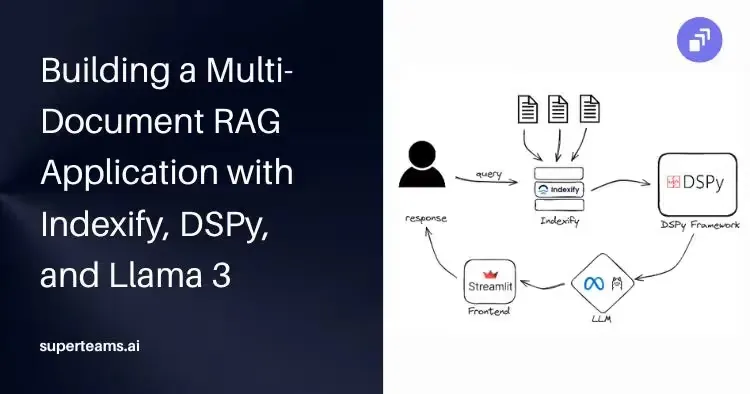
Can you envision a future where applications seamlessly understand your queries and extract relevant information from a multitude of documents? In this article, we will create a RAG (Retrieval-Augmented Generation) application that uses Indexify, DSPy, and Llama 3 to simultaneously accept multiple PDFs and provide precise answers.
Introduction
