
The Relevance of Knowledge Graphs
Knowledge graphs possess the transformative power to organize and integrate information across various domains and sources, enabling a deeper understanding of complex relationships and interdependencies.
By representing data as nodes (entities) and edges (relationships), knowledge graphs facilitate semantic querying and advanced analytics, allowing for the extraction of insights that might otherwise remain hidden within unstructured data.
This capability is extremely valuable for a range of applications, from enhancing search engine results to driving personalized recommendations, and from improving artificial intelligence systems to enabling breakthroughs in scientific research. Knowledge graphs thus serve as a foundational technology for constructing a more interconnected and intelligent digital ecosystem, where data becomes not only more accessible but also more meaningful.

The Challenge of Creating Knowledge Graphs from Unstructured Data
Creating knowledge graphs from structured data is relatively straightforward because the data is already organized into defined formats, such as tables with rows and columns in relational databases, or objects in document-based stores. These formats lend themselves well to translation into nodes and edges, where entities and their attributes are clearly delineated, and relationships are explicitly stated or can easily be inferred.
However, constructing knowledge graphs from unstructured data presents a much greater challenge. Unstructured data, for e.g. text documents, lack a predefined data model, making the extraction of entities and relationships for the graph a complex task.
Indeed, there are very limited tools available for directly creating knowledge graphs from unstructured data, which makes the process challenging. This represents a significant barrier for many organizations, particularly those without the resources to invest in the necessary technology and talent to build and manage these complex systems.
We found a robust solution for converting unstructured data into a knowledge graph using an end-to-end AI model called REBEL.
How Rebel Works
REBEL is a text-to-text model developed by BabelScape through the fine-tuning of the BART model. It is designed to parse sentences that contain entities and implicit relationships, converting them into explicit relational triplets. Trained on over 200 distinct types of relations, REBEL’s training utilized a bespoke dataset drawn from the abstracts of Wikipedia and the relational data of Wikidata. This dataset was refined with the assistance of a RoBERTa-based Natural Language Inference model, ensuring the quality and relevance of the entities and relations included.
The dataset utilized for REBEL’s pre-training is accessible on the Hugging Face Hub, as detailed in the paper that outlines its development process. REBEL has demonstrated impressive performance across several benchmarks in both Relation Extraction and Relation Classification tasks.
For those interested in exploring or utilizing REBEL, the model is available on the Hugging Face Hub platform.
A Note on Neo4j’s Knowledge Graph
Neo4j is a highly regarded graph database platform that has been instrumental in the development and deployment of knowledge graphs. It is designed to store and retrieve data structured in graphs rather than tables, making it ideal for representing complex networks of data with interconnecting relationships.
Neo4j knowledge graphs enable organizations to uncover and leverage intricate connections in their data, allowing for powerful queries and analyses that traditional relational databases struggle with.
The platform offers a rich set of tools and features, including the Cypher query language, which is specifically tailored for graph operations. This makes it possible to intuitively model, query, and visualize relationships within the data. Neo4j’s knowledge graph capabilities are applied across various industries for use cases such as recommendation systems, fraud detection, artificial intelligence, and more, demonstrating its flexibility and robustness in handling connected data at scale.
In order to connect to a Neo4j instance, you can launch a DB on their Aura platform.
Upon launching a new instance, you can download a text file that will contain the username, password, and the URL of your database. This will be needed later to connect to the database.
Let’s Dive into the Code
First, install all the dependencies needed to execute the program.
pip install --upgrade --quiet langchain neo4j wikipedia transformers torchLet’s establish a connection with Neo4j’s graph db.
from langchain_community.graphs
import Neo4jGraph
url = "URL_TO_YOUR_DB"
username = "neo4j"
password = "YOUR_PASSWORD"
graph = Neo4jGraph(url=url, username=username, password=password)Let’s define a text splitter that will break our unstructured data into smaller chunks to be processed by the REBEL model.
from langchain.text_splitter
import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
length_function=len,
is_separator_regex=False,)Now let’s load the text that we would want to be inserted and organized into our knowledge graph. It would be interesting to see a knowledge graph of the very popular ‘Dune’ universe, as it is complex with many entities and subplots.
from langchain_community.document_loaders import WikipediaLoader
query = "Dune (Frank Herbert)"
raw_documents = WikipediaLoader(query=query).load_and_split(text_splitter=text_splitter)
[Document(page_content="Frank Herbert's Dune is a three-part science fiction television miniseries based on the 1965 novel by Frank Herbert. It was written and directed by John Harrison.
The cast includes Alec Newman as Paul Atreides, William Hurt as Duke Leto Atreides, and Saskia Reeves as Lady Jessica, as well as Ian McNeice as Baron Vladimir Harkonnen and Giancarlo Giannini as the Padishah Emperor Shaddam IV.", metadata={'title': "Frank Herbert's Dune", 'summary': "Frank Herbert's Dune is a three-part science fiction television miniseries based on the 1965 novel by Frank Herbert.
It was written and directed by John Harrison. The cast includes Alec Newman as Paul Atreides, William Hurt as Duke Leto Atreides, and Saskia Reeves as Lady Jessica, as well as Ian McNeice as Baron Vladimir Harkonnen and Giancarlo Giannini as the Padishah Emperor Shaddam IV.
\nThe miniseries was shot in Univisium (2.00:1) aspect ratio, although it was broadcast in 1.78:1. Frank Herbert's Dune was produced by New Amsterdam Entertainment, Blixa Film Produktion, and Victor Television Productions. It was first broadcast in the United States on December 3, 2000, on the Sci Fi Channel. It was released on DVD in 2001 by Artisan Entertainment, with an extended director's cut appearing in 2002.A 2003 sequel miniseries titled Frank Herbert's Children of Dune continues the story, adapting the second and third novels in the series (1969's Dune Messiah and its 1976 sequel Children of Dune). The miniseries are among the highest-rated programs ever to be broadcast on the Sci Fi Channel.
\nFrank Herbert's Dune won two Emmy Awards in 2001 for Outstanding Cinematography and Outstanding Special Visual Effects in a miniseries or movie, and was nominated for a third Emmy for Outstanding Sound Editing. The series was also praised by several critics, including Kim Newman.
\n\n", 'source': 'https://en.wikipedia.org/wiki/Frank_Herbert%27s_Dune'................Then we load the REBEL model.
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Babelscape/rebel-large")
model = AutoModelForSeq2SeqLM.from_pretrained("Babelscape/rebel-large")This helper function (available from the model’s Hugging Face page itself) takes the text and returns a triplet containing an entity pair and their relationship.
def extract_relations_from_model_output(text):
relations = []
relation, subject, relation, object_ = '', '', '', ''
text = text.strip()
current = 'x'
text_replaced = text.replace("<s>", "").replace("<pad>", "").replace("</s>", "")
for token in text_replaced.split():
if token == "<triplet>":
current = 't'
if relation != '':
relations.append({
'head': subject.strip(),
'type': relation.strip(),
'tail': object_.strip()
})
relation = ''
subject = ''
elif token == "<subj>":
current = 's'
if relation != '':
relations.append({
'head': subject.strip(),
'type': relation.strip(),
'tail': object_.strip()
})
object_ = ''
elif token == "<obj>":
current = 'o'
relation = ''
else:
if current == 't':
subject += ' ' + token
elif current == 's':
object_ += ' ' + token
elif current == 'o':
relation += ' ' + token
if subject != '' and relation != '' and object_ != '':
relations.append({
'head': subject.strip(),
'type': relation.strip(),
'tail': object_.strip()
})
return relationsWe shall also create a knowledge graph class to store information about the nodes and the edges.
class KB():
def __init__(self):
self.relations = []
def are_relations_equal(self, r1, r2):
return all(r1[attr] == r2[attr] for attr in ["head", "type", "tail"])
def exists_relation(self, r1):
return any(self.are_relations_equal(r1, r2) for r2 in self.relations)
def add_relation(self, r):
if not self.exists_relation(r):
self.relations.append(r)
def print(self):
print("Relations:")
for r in self.relations:
print(f" {r}")
Next, we wrap the above into a single function that takes text as input and returns the knowledge graph for that text.
def from_small_text_to_kb(text, verbose=False):
kb = KB()
# Tokenizer text
model_inputs = tokenizer(text, max_length=512, padding=True, truncation=True,return_tensors='pt')
if verbose:
print(f"Num tokens: {len(model_inputs['input_ids'][0])}")
# Generate
gen_kwargs = {
"max_length": 216,
"length_penalty": 0,
"num_beams": 3,
"num_return_sequences": 3
}
generated_tokens = model.generate(
**model_inputs,
**gen_kwargs,
)
decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=False)
# create kb
for sentence_pred in decoded_preds:
relations = extract_relations_from_model_output(sentence_pred)
for r in relations:
kb.add_relation(r)
return kbTo insert the Dune universe data into Neo4j’s graph, use the code below:
for doc in raw_documents:
kb = from_small_text_to_kb(doc.page_content, verbose=True)
for relation in kb.relations:
head = relation['head']
relationship = relation['type']
tail = relation['tail']
cypher = f"MERGE (h:`{head}`)" + f" MERGE (t:`{tail}`)" + f" MERGE (h)-[:`{relationship}`]->(t)"
print(cypher)
graph.query(cypher)
graph.refresh_schema()Now the knowledge graph has been populated. We can head over to Neo4j’s console to study our graph.
Neo4j’s Aura Console
To visualize the graph complete graph at once, we use this query:
MATCH (n)-[r]->(m) RETURN n, r, m;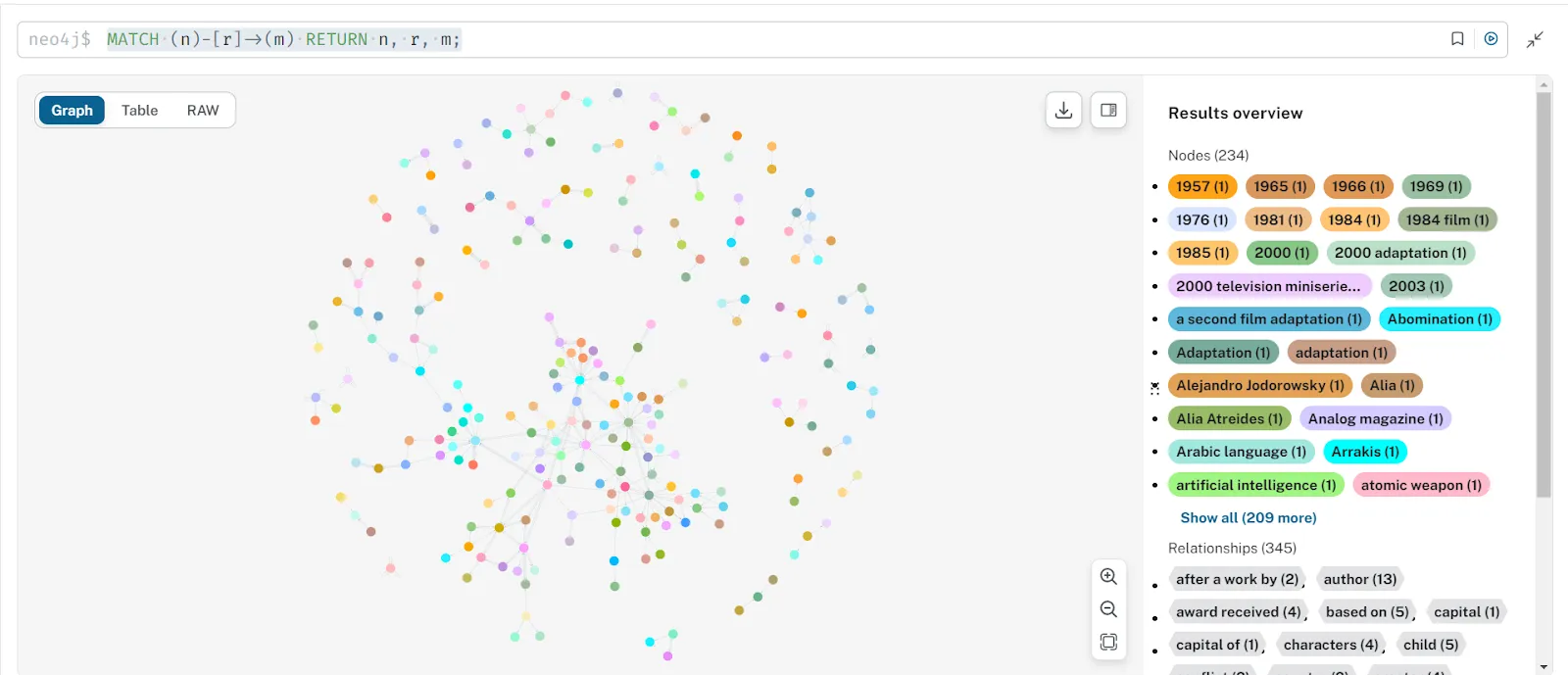
Let’s zoom into an area of the graph:
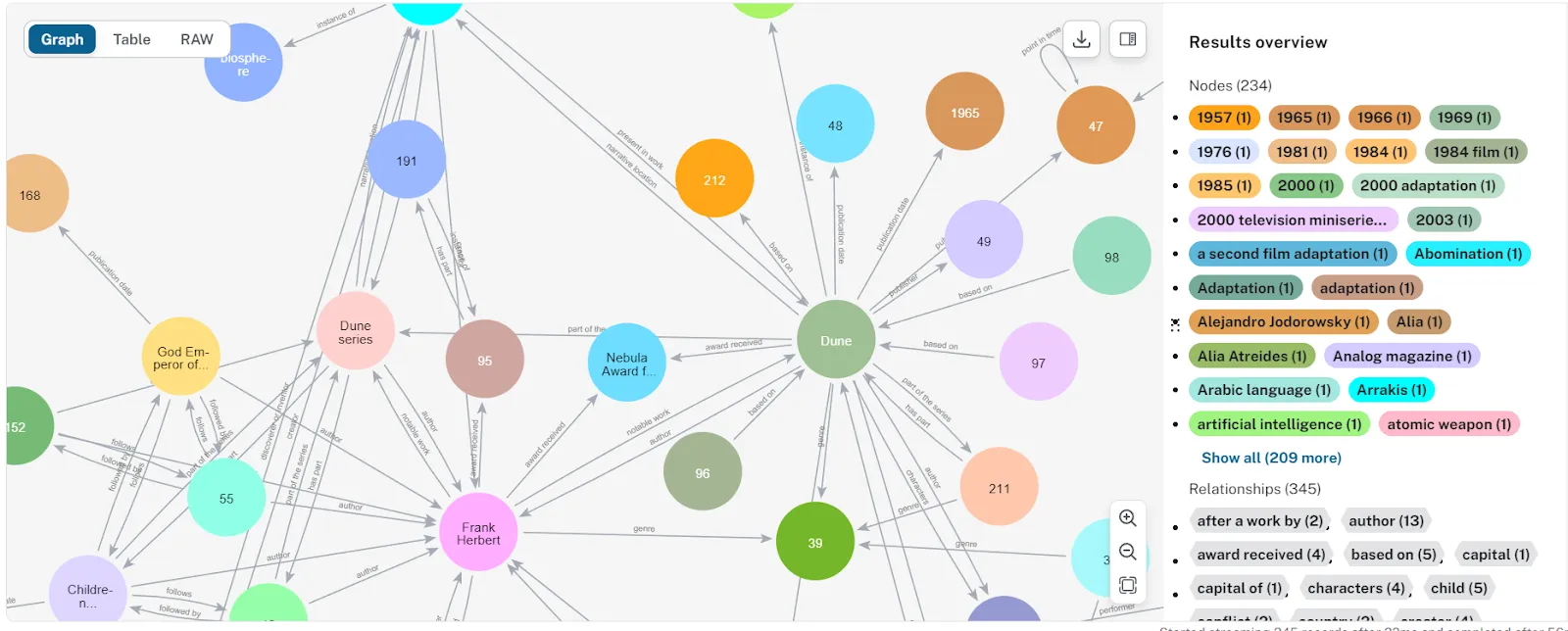
To view the name of the node instead of the id, we can click on Node on the right and change the caption to
To visualize a node and all the other nodes interconnected to it, we use the following query:
MATCH (n:`Dune`)-[p]-(q)
RETURN n, p, q;In this case, our center of interest is the `Dune` node.
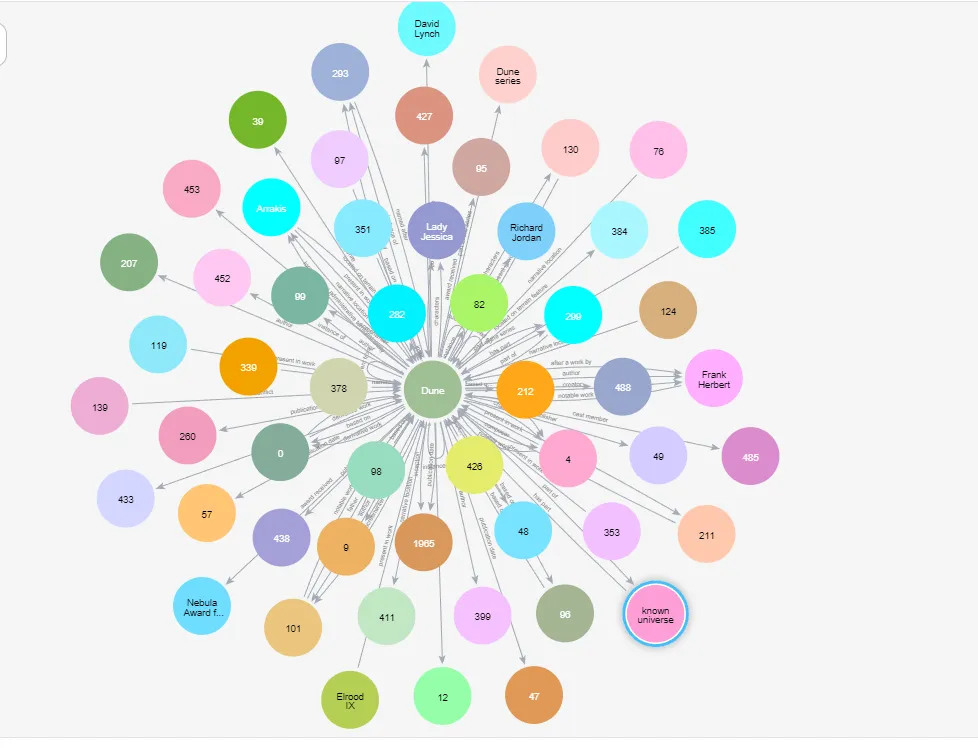
To list down all the director relationships:
MATCH p=()-[:director]->() RETURN p;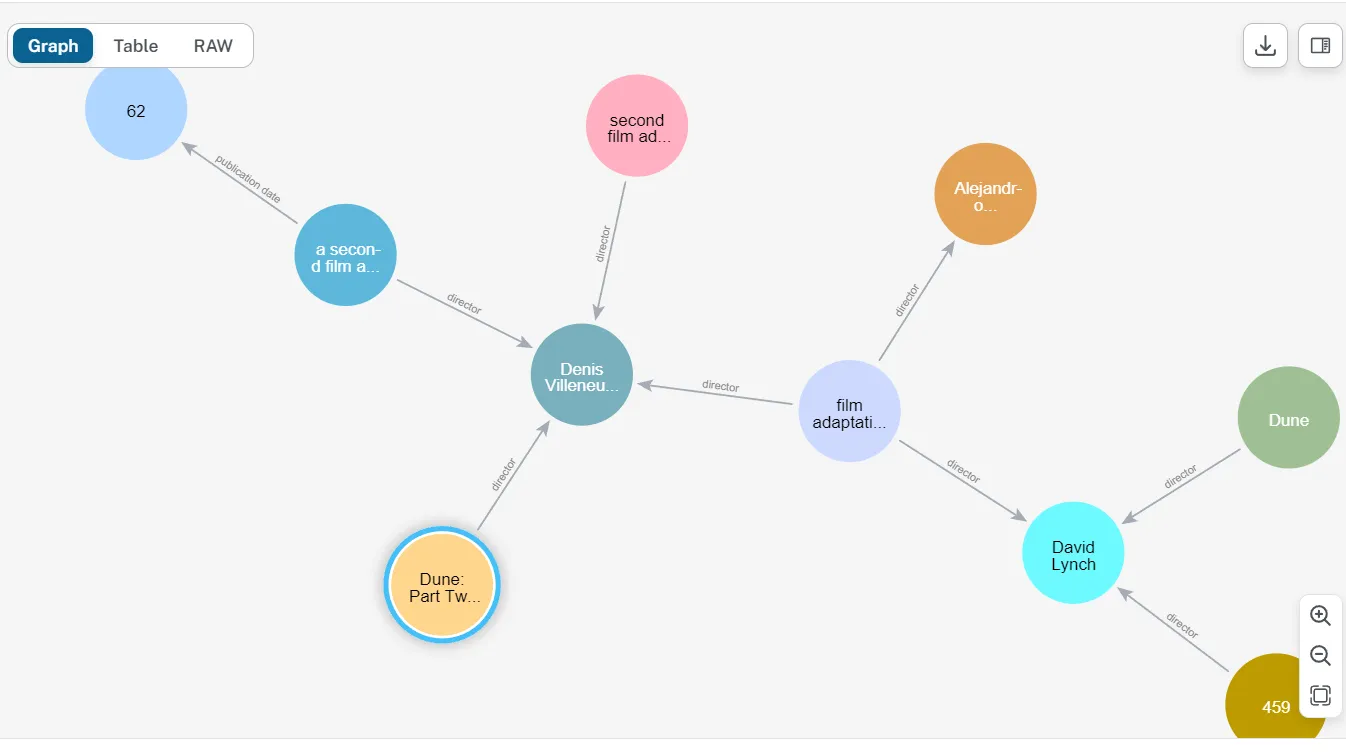
Similarly, if we want to view all the Father relationships of the characters in ‘Dune’:
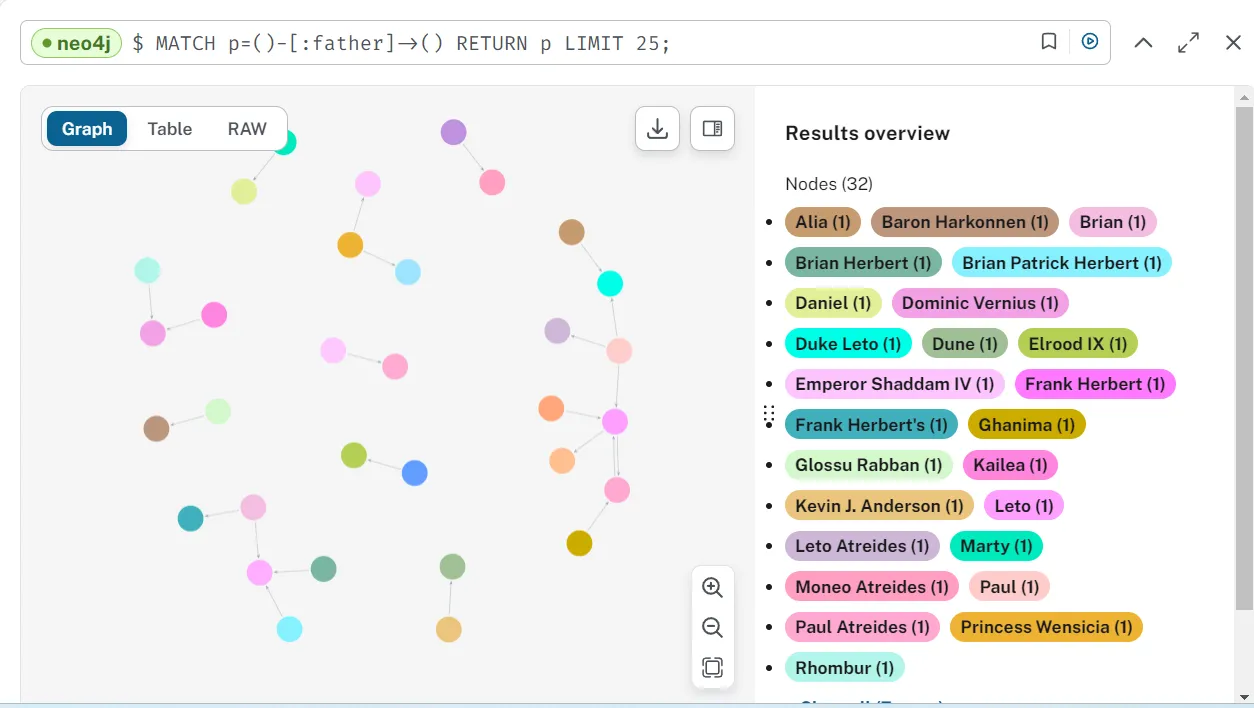
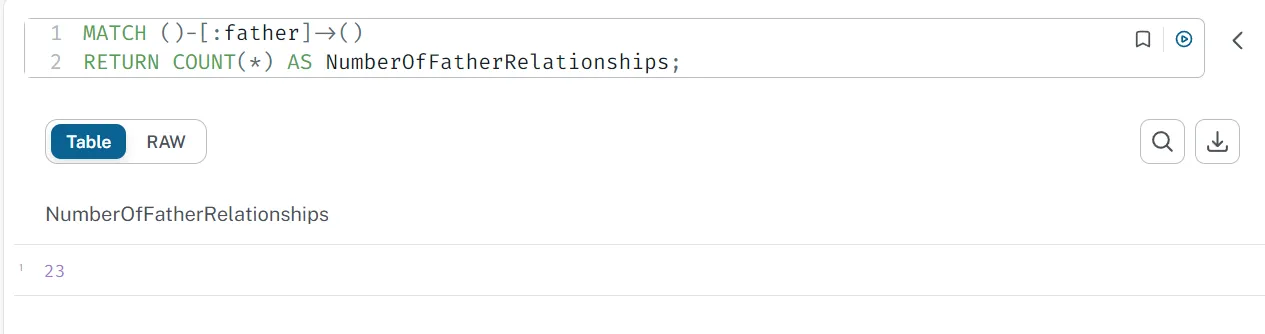
If we want to count the total number of Father relationships:
Conclusion
You are all set now to create a knowledge graph from your own unique dataset. As you can see from this blog, knowledge graphs are a powerful tool to visualize and study large datasets.
Feel free to reach out to [email protected] if you need any assistance in designing your AI workflows. We have some of the very best AI engineers working with us.
Hope you enjoyed reading this article.




-Feature-Image.CjBFdO7y_Z1bTNvg.webp)