
Suppose you’re an e-commerce platform that has a lot of different categories of products in your inventory. Every time a new product comes into your inventory, you would like it to be automatically classified into one of the predefined categories. Also, you would like to know which are the similar kinds of products in your inventory to keep track of the goods you have. This type of system can be incredibly useful for e-commerce platforms as it streamlines the product categorization process, saves time and manual effort, and enables efficient inventory management.
Moreover, by identifying similar products, you can better understand your product assortment, identify potential gaps or redundancies, and make informed decisions about product procurement, pricing, and promotions. This way you can optimize your inventory levels to minimize stockouts and overstocking.
At Superteams.ai, we decided to take on this problem statement and created an AI-powered solution to address it. We designed a system that classifies product images into their respective categories and then suggests similar products already available in the inventory.
To achieve this, we leveraged two cutting-edge technologies: OpenAI’s CLIP model and the Qdrant Vector Database.
OpenAI’s CLIP Model
OpenAI’s CLIP (Contrastive Language-Image Pre-training) model is a game-changer in the AI domain. This powerful model generates both text and image embeddings in a shared vector space, enabling seamless mapping between textual concepts and visual representations. The magic lies in the model’s ability to place semantically similar texts and images in close proximity within the vector space. This means that images and their corresponding textual descriptions are naturally aligned, making it incredibly easy to match images to their respective categories.
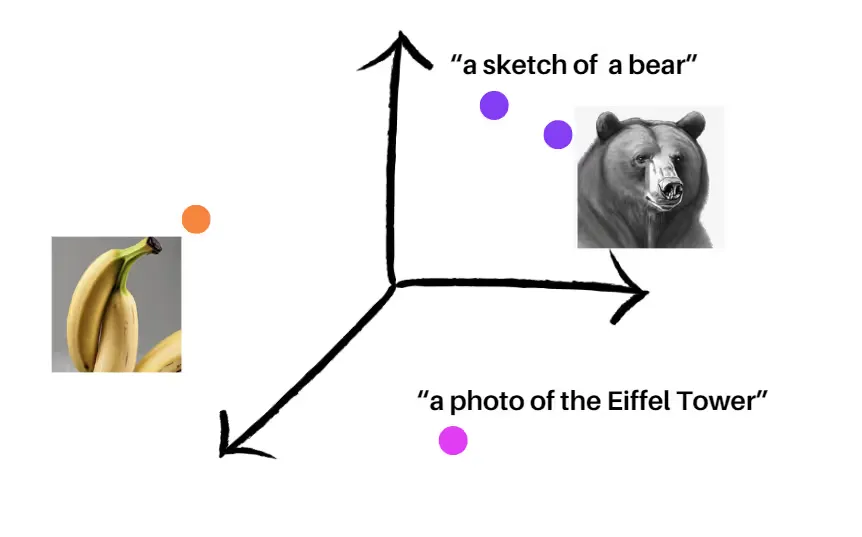
A demo of how CLIP would place embeddings of different images and texts
Qdrant
While the CLIP model lays the foundation for our solution, the Qdrant Vector Database takes it to the next level. Qdrant is an open-source database specifically designed for storing and retrieving vector embeddings and their associated metadata with exceptional speed and efficiency. Its advanced similarity search capabilities allow us to quickly explore the vast vector space and retrieve the most relevant information from the database corpus.
By leveraging Qdrant, we can perform lightning-fast lookups of user queries against the stored vector embeddings. This means that when a new product image is uploaded, our system can swiftly identify the most similar products already present in your inventory, empowering you to make informed decisions about product categorization and inventory management.
The Workflow
We used a Fashion Product Dataset from Kaggle. This dataset consists of around 44,000 images of various fashion products and their respective product categories. There are about 143 types of categories. And they look something like this:
Shorts
Trousers
Rain Trousers
Sweaters
Sarees
Shrug
Sports Sandals
…….
Bracelet
Body Wash and Scrub
Compact
Trunk
Mens Grooming Kit
Boxers
Rompers
Concealer
Deodorant
Hats
Heels
Headband
Wallets
Free Gifts
- The first step is to create CLIP embeddings of these categories and store them in a collection in Qdrant called “Text-Embeddings”.
- Then for our recommendation system, we are creating another collection called “Image-Embeddings”. We’ll compute the embeddings of all the 44,000 product images and store them in the collection.

- User uploads an image of a product, and we compute the embeddings of the image.
