
TL;DR
In this guide, we’ll learn how to:
- Set up vector storage and memory using PostgreSQL + pgvector
- Use Anthropic MCP to let your agent talk to tools and data sources
- Integrate Mistral models for high-quality reasoning
- Wire it all together into an autonomous, memory-powered agent loop
Introduction
Move over basic AI. Autonomous AI agents are here, and they’re changing everything.
AI agents are autonomous large language models that have built-in memory, tools, and decision-making abilities that reshape how we work with data and systems. They do more than just respond to queries; they understand context, search relevant information, reason over it, and take action across connected tools and data sources in real time. Unlike traditional LLMs that simply respond to prompts, agentic AI can remember, reason, and act—giving you a true digital co-worker, not just a chatbot.
In this guide, we’ll learn how to combine PostgreSQL + pgvector, Anthropic MCP, and Mistral (Medium) to build a simple yet powerful memory-augmented AI agent. We’ll understand how to set up vector storage for embeddings, orchestrate tool calls using MCP, and wire up everything into an agent loop that remembers past interactions and acts autonomously.
But, first, let’s understand the basics of AI agents and the architecture we’ll be using.
What Are AI Agents?
AI agents are autonomous systems that can understand, reason, and act on user input. They are designed to perform specific tasks like answering questions, retrieving data and making decisions by combining logic, data access, and AI models. In the context of databases, AI agents bridge the gap between natural language and structured data, enabling seamless interaction without manual querying.
Why MCP?
Anthropic’s Model Context Protocol (MCP), developed and maintained by Anthropic, acts as a universal connector between an AI agent and any tool, database, or external API you want it to use. This open protocol makes your agent highly extensible and future-proof. With MCP, an agent can securely query memory, fetch live data, or even trigger actions all through a standardized interface. This flexibility makes it easy to scale agent capabilities without hard-coding every integration from scratch.
Why Pgvector?
pgvector is an open-source extension that makes it easy to add powerful vector search capabilities directly inside PostgreSQL. Rather than setting up a separate vector store, you can keep embeddings right next to your structured data in the same database. This simplifies how you manage, query, and scale your agent’s memory, which helps in maintaining context and conversation history with minimal setup.
This tutorial is for developers and AI enthusiasts with some familiarity with Python and Docker.
Architecture and Setup
Architecture
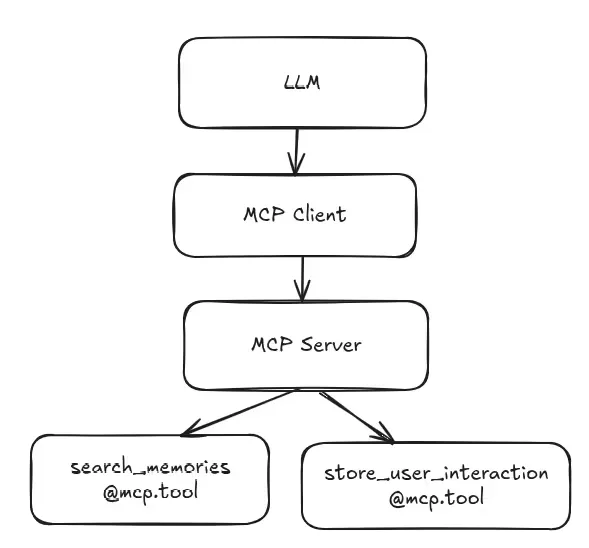
Fig: Architecture
Environment Setup
Prerequisites
Before starting, ensure you have the following:
PostgreSQL with the pgvector and pgai extensions installed. You can use a pre-built Docker container to launch PostgreSQL with these extensions by executing the following commands in your terminal:
$curl -O https://raw.githubusercontent.com/timescale/pgai/main/examples/docker_compose_pgai_ollama/docker-compose.yml
$docker compose up -d db
$docker compose run --rm --entrypoint "python -m pgai install -d postgres://postgres:postgres@db:5432/postgres" vectorizer-worker
$docker compose up -d
$docker compose exec -it db psqlSetting up the Vector Database
1. Enable Extensions: First, enable the pgai and pgvector extensions using the following commands in your SQL shells
CREATE EXTENSION IF NOT EXISTS ai CASCADE;
CREATE EXTENSION IF NOT EXISTS vector CASCADE;- Pull Ollama Models: Pull the Ollama models required for embeddings and routing:
docker compose exec ollama ollama pull nomic-embed-text
docker compose exec ollama ollama pull llama3.23. Connect to PostgreSQL: Open a SQL shell into the PostgreSQL container. If your setup requires an API key for integration or authentication, make sure it’s configured appropriately in your environment.
