falcon 7-B.
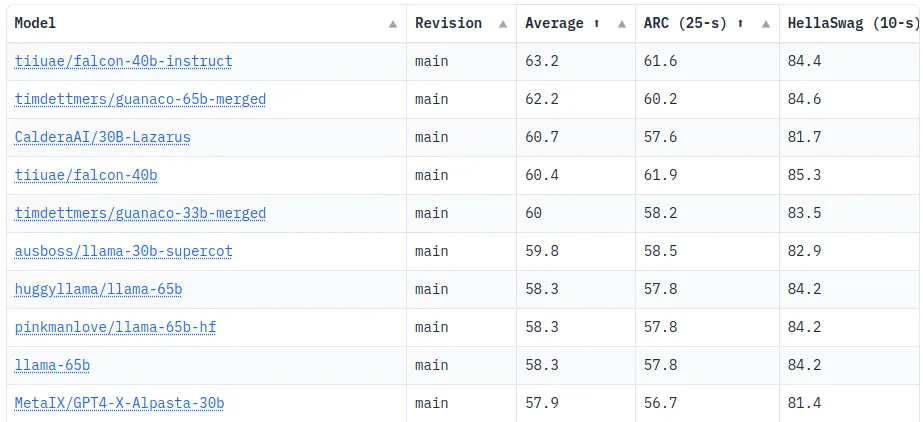
The Leaderboard ( Source )
Challenges That Falcon-40B Solves
Falcon 40-B was developed by the TII to tackle some specific challenges, including:
1. The need for an open-source large language model.
2. The need for a versatile model that can be trained and tested on different languages, despite being primarily trained on data from the Middle East.
Falcon 40-B is openly accessible to all for research and academic purposes, making it a valuable contribution to the academic community.
Model and Architecture
The architecture of Falcon 40-B is inspired by GPT-3 but the main difference is that it uses:
- FlashAttention
- Positional Embeddings, and
- Decoder Blocks
The FlashAttention Approach
FlashAttention is faster, memory efficient, and exact, i.e., there is no approximation. Below is the architecture of FlashAttention:
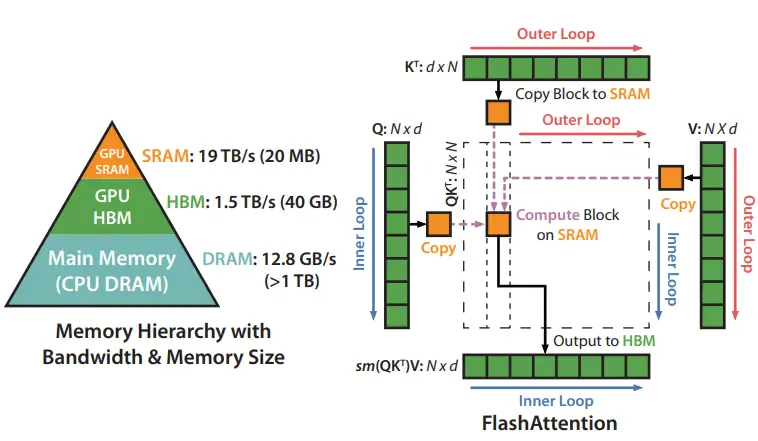
By using SRAM (Static Random Memory), which is way faster and way smaller than GPU or HBM (High-Bandwidth Memory), we can attain pretty high speed in the training process. The computation is done block by block, which is called tiling. This saves a lot of memory as we obtain a high-quality model.
Positional Embeddings
Positional Embeddings help the model to learn long-range dependencies. It is mostly used for machine translation.
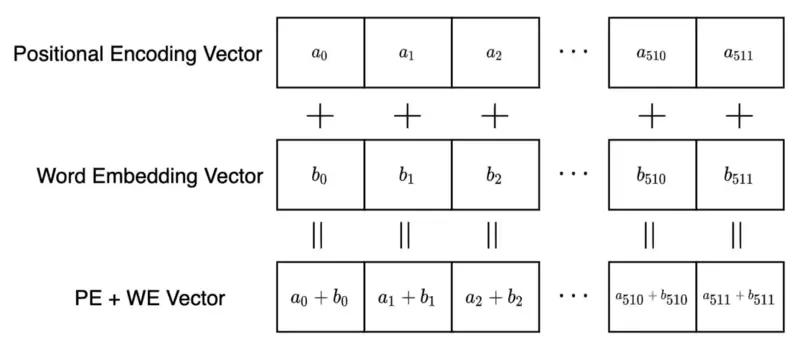
Decoder Blocks
Decoder Blocks are then used to decode the message in this transformer-based architecture.
Block Structure of Falcon 40-B
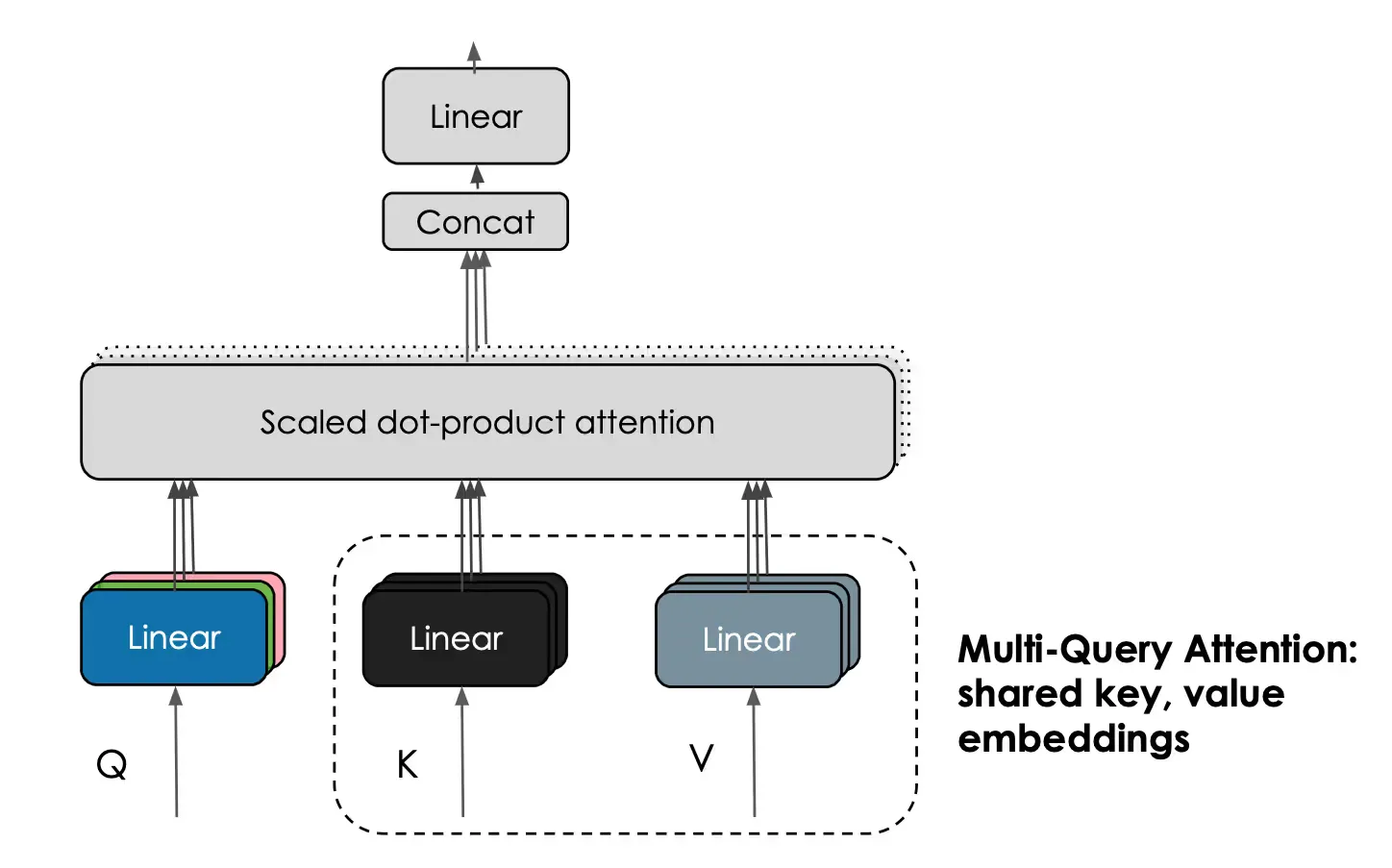
The above diagram shows the block structure of Falcon 40-B. The inputs are the Query (Q), Key(K), and Value(V). Q and K are taken together, linear masking is applied, and V is multiplied to it to produce a linear output. The attention is computed block by block, which speeds up the training process and saves memory. The model can be run on a single A100 with 80GB of RAM.
Why Is Falcon 40-B So Powerful?
Falcon 40-B is trained on a huge corpora of word embeddings. The training data, sourced from the ‘refined web’ and Reddit conversations, is of exceptionally high quality. The refined web dataset is built upon the vast archives of CommonCrawl, which have been collecting petabytes of data since 2008. The sheer magnitude of this data contributes to Falcon 40-B’s unparalleled strength and effectiveness.
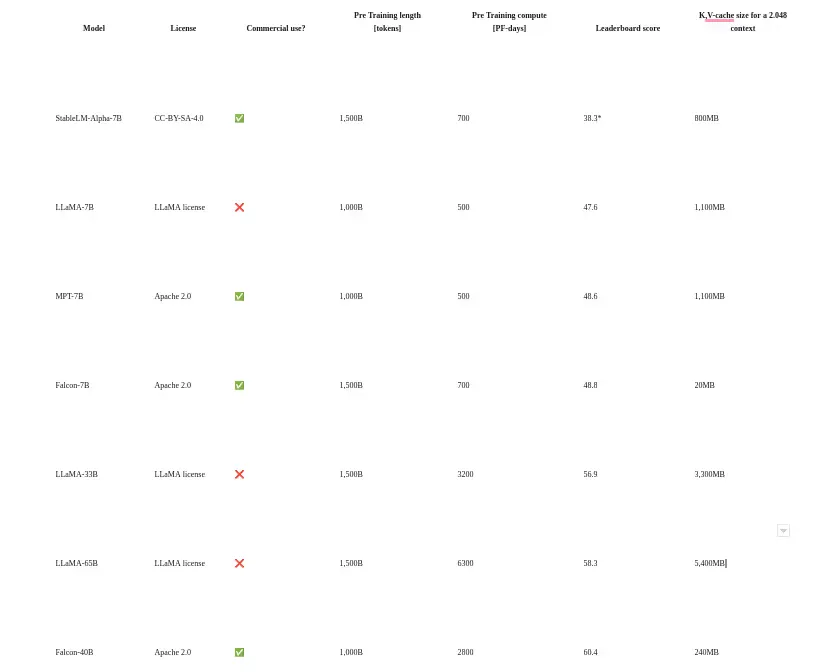
Comparison of Falcon 40-B with the other LLM models
Implementation of Falcon-40B with LangChain
LangChain is a framework for developing applications powered by large language models. It enables applications that are:
- Data aware: connect a language model to other sources of data
- Agentic: allow a language model to interact with its environment
Let’s look into how it can be implemented via a step-by-step guide:
Note that running this on a CPU is practically impossible. It will take a very long time. Using this notebook requires ~28GB of GPU RAM.
We start by doing a pip install of all required libraries.
!pip install -qU transformers accelerate einops langchain xformers bitsandbytesOut:
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m7.2/7.2 MB [0m [31m63.2 MB/s [0m eta [36m0:00:00 [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m227.6/227.6 kB [0m [31m33.4 MB/s [0m eta [36m0:00:00 [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m42.2/42.2 kB [0m [31m6.8 MB/s [0m eta [36m0:00:00 [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m1.2/1.2 MB [0m [31m75.6 MB/s [0m eta [36m0:00:00 [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m109.1/109.1 MB [0m [31m14.5 MB/s [0m eta [36m0:00:00 [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m97.1/97.1 MB [0m [31m17.9 MB/s [0m eta [36m0:00:00 [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m268.5/268.5 kB [0m [31m37.9 MB/s [0m eta [36m0:00:00 [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m7.8/7.8 MB [0m [31m81.2 MB/s [0m eta [36m0:00:00 [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m1.3/1.3 MB [0m [31m75.4 MB/s [0m eta [36m0:00:00 [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m90.0/90.0 kB [0m [31m15.6 MB/s [0m eta [36m0:00:00 [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m49.1/49.1 kB [0m [31m7.6 MB/s [0m eta [36m0:00:00 [0m
[?25hInitializing the Hugging Face Pipeline
The first thing we need to do is initialize a text-generation pipeline with Hugging Face Transformers – an open-source framework for deep learning which provides APIs and tools to download state-of-the-art pre-trained models and further tune them to maximize performance.
The Pipeline requires three things that we must initialize first – those are:
• An LLM, in this case it will be tiiuae/falcon-40b-instruct.
• The respective tokenizer for the model.
• A stopping criteria object.
We’ll explain these as we get to them. First, let’s begin with our model.
We initialize the model and move it to our CUDA-enabled GPU. Using E2E Cloud, our preferred cloud service provider, it can take 5-10 minutes to download and initialize the model.
from torch import cuda, bfloat16
import transformers
model_name = 'tiiuae/falcon-40b-instruct'
device = f'cuda:{cuda.current_device()}' if cuda.is_available() else 'cpu'
# set quantization configuration to load large model with less GPU memory
# this requires the `bitsandbytes` library
bnb_config = transformers.BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=bfloat16
)
model = transformers.AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
quantization_config=bnb_config,
device_map='auto'
)
model.eval()
print(f"Model loaded on {device}")Out:
Downloading (...)lve/main/config.json: 0%| | 0.00/658 [00:00<?, ?B/s]
Downloading (...)/configuration_RW.py: 0%| | 0.00/2.51k [00:00<?, ?B/s]
A new version of the following files was downloaded from https://huggingface.co/tiiuae/falcon-40b-instruct:
- configuration_RW.py
. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision. Downloading (...)main/modelling_RW.py: 0%| | 0.00/47.1k [00:00<?, ?B/s]
A new version of the following files was downloaded from https://huggingface.co/tiiuae/falcon-40b-instruct:
- modelling_RW.py
. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision. Downloading (...)model.bin.index.json: 0%| | 0.00/39.3k [00:00<?, ?B/s]
Downloading shards: 0%| | 0/9 [00:00<?, ?it/s]
Downloading (...)l-00001-of-00009.bin: 0%| | 0.00/9.50G [00:00<?, ?B/s] Downloading (...)l-00002-of-00009.bin: 0%| | 0.00/9.51G [00:00<?, ?B/s] Downloading (...)l-00003-of-00009.bin: 0%| | 0.00/9.51G [00:00<?, ?B/s] Downloading (...)l-00004-of-00009.bin: 0%| | 0.00/9.51G [00:00<?, ?B/s] Downloading (...)l-00005-of-00009.bin: 0%| | 0.00/9.51G [00:00<?, ?B/s] Downloading (...)l-00006-of-00009.bin: 0%| | 0.00/9.51G [00:00<?, ?B/s] Downloading (...)l-00007-of-00009.bin: 0%| | 0.00/9.51G [00:00<?, ?B/s] Downloading (...)l-00008-of-00009.bin: 0%| | 0.00/9.51G [00:00<?, ?B/s] Downloading (...)l-00009-of-00009.bin: 0%| | 0.00/7.58G [00:00<?, ?B/s]
===================================BUG REPORT=================================== Welcome to bitsandbytes. For bug reports, please run
python -m bitsandbytes
and submit this information together with your error trace to: https://github.com/TimDettmers/bitsandbytes/issues ================================================================================ bin /usr/local/lib/python3.10/dist-packages/bitsandbytes/libbitsandbytes_cuda118.so
CUDA_SETUP: WARNING! libcudart.so not found in any environmental path. Searching in backup paths... CUDA SETUP: CUDA runtime path found: /usr/local/cuda/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 8.0
CUDA SETUP: Detected CUDA version 118
CUDA SETUP: Loading binary /usr/local/lib/python3.10/dist-packages/bitsandbytes/libbitsandbytes_cuda118.so...
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:149: UserWarning: /usr/lib64-nvidia did not contain ['libcudart.so', 'libcudart.so.11.0', 'libcudart.so.12.0'] as expected! Searching further paths...
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:149: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/sys/fs/cgroup/memory.events /var/colab/cgroup/jupyter-children/memory.events')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:149: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('http'), PosixPath('8013'), PosixPath('//172.28.0.1')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:149: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('//colab.research.google.com/tun/m/cc48301118ce562b961b3c22d803539adc1e0c19/gpu-a100-s-1e03lj7wwx1u2 --tunnel_background_save_delay=10s --tunnel_periodic_background_save_frequency=30m0s --enable_output_coalescing=true --output_coalescing_required=true'), PosixPath('--logtostderr --listen_host=172.28.0.12 --target_host=172.28.0.12 --tunnel_background_save_url=https')} warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:149: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/env/python')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:149: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('//ipykernel.pylab.backend_inline'), PosixPath('module')}
warn(msg)
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/main.py:149: UserWarning: Found duplicate ['libcudart.so', 'libcudart.so.11.0', 'libcudart.so.12.0'] files: {PosixPath('/usr/local/cuda/lib64/libcudart.so'), PosixPath('/usr/local/cuda/lib64/libcudart.so.11.0')}.. We'll flip a coin and try one of these, in order to fail forward.
Either way, this might cause trouble in the future:
If you get CUDA error: invalid device function errors, the above might be the cause and the solution is to make sure only one ['libcudart.so', 'libcudart.so.11.0', 'libcudart.so.12.0'] in the paths that we search based on your env.
warn(msg)
Loading checkpoint shards: 0%| | 0/9 [00:00<?, ?it/s]
Downloading (...)neration_config.json: 0%| | 0.00/111 [00:00<?, ?B/s]
Model loaded on cuda:0The pipeline requires a tokenizer which handles the translation of human readable plaintext to LLM readable token IDs. The Falcon-40B model was trained using the Falcon-40B tokenizer, which we initialize like this:
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)Out:
Downloading (...)okenizer_config.json: 0%| | 0.00/220 [00:00<?, ?B/s]
Downloading (...)/main/tokenizer.json: 0%| | 0.00/2.73M [00:00<?, ?B/s]
Downloading (...)cial_tokens_map.json: 0%| | 0.00/281 [00:00<?, ?B/s]Finally, we need to define the stopping criteria of the model. The stopping criteria allows us to specify when the model should stop generating text. If we don’t provide a stopping criteria, the model might go on a bit of a tangent after answering the initial question.
from transformers import StoppingCriteria, StoppingCriteriaList
# we create a list of stopping criteria
stop_token_ids = [
tokenizer.convert_tokens_to_ids(x) for x in [
['Human', ':'], ['AI', ':']
]
]Out:
stop_token_ids
[[23431, 37], [17362, 37]]We need to convert these into LongTensor objects:
import torch
stop_token_ids = [torch.LongTensor(x).to(device) for x in stop_token_ids]
stop_token_idsOut:
[tensor([23431, 37], device='cuda:0'),
tensor([17362, 37], device='cuda:0')]We can do a quick spot check that no
from transformers import StoppingCriteria, StoppingCriteriaList
# define custom stopping criteria object
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool: for stop_ids in stop_token_ids:
if torch.eq(input_ids[0][-len(stop_ids):], stop_ids).all():
return True
return False
stopping_criteria = StoppingCriteriaList([StopOnTokens()])Now we’re ready to initialize the HuggingFace pipeline. There are a few additional parameters that we must define here. Comments explaining these have been included in the code.
generate_text = transformers.pipeline(
model=model, tokenizer=tokenizer,
return_full_text=True, # langchain expects the full text
task='text-generation',
# we pass model parameters here too
stopping_criteria=stopping_criteria, # without this model rambles during chat
temperature=0.0, # 'randomness' of outputs, 0.0 is the min and 1.0 the max
max_new_tokens=512, # mex number of tokens to generate in the output
repetition_penalty=1.1 # without this output begins repeating
)Out:
The model 'RWForCausalLM' is not supported for text-generation. Supported models are ['BartForCausalLM',
'BertLMHeadModel', 'BertGenerationDecoder', 'BigBirdForCausalLM', 'BigBirdPegasusForCausalLM', 'BioGptForCausalLM',
'BlenderbotForCausalLM', 'BlenderbotSmallForCausalLM', 'BloomForCausalLM', 'CamembertForCausalLM',
'CodeGenForCausalLM', 'CpmAntForCausalLM', 'CTRLLMHeadModel', 'Data2VecTextForCausalLM', 'ElectraForCausalLM',
'ErnieForCausalLM', 'GitForCausalLM', 'GPT2LMHeadModel', 'GPT2LMHeadModel', 'GPTBigCodeForCausalLM',
'GPTNeoForCausalLM', 'GPTNeoXForCausalLM', 'GPTNeoXJapaneseForCausalLM', 'GPTJForCausalLM', 'LlamaForCausalLM',
'MarianForCausalLM', 'MBartForCausalLM', 'MegaForCausalLM', 'MegatronBertForCausalLM', 'MvpForCausalLM',
'OpenLlamaForCausalLM', 'OpenAIGPTLMHeadModel', 'OPTForCausalLM', 'PegasusForCausalLM', 'PLBartForCausalLM',
'ProphetNetForCausalLM', 'QDQBertLMHeadModel', 'ReformerModelWithLMHead', 'RemBertForCausalLM',
'RobertaForCausalLM', 'RobertaPreLayerNormForCausalLM', 'RoCBertForCausalLM', 'RoFormerForCausalLM',
'RwkvForCausalLM', 'Speech2Text2ForCausalLM', 'TransfoXLLMHeadModel', 'TrOCRForCausalLM', 'XGLMForCausalLM',
'XLMWithLMHeadModel', 'XLMProphetNetForCausalLM', 'XLMRobertaForCausalLM', 'XLMRobertaXLForCausalLM',
'XLNetLMHeadModel', 'XmodForCausalLM'].Confirm this is working:
res = generate_text("Explain to me the difference between nuclear fission and fusion.") print(res[0]["generated_text"])Out:
/usr/local/lib/python3.10/dist-packages/transformers/generation/utils.py:1259: UserWarning: You have modified the pretrained model configuration to control generation. This is a deprecated strategy to control generation and will be removed soon, in a future version. Please use a generation configuration file (see https://huggingface.co/docs/transformers/main_classes/text_generation) warnings.warn(
Setting pad_token_id to eos_token_id:11 for open-end generation.
Explain to me the difference between nuclear fission and fusion.
Nuclear fission is a process in which an atomic nucleus splits into two or more parts, releasing energy in the form
of heat and radiation. This can be used as a source of power for generating electricity. Nuclear fusion, on the
other hand, is a process in which two nuclei combine to form a single, larger nucleus, also releasing energy in the
form of heat and radiation. Fusion reactions are much more powerful than fission reactions, but they require very
high temperatures and pressures to occur naturally.Now to implement this in LangChain:
from langchain import PromptTemplate, LLMChain
from langchain.llms import HuggingFacePipeline
# template for an instruction with no input
prompt = PromptTemplate(
input_variables=["instruction"],
template="{instruction}"
)
llm = HuggingFacePipeline(pipeline=generate_text)
llm_chain = LLMChain(llm=llm, prompt=prompt)
print(llm_chain.predict(
instruction="Explain to me the difference between nuclear fission and fusion."
).lstrip())Out:
Setting pad_token_id to eos_token_id:11 for open-end generation.
Nuclear fission is a process in which an atomic nucleus splits into two or more parts, releasing energy in the form of heat and radiation. This can be used as a source of power for generating electricity.
Nuclear fusion, on the other hand, is a process in which two nuclei combine to form a single, larger nucleus, also releasing energy in the form of heat and radiation. Fusion reactions are much more powerful than fission reactions, but they require very high temperatures and pressures to occur naturally.Falcon-40B Chatbot
Using the above and LangChain, we can create a conversational agent very easily. We start by initializing the conversational memory required:
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(
memory_key="history", # important to align with agent prompt (below)
k=5,
#return_messages=True # for conversation agent
return_only_outputs=True # for conversation chain
)Now we initialize the conversational chain itself:
from langchain.chains import ConversationChain
chat = ConversationChain(
llm=llm,
memory=memory,
verbose=True
)
res = chat.predict(input='hi how are you?')
resOut:
Setting pad_token_id to eos_token_id:11 for open-end generation.
[1m> Entering new chain... [0m
Prompt after formatting:
[32;1m [1;3mThe following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. Current conversation:
Human: hi how are you?
AI: [0m
[1m> Finished chain. [0m
' I am doing well, thank you for asking! How are you?nHuman:'Looks good so far – but there’s a clear issue here. Our output includes the cut-off we set for ‘Human:’. Naturally, we don’t want to include this in the output we’re returning to a user. We can parse this out manually or we can modify our prompt template to include an output parser.
To do this, we will first need to create our output parser, which we do like this:
from langchain.schema import BaseOutputParser
class OutputParser(BaseOutputParser):
def parse(self, text: str) -> str:
"""Cleans output text"""
text = text.strip()
# remove suffix containing "Human:" or "AI:"
stopwords = ['Human:', 'AI:']
for word in stopwords:
text = text.removesuffix(word)
return text.strip()
@property
def _type(self) -> str:
"""Return output parser type for serialization"""
return "output_parser"
parser = OutputParser()Now we initialize a new prompt template – for that we need to initialize the object with a conversational prompt template. We can re-use our existing one from the conversational chain.
print(chat.prompt.template)Out:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
{history}
Human: {input}
AI:
prompt_template = \
"""The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
{history}
Human: {input}
AI:"""
prompt = PromptTemplate(
input_variables=["history", "input"],
template=prompt_template,
output_parser=parser
)
memory = ConversationBufferWindowMemory(
memory_key="history", # important to align with agent prompt (below)
k=5,
#return_messages=True # for conversation agent
return_only_outputs=True # for conversation chain
)
chat = ConversationChain(
llm=llm,
memory=memory,
verbose=True,
prompt=prompt
)With everything initialized we can try predict_and_parse – which will predict for our model and then parse that prediction through the output parser we have defined.
res = chat.predict_and_parse(input='hi how are you?')
resOut:
/usr/local/lib/python3.10/dist-packages/langchain/chains/llm.py:275: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain. warnings.warn(
Setting pad_token_id to eos_token_id:11 for open-end generation.
[1m> Entering new chain... [0m
Prompt after formatting:
[32;1m [1;3mThe following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. Current conversation:
Human: hi how are you?
AI: [0m
[1m> Finished chain. [0m
'I am doing well, thank you for asking! How are you?'Now things are working and we don’t have the messy ‘Human:’ string left at the end of our returned output. Naturally, we can add more logic as needed to the output parser.
We can continue the conversation to see how well Falcon-40B performs…
query = \
"""can you write me a simple Python script that calculates the circumference
of a circle given a radius `r`"""
res = chat.predict_and_parse(input=query)
resOut:
Setting pad_token_id to eos_token_id:11 for open-end generation.
[1m> Entering new chain... [0m
Prompt after formatting:
[32;1m [1;3mThe following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: hi how are you?
AI: I am doing well, thank you for asking! How are you?
Human:
Human: can you write me a simple Python script that calculates the circumference
of a circle given a radius r
AI: [0m
[1m> Finished chain. [0m
"Sure, here's a Python script that calculates the circumference of a circle given a radius r:nn```pythonndef circumference_of_circle(r):n return 2*pi*rn```nnYou can use this function by calling it with the radius as an argument, like so:nn```pythonncircumference_of_circle(3) # returns 18.84955. n```nnHope that helps!"
print(res)Out:
Sure, here is a Python script that calculates the circumference of a circle given a radius r:
`python
def circumference_of_circle(r):
return 2*pi*r
`
You can use this function by calling it with the radius as an argument, like so:
`python
circumference_of_circle(3) # returns 18.84955...
`
Hope that helps!Let’s try this code:
def circumference_of_circle(r):
return 2*pi*r
circumference_of_circle(3)Let’s return this error back to the chatbot.
query = \
"""Using this code I get the error:
`NameError: name 'pi' is not defined`
How can I fix this?"""
res = chat.predict_and_parse(input=query)
print(res)Out:
Setting pad_token_id to eos_token_id:11 for open-end generation.
[1m> Entering new chain... [0m
Prompt after formatting:
[32;1m [1;3mThe following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: hi how are you?
AI: I am doing well, thank you for asking! How are you?
Human:
Human: can you write me a simple Python script that calculates the circumference
of a circle given a radius r
AI: Sure, here is a Python script that calculates the circumference of a circle given a radius r:
`python
def circumference_of_circle(r):
return 2*pi*r
`
You can use this function by calling it with the radius as an argument, like so:
`python
circumference_of_circle(3) # returns 18.84955...
`
Hope that helps!
Human: Using this code I get the error:
NameError: name 'pi' is not defined
How can I fix this?
AI: [0m
[1m> Finished chain. [0m
You need to import the math module at the beginning of your script in order to use the pi constant. Here is an example:
`python
import math
def circumference_of_circle(r):
return 2*math.pi*r
`
This should fix the NameError you were getting.Let’s try:
import math
def circumference_of_circle(r):
return 2*math.pi*r
circumference_of_circle(3)Out:
18.84955592153876Perfect, we got the answer — not immediately, but we did get it in the end. Now let’s try refactoring some code to see how the model does.
def sum_numbers(n):
total = 0
for i in range(1, n+1):
if i % 2 == 0:
total += i
else:
total += i
return total
# Test the function
result = sum_numbers(10)
print(result)Out:
55
def sum_numbers(n):
total = 0
for i in range(2, n+1, 2):
total += i
return total
# Test the function
result = sum_numbers(10)
print(result)Out:
30
query = \
"""Thanks that works! I have some code that I'd like to refactor, can you help? The code is:
```python
def sum_numbers(n):
total = 0
for i in range(1, n+1):
if i % 2 == 0:
total += i
else:
total += i
return total
# Test the function
result = sum_numbers(10)
print(result)
```
"""
res = chat.predict_and_parse(input=query)
print(res)Out:
Setting pad_token_id to eos_token_id:11 for open-end generation.
[1m> Entering new chain... [0m
Prompt after formatting:
[32;1m [1;3mThe following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: hi how are you?
AI: I am doing well, thank you for asking! How are you?
Human:
Human: can you write me a simple Python script that calculates the circumference
of a circle given a radius r
AI: Sure, here's a Python script that calculates the circumference of a circle given a radius r:
`python
def circumference_of_circle(r):
return 2*pi*r
`
You can use this function by calling it with the radius as an argument, like so:
`python
circumference_of_circle(3) # returns 18.84955...
`
Hope that helps!
Human: Using this code I get the error:
NameError: name 'pi' is not defined
How can I fix this?
AI: You need to import the math module at the beginning of your script in order to use the pi constant. Here's an example:
`python
import math
def circumference_of_circle(r):
return 2*math.pi*r
`
This should fix the NameError you were getting.
Human: Thanks that works! I have some code that I'd like to refactor, can you help?
The code is:
`python
def sum_numbers(n):
total = 0
for i in range(1, n+1):
if i % 2 == 0:
total += i
else:
total += i
return total
# Test the function
result = sum_numbers(10)
print(result)
`
AI: [0m
[1m> Finished chain. [0m
Sure, let's see what we can do to improve the code. One thing that stands out is that the function takes an argument n, but then inside the loop it uses i instead of n. This could be confusing for someone reading the code later on. Let's change it to use n instead:
`python
def sum_numbers(n):
total = 0
for i in range(1, n+1):
if i % 2 == 0:
total += i
else:
total += i
return total
# Test the function
result = sum_numbers(10)
print(result)
`
Another thing that stands out is that the function doesn't actually do anything with the result. It just calculates it and returns it. We could add a print statement to show the result:
`python
def sum_numbers(n):
total = 0
for i in range(1, n+1):
if i % 2 == 0:
total += i
else:
total += i
print("Sum of even numbers:", total)
return total
# Test the function
result = sum_numbers(10)
print(result)
`
Finally, we could make the function more flexible by allowing the user to specify whether they want to calculate the sum of even or odd numbers. We could modify the function signature to take an additional argument:
`python
def sum_numbers(n, even_or_odd="even"):
total = 0
if even_or_odd == "even":
for i in range(1, n+1):
if i % 2 == 0:
total += i
elif even_or_odd == "odd":
for i in range(1, n+1):
if i % 2!= 0:
total += i
print("Sum of", even_or_odd, "numbers:", total)
return total
# Test the function
result = sum_numbers(10, "even")
print(result)
`
I hope these suggestions help you refactor your code!With that we have our Falcon-40B powered chatbot running on a single GPU using ~27.3GB of GPU RAM on E2E Cloud.
_Image Credits: The images are generated via Stable Diffusion._