- A similarity search of this query embedding with the “Text-Embeddings” collection yields the category of the uploaded image of the product.
- A similarity search of the query embedding with the “Image-Embeddings” collection gives the product images of the inventory which are similar to the uploaded image of the product.
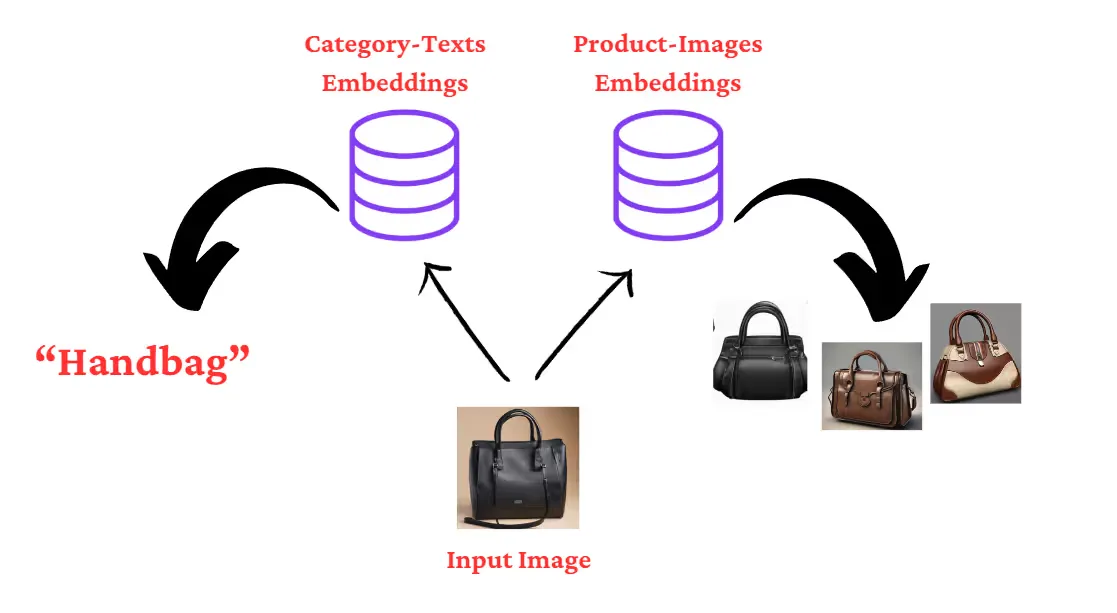
Workflow Diagram
Let’s Get to the Code
Install the required packages.
pip install torch transformers qdrant-client gradio pillow pandas kaggleDownload the dataset:
kaggle datasets download -d paramaggarwal/fashion-product-images-smallExtract the product categories.
import pandas as pd
# Replace 'path_to_csv' with the actual path to your CSV file
csv_file_path = 'styles.csv'
# Read the CSV file into a DataFrame
df = pd.read_csv(csv_file_path, on_bad_lines='skip')
# Now 'df' holds the DataFrame object with the data from the CSV file
print(df)
Item_List = list(set(df['articleType'].tolist()))Load the CLIP model:
from transformers import CLIPProcessor, CLIPModel
import torch
model_id = "openai/clip-vit-base-patch32"
processor = CLIPProcessor.from_pretrained(model_id)
model = CLIPModel.from_pretrained(model_id)
# move model to device if possible
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)Compute the embeddings of the category texts:
tokens = processor(
text=Item_List,
padding=True,
images=None,
return_tensors='pt'
).to(device)
tokens.keys()
text_emb = model.get_text_features(
**tokens
)
text_emb_list = text_emb.detach().cpu().numpy().tolist()Launch an instance of Qdrant on localhost:
docker run -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage:z \
qdrant/qdrantUpsert the embeddings into a collection called “text_embeddings”. We also add a payload metadata along with the embeddings. The metadata contains the text labels for the product categories. We’ll use this metadata later to retrieve the product category.
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="text_embeddings",
vectors_config=models.VectorParams(size=512, distance=models.Distance.COSINE),
)
# Convert list into a list of dictionaries
payload = [{'itemtype': item} for item in Item_List]
# Show the result
print(payload)
# Create a list of IDs from 1 to the length of the items list
id_list = [i for i in range(1, len(Item_List) + 1)]
# Show the result
print(id_list)
client.upsert(
collection_name="text_embeddings",
points=models.Batch(
ids=id_list,
payloads=payload,
vectors=text_emb_list,
),
)Next, let’s create another collection for the image embeddings.
client.delete_collection(collection_name="image_embeddings")
client.create_collection(
collection_name="image_embeddings",
vectors_config=models.VectorParams(size=512, distance=models.Distance.COSINE),
)Next we create a Pandas dataframe to organize the image embeddings and the associated metadata (filepath of the images).
import os
import torch
from PIL import Image
import pandas as pd
# Define the directory where the images are stored
image_directory = 'images'
# Initialize an empty list to store the data
data = []
# Loop over all files in the image directory
for i, filename in enumerate(os.listdir(image_directory)):
if filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif')):
# Add any other file types if needed
# Construct the full path to the image file
file_path = os.path.join(image_directory, filename)
with Image.open(file_path) as img:
# Prepare the image for the model
tokens = processor(
text=None,
images=img,
return_tensors="pt"
)["pixel_values"].to(device)
# Get image embeddings from the model
image_embeddings = model.get_image_features(
tokens
)
# Append the filename and embeddings to the data list
data.append((filename, image_embeddings.detach().cpu().numpy().tolist()[0])
# Print the iteration number
print(f'Iteration {i}: Processed {filename}')
# Create a DataFrame with the data
df = pd.DataFrame(data, columns=['Filename', 'ImageEmbeddings'])
# Display the DataFrame
print(df)
In [ ]:
# Assuming 'df' is your existing DataFrame
# Create a new 'ID' column that starts at 1 and increments by 1 for each row
df['ID'] = range(1, len(df) + 1)
# Display the updated DataFrame
print(df)
# Create the list of dictionaries with "Filename" as the key
filenames_list = [{'Filename': filename} for filename in df['Filename']]
# Create the list of ImageEmbeddings (assuming ImageTensor is already a list of embeddings)
image_embeddings_list = df['ImageEmbeddings'].tolist()
# Create the list of IDs
ids_list = df['ID'].tolist()Since we have a large number of image embeddings (for 44,000 product images) it’s a good idea to upsert it into the VectorDB in batches of 1000 for speed and efficiency.
batch_size = 1000
total_points = len(ids_list)
for start_index in range(0, total_points, batch_size):
# End index is the start of the next batch or the end of the list
end_index = min(start_index + batch_size, total_points)
# Slice the lists to create the current batch
batch_ids = ids_list[start_index:end_index]
batch_filenames = filenames_list[start_index:end_index]
batch_image_embeddings = image_embeddings_list[start_index:end_index]
# Upsert the current batch
client.upsert(
collection_name="image_embeddings",
points=models.Batch(
ids=batch_ids,
payloads=batch_filenames,
vectors=batch_image_embeddings,
),
)We’ll now start writing the functions for our Gradio UI. The first function takes a PIL image as an input. It then performs a similarity search with the text-embeddings collection and returns the top result, which is basically the category of the product.
def image_classifier(image):
# Prepare the image for the model
tokens = processor(
text=None,
images=image,
return_tensors="pt"
)["pixel_values"].to(device)
# Get image embeddings from the model
image_embeddings = model.get_image_features(
tokens
)
query_vector = image_embeddings.detach().cpu().numpy().tolist()[0]
record = client.search(
collection_name="text_embeddings",
query_vector=query_vector,
limit=1,
)
return record[0].payload['itemtype']The second function takes the PIL image as input and, by performing a similarity search on the image-embeddings collections, returns the top ten images (from the inventory) as a list of file paths.
def image_path_list(image):
# Prepare the image for the model
tokens = processor(
text=None,
images=image,
return_tensors="pt"
)["pixel_values"].to(device)
# Get image embeddings from the model
image_embeddings = model.get_image_features(
tokens
)
query_vector = image_embeddings.detach().cpu().numpy().tolist()[0]
record = client.search(
collection_name="image_embeddings",
query_vector=query_vector,
limit=10,
)
return [('fashion-dataset/fashion-dataset/images/' + element.payload['Filename'], None) for element in record]Code for the Gradio UI:
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
upload_image = gr.Image(label= "Upload Your Image", type = 'pil')
classifier_text = gr.Textbox(label= "Type of Item")
with gr.Row():
image_gallery = gr.Gallery(label= "Similar items in the inventory", object_fit= 'contain', columns=[5], rows=[2],)
with gr.Row():
clr_btn = gr.Button(value= "Clear")
first_step = upload_image.upload(fn= image_classifier, inputs= upload_image, outputs= classifier_text)
first_step.then(fn= image_path_list, inputs= upload_image, outputs = image_gallery)
clr_btn.click(fn=lambda: (None, None, []), inputs=None, outputs=[upload_image, classifier_text, image_gallery])
demo.launch(share=True)Here’s a brief explanation of the code:
1. The `with gr.Blocks() as demo:` statement creates a Gradio interface named `demo`.
2. Inside the `demo` block, there are three `gr.Row()` components, each representing a row in the user interface.
3. In the first row:
- `upload_image` is an `gr.Image` component that allows the user to upload an image. It has a label “Upload Your Image” and accepts PIL (Python Imaging Library) images.
- `classifier_text` is a `gr.Textbox` component that displays the type of item based on the image classification.
4. In the second row:
- `image_gallery` is a `gr.Gallery` component that displays similar items from the inventory. It has a label “Similar items in the inventory” and is configured to show 5 columns and 2 rows of images.
5. In the third row:
- `clr_btn` is a `gr.Button` component with the label “Clear”.
6. The `first_step` variable is assigned the result of `upload_image.upload()`, which triggers the `image_classifier` function when an image is uploaded. The uploaded image is passed as input to the function, and the output is displayed in the `classifier_text` textbox.
7. The `first_step.then()` statement chains another function call to `image_path_list` after the `image_classifier` function completes. It takes the uploaded image as input and updates the `image_gallery` with the resulting list of recommended image paths.
8. The `clr_btn.click()` statement defines the behavior when the “Clear” button is clicked. It sets the `upload_image`, `classifier_text`, and `image_gallery` components to their default values (None, None, and an empty list, respectively).
9. Finally, `demo.launch(share=True)` launches the Gradio interface and makes it shareable, allowing others to access it via a generated URL.
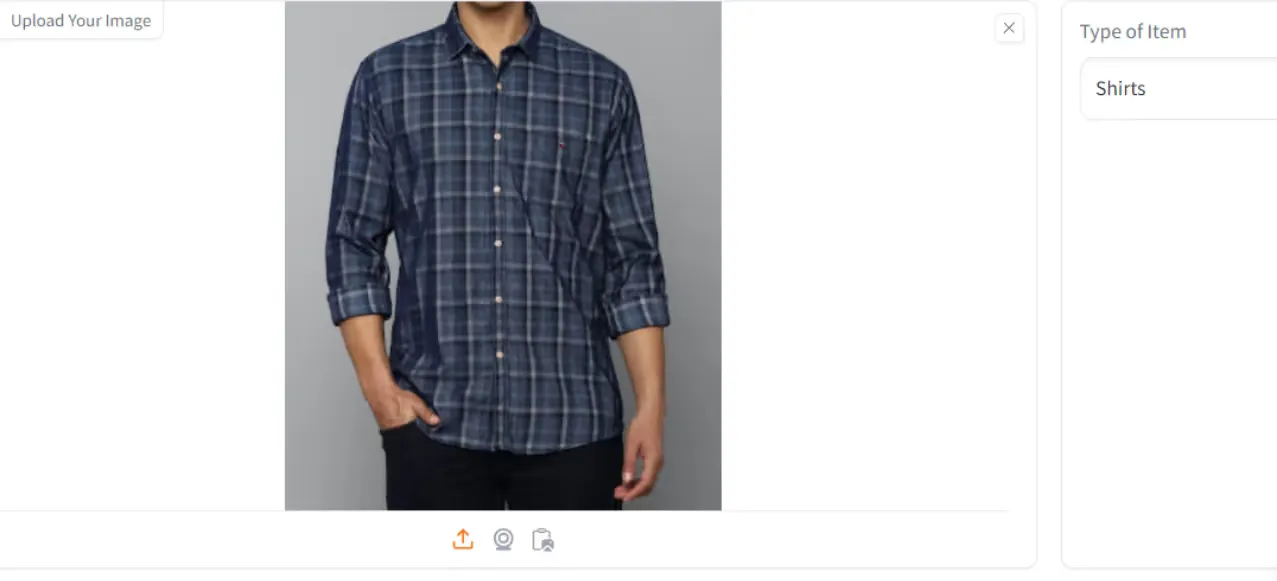
Results
Here are some screenshots from our UI:







GitHub
You can access the code in this Github repository: https://github.com/vardhanam/Product_Classifier_Recommendation/tree/main




-Feature-Image.CjBFdO7y_Z1bTNvg.webp)