$docker compose up -d
$docker compose exec -it db psqlInstalling Anthropic MCP SDK (Python)
Install the tools and libraries required for building Agentic AI using:
$pip install psycopg2-binary loguru groq python-dotenv langchain-community mcp-use mcp[cli]Building a Simple Memory Agent
Groq Setup
You can use Groq’s API to access the Mistral SABA-24B model as follows:
from groq import Groq
client = Groq(api_key="YOUR_GROQ_API_KEY")
completion = client.chat.completions.create(
model="mistral-saba-24b",
messages=[
{
"role": "user",
"content": "hello who are you\n"
}
],
temperature=1,
max_completion_tokens=1024,
top_p=1,
stream=True,
stop=None,
)
for chunk in completion:
print(chunk.choices[0].delta.content or "", end="")Memory Layer
1. Schema: Embeddings + Metadata
CREATE TABLE memory (
id SERIAL PRIMARY KEY,
query TEXT NOT NULL,
response TEXT NOT NULL,
metadata JSONB NOT NULL,
full_text TEXT GENERATED ALWAYS AS (query || ' ' || response) STORED
);This creates a memory table that stores the user’s query, the assistant’s response, and any structured metadata (as JSON). The full_text column auto-combines the query and response for use in embeddings.
SELECT ai.create_vectorizer(
'memory'::regclass,
loading => ai.loading_column('full_text'),
embedding => ai.embedding_ollama('nomic-embed-text', 768),
destination => ai.destination_table('memory_embeddings')
);The ai.create_vectorizer call sets up automatic embedding generation and a separate memory_embeddings table for similarity search using pgvector and Ollama embeddings with the nomic-embed-text model.
2.Query Memory Function
This function connects to your PostgreSQL database and uses Ollama’s embedding to transform the user’s query into a vector. The vector is compared to existing memory_embeddings to find the top 3 most similar pieces of memory. These relevant chunks are then returned to provide helpful context for the LLM.
import psycopg
def query_memory_embeddings(user_query: str):
"""
Connects to PostgreSQL, embeds the user query using Ollama's pgvector extension,
and returns the top 3 closest chunks with their distance.
"""
conn = psycopg.connect("dbname=postgres user=postgres password=postgres host=localhost")
results = []
with conn.cursor() as cur:
cur.execute("""
SELECT
chunk,
embedding <=> ai.ollama_embed('nomic-embed-text', %s, host => 'http://ollama:11434') AS distance
FROM
memory_embeddings
ORDER BY
distance
LIMIT 3;
""", (user_query,))
results = cur.fetchall()
conn.close()
return results- Insert Memory Function
This function stores each query–response pair in the memory table along with metadata, such as the source of input and an automatic timestamp. Saving each interaction ensures that the agent builds a searchable memory for future queries.
import psycopg
import json
from datetime import datetime
def store_memory(query: str, response: str, source: str = "user"):
"""
Store a query-response pair with auto-generated metadata.
"""
conn = psycopg.connect(
"dbname=postgres user=postgres password=postgres host=localhost"
)
metadata = {
"source": source,
"timestamp": datetime.utcnow().isoformat() + "Z"
}
with conn.cursor() as cur:
cur.execute(
"INSERT INTO memory (query, response, metadata) VALUES (%s, %s, %s)",
(query, response, json.dumps(metadata))
)
conn.commit()
conn.close()
print("✅ Stored memory!")
3.Design Interaction Loop
This loop ties everything together. It accepts a user’s message, computes its embedding to retrieve the most relevant past memories, constructs an augmented prompt with this context, and sends it to Mistral via Groq. The assistant’s reply is streamed back and saved for future context.
from groq import Groq
def query_with_memory_and_groq(user_query: str):
chunks = query_memory_embeddings(user_query)
context = "\n".join([f"- {chunk[0]}" for chunk in chunks])
final_prompt = f"Relevant memory:\n{context}\n\nUser question:\n{user_query}"
print(final_prompt)
client = Groq(api_key="GROQ_API_KEY")
chat_completion = client.chat.completions.create(
model="mistral-saba-24b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": final_prompt}
])
return chat_completion.choices[0].message.content
query = input("You: ")
responce=query_with_memory_and_groq(query)
print(responce)
store_memory(query,responce)Integrating MCP
An Overview of MCP
**What is MCP?
**The Model Context Protocol (MCP) is an open protocol specification for connecting LLM-based agents to external tools, plugins, memory stores, or live data sources. It defines a standard way for tools to expose functions that an LLM can call during a conversation.
**Core Idea
**Instead of hard-coding all logic inside the LLM prompt, MCP lets you separate concerns: the LLM handles reasoning and language, while tools handle structured operations like database queries, web scraping, or vector search.
Protocol Flow
A typical MCP interaction follows this pattern:
- Initialization: Client connects to server and negotiates capabilities.
- Discovery: Client queries available resources, tools, and prompts.
- Interaction: Client requests resources or invokes tools as needed.
- Cleanup: Connection is properly closed when done.
Key Features
- Decouples memory and retrieval logic from the LLM.
- Supports multiple tools (vector search, keyword search, web APIs, SQL access, etc.).
- Compatible with any LLM framework—works with LangChain, Groq, OpenAI, Ollama, etc.
- Makes your agent modular and composable—you can plug in or swap tools without changing your main agent loop.
Common Use Cases
- Vector memory: Connect your LLM to a vector database (like Postgres + pgvector) for retrieval-augmented generation (RAG).
- Live knowledge: Query external APIs like Wikipedia, Google Search, or domain-specific data.
- Multi-agent workflows: Connect multiple agents that share a common memory or toolset.
Configuring the MCP Server
We’ll configure and run an MCP server using FastMCP. The server hosts tools like search_memories_simple and store_user_interaction. These tools handle vector search and storage in your Postgres memory table, so other agents or plugins can call them on demand.
- Initialize server
import psycopg2
import json
from datetime import datetime
from loguru import logger
from mcp.server.fastmcp import FastMCP
from psycopg2.extras import RealDictCursor
# Create an MCP server instance
mcp = FastMCP("Wiki_Memory_Enhanced_Postgres")
DB_CONFIG = {
"dbname": os.getenv("DB_NAME", "postgres"),
"user": os.getenv("DB_USER", "postgres"),
"password": os.getenv("DB_PASSWORD", "postgres"),
"host": os.getenv("DB_HOST", "localhost"),
"port": os.getenv("DB_PORT", "5432")
}
# Connection pool for better connection management
CONNECTION_POOL = None
POOL_LOCK = threading.Lock()
def initialize_connection_pool():
"""Initialize the connection pool."""
global CONNECTION_POOL
if CONNECTION_POOL is None:
with POOL_LOCK:
if CONNECTION_POOL is None:
try:
CONNECTION_POOL = SimpleConnectionPool(
1, 20, # min and max connections
**DB_CONFIG
)
logger.info("Database connection pool initialized successfully")
except Exception as e:
logger.error(f"Failed to initialize connection pool: {e}")
raise
@contextmanager
def get_db_connection():
"""Context manager for database connections."""
if CONNECTION_POOL is None:
initialize_connection_pool()
conn = None
try:
conn = CONNECTION_POOL.getconn()
yield conn
except Exception as e:
if conn:
conn.rollback()
raise e
finally:
if conn:
CONNECTION_POOL.putconn(conn)- Fetch similar memories tool
We create a tool that connects to the memory database, embeds the user’s query, and finds the most relevant past interactions using vector similarity. This lets the agent fetch contextually similar memories whenever it needs to enrich the final prompt for the language model.
@mcp.tool()
def search_memories_simple(query: str) -> str:
"""
Search and return relevant memories for a given query.
"""
logger.info(f"Searching memories for: {query}")
memory_chunks = []
try:
with get_db_connection() as conn:
with conn.cursor() as cur:
# Check if memory_embeddings table exists
cur.execute("""
SELECT EXISTS (
SELECT FROM information_schema.tables
WHERE table_name = 'memory_embeddings'
);
""")
if cur.fetchone()[0]:
try:
cur.execute("""
SELECT
chunk,
embedding <=> ai.ollama_embed('nomic-embed-text', %s, host => 'http://ollama:11434') as distance
FROM memory_embeddings
ORDER BY distance
LIMIT 3;
""", (query,))
memory_chunks = cur.fetchall()
except Exception as embedding_error:
logger.warning(f"Vector search failed, using text search: {embedding_error}")
# Fallback to text search
cur.execute("""
SELECT
chunk,
0.5 as distance
FROM memory_embeddings
WHERE chunk ILIKE %s
LIMIT 3;
""", (f"%{query}%",))
memory_chunks = cur.fetchall()
else:
logger.info("memory_embeddings table does not exist, skipping memory retrieval")
except Exception as memory_error:
logger.warning(f"Memory retrieval failed: {memory_error}")
memory_chunks = []
# Format and return results exactly like enhanced_query does
if memory_chunks:
memory_context = "\n".join([f"- {chunk[0]}" for chunk in memory_chunks])
return f"Relevant memories found for '{query}':\n{memory_context}"
else:
return f"No relevant memories found for '{query}'"- Store user queries tool
We create a tool that saves each new user query and its response in the memory table with auto-generated metadata. This ensures that every conversation builds a deeper memory for future queries.
@mcp.tool()
def store_user_interaction(query: str, response: str, source: str = "user") -> str:
"""
Store a user query and response in the memory table.
The vectorizer will automatically create embeddings.
"""
logger.info(f"Storing user interaction: {query[:100]}...")
try:
# Connect using psycopg
conn = psycopg2.connect(
dbname=DB_NAME,
user=DB_USER,
password=DB_PASS,
host=DB_HOST,
port=DB_PORT
)
# Auto-generate metadata
metadata = {
"source": source,
"timestamp": datetime.utcnow().isoformat() + "Z",
"interaction_type": "user_query"
}
# Insert into memory table
with conn.cursor() as cur:
cur.execute(
"INSERT INTO memory (query, response, metadata) VALUES (%s, %s, %s)",
(query, response, json.dumps(metadata))
)
conn.commit()
conn.close()
logger.info("User interaction stored successfully")
return json.dumps({
"success": True,
"message": "User interaction stored successfully",
"query": query,
"source": source
}, indent=2)
except Exception as e:
logger.error(f"Storage error: {e}")
return json.dumps({
"error": f"Storage error: {str(e)}",
"query": query
}, indent=2)
if __name__ == "__main__":
mcp.run()Implementing the MCP Client in Agent Loop
We create a WikiMemoryMCPChat class that configures an MCP client, connects it to Groq’s LLM, and wires up async methods to search memory, store new interactions, and run plain queries. The main loop accepts user input, calls the right MCP tools, and streams the LLM’s response—keeping memory and reasoning in sync.
import asyncio
import os
import json
from dotenv import load_dotenv
from langchain_groq import ChatGroq
from mcp_use import MCPAgent, MCPClient
load_dotenv()
class WikiMemoryMCPChat:
def __init__(self, config_file="mcp-config.json"):
self.config_file = config_file
self.client = None
self.agent = None
self.llm = None
self.initialize_components()
def initialize_components(self):
"""Initialize MCP client and agent."""
self.client = MCPClient.from_config_file(self.config_file)
groq_api_key = os.environ.get("GROQ_API_KEY")
if not groq_api_key:
raise ValueError("GROQ_API_KEY environment variable is required")
self.llm = ChatGroq(
groq_api_key=groq_api_key,
model="meta-llama/llama-4-scout-17b-16e-instruct"
)
self.agent = MCPAgent(
llm=self.llm,
client=self.client,
memory_enabled=False, # Using our own memory system
)
async def memory_search(self, query: str):
"""Search memory using vector similarity."""
try:
command = f"Search memory using search_memories_simple tool for: {query}"
response = await self.agent.run(command)
return response
except Exception as e:
return f"Error searching memory: {str(e)}"
async def store_interaction(self, query: str, response: str, source: str = "user"):
"""Store a query-response pair in memory."""
try:
command = f"Store interaction using store_user_interaction tool: query='{query}', response='{response}', source='{source}'"
result = await self.agent.run(command)
return result
except Exception as e:
return f"Error storing interaction: {str(e)}"
async def regular_query(self, query: str):
"""Regular query without Wikipedia or memory context, with auto-storage."""
try:
response = await self.agent.run(query)
# Auto-store the query and response
try:
await self.store_interaction(query, response, "regular_query")
print("💾 [Auto-stored in memory]")
except Exception as store_error:
print(f"⚠️ [Failed to auto-store: {store_error}]")
return response
except Exception as e:
return f"Error processing regular query: {str(e)}"
async def run_wiki_memory_chat():
"""Run the Wikipedia + Memory enhanced chat interface."""
print("🚀 Initializing Wikipedia + Memory Enhanced PostgreSQL MCP Chat...")
try:
chat = WikiMemoryMCPChat()
print("\n" + "="*60)
print("🧠 WIKIPEDIA + MEMORY ENHANCED CHAT INTERFACE")
print("="*60)
print("\n📚 QUERY MODES:")
print(" 🔍 'wiki <query>' - Wikipedia search only")
print(" 🧠 'memory <query>' - Memory similarity search")
print(" 💬 'regular <query>' - Regular query (no wiki/memory)")
print("\n⚙️ SYSTEM COMMANDS:")
print(" 💾 'store <query> | <response>' - Manual memory storage")
print(" ❌ 'exit' or 'quit' - End chat")
print("\n💡 TIP: Default queries automatically search Wikipedia and use memory context!")
print("="*60)
while True:
user_input = input("\n🤖 You: ").strip()
if not user_input:
continue
if user_input.lower() in ["exit", "quit"]:
print("👋 Ending conversation...")
break
if user_input.lower().startswith("memory "):
query = user_input[7:]
print(f"\n🧠 Memory Search: {query}")
print("━" * 40)
response = await chat.memory_search(query)
print(response)
continue
if user_input.lower().startswith("regular "):
query = user_input[8:]
print(f"\n💬 Regular Query: {query}")
print("━" * 40)
response = await chat.regular_query(query)
print(response)
continue
if user_input.lower().startswith("store "):
try:
content = user_input[6:]
if " | " in content:
query, response = content.split(" | ", 1)
result = await chat.store_interaction(query.strip(), response.strip(), "manual")
print(f"💾 {result}")
else:
print("❌ Format: store <query> | <response>")
except Exception as e:
print(f"❌ Error: {e}")
continue
except Exception as e:
print(f"❌ Failed to run chat: {e}")Testing Your Setup
Sample Queries
- “Regular Who is edison”
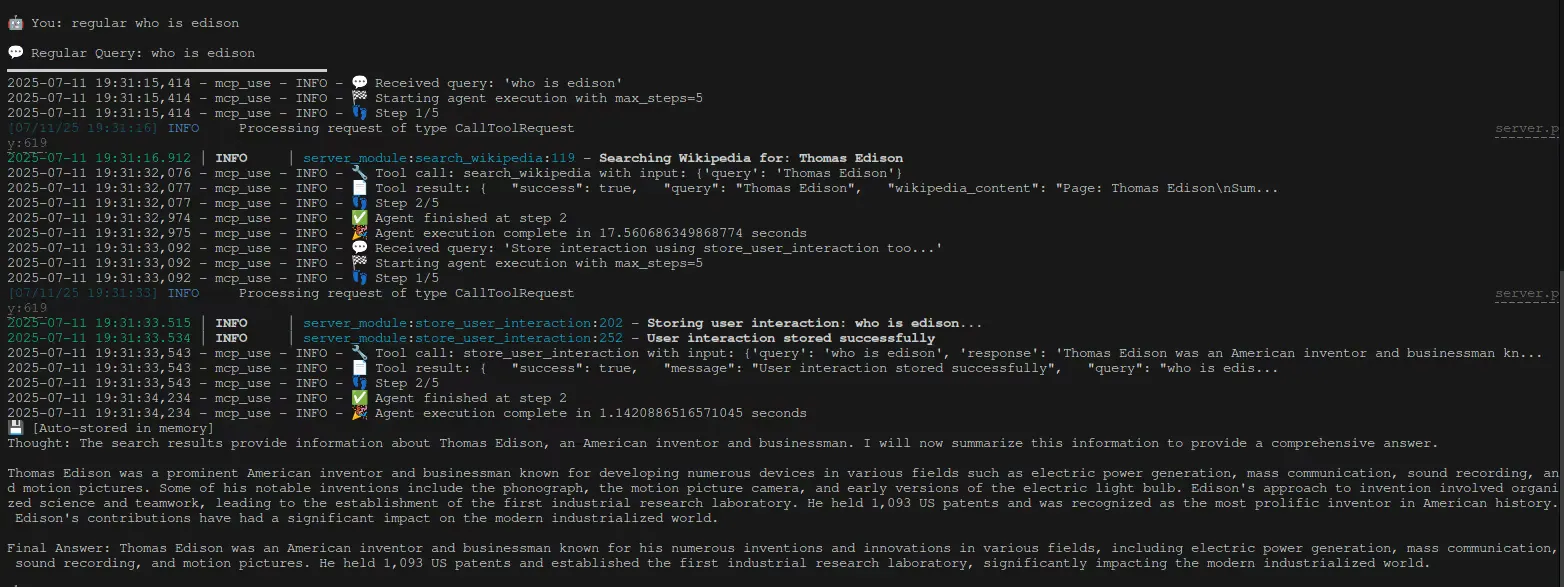
- “Memory who is edison”

Security Considerations
When connecting LLM agents to external tools, it’s crucial to watch for common risks such as tool poisoning (where malicious inputs corrupt your memory store) and prompt injection (where user input manipulates how your LLM uses tools). Both can lead to incorrect outputs or data leaks if left unchecked.
Best Practices
- Use guardrails or similar patterns
Add guardrails or control layers to limit how the LLM can invoke tools. This ensures the model only calls safe, approved functions and blocks malicious or unintended tool actions.. - **Validate inputs, constrain tool outputs
**Always validate user input before passing it to tools, checking for unsafe content or unexpected formats. Constrain tool outputs to ensure only clean, trusted data is returned to the LLM. - **Logging, auditing, and rate limits
**Log all tool calls and agent actions to enable traceability in case something goes wrong. Use rate limits and audits to catch abuse early and prevent repeated misuse.
How Superteams Can Help
At Superteams, we help you build, deploy, and scale robust agentic AI systems, going far beyond simple prototypes.
- **End-to-End AI Engineering:
**We help you architect and implement powerful agentic AI, connecting fast pgvector-powered memory layers inside PostgreSQL with external LLMs using the Model Context Protocol (MCP). From designing robust schemas to wiring up tool contracts and agent loops, we ensure your system is ready for the real world. - **Advanced Architectures and RAG Pipelines:
**Our team builds on this foundation with advanced capabilities: setting up retrieval-augmented generation (RAG) pipelines, chaining multiple agents together using MCP for agent-to-agent (A2A) orchestration, and testing hybrid LLM stacks so you always get the best mix of local and cloud reasoning. - **Production-Ready and Secure:
**We don’t just build; we productionize. That means integrating pgvector with encryption, enforcing security guardrails, and using MCP’s structured tool contracts to deliver safe, auditable operations. Your agents will be secure, scalable, and compliant from day one. - **Real-World Solutions for Any Domain:
**Whether your use case is knowledge graphs, customer support, or autonomous data agents, we help you design and deploy memory-aware agents that can think, reason, and act in context, ready to handle complex, evolving workflows. - **Collaboration, Enablement, and Upskilling:
**We work as an extension of your team, as we build together and share best practices so you stay in control of your AI roadmap. - **Future-Proof, Modular Design:
**Our solutions are built to be flexible and modular, able to evolve with your business as your data, workflows, and ambitions grow.
Ready to Build with Us?
Let’s take your next AI project from prototype to production. Contact us to start your journey.
References
Model Context Protocol (MCP) — MCP Spec & Tools
Anthropic Docs — Claude API & Developer Docs
Groq Developer Docs — Groq API & LLM Usage
Run high-speed, low-latency LLM calls with Groq’s specialized hardware stack.
Ollama — Run & Embed Local Models
Local LLMs and embedding workflows — run Mistral, Llama, or custom models on your machine.
pgvector — Official pgvector Extension
Add vector similarity search to PostgreSQL for RAG and semantic search.
pgai — PostgreSQL AI Extension
Built-in AI functions for embeddings, vectorizers, and LLM calls directly in Postgres.




-Feature-Image.CjBFdO7y_Z1bTNvg.webp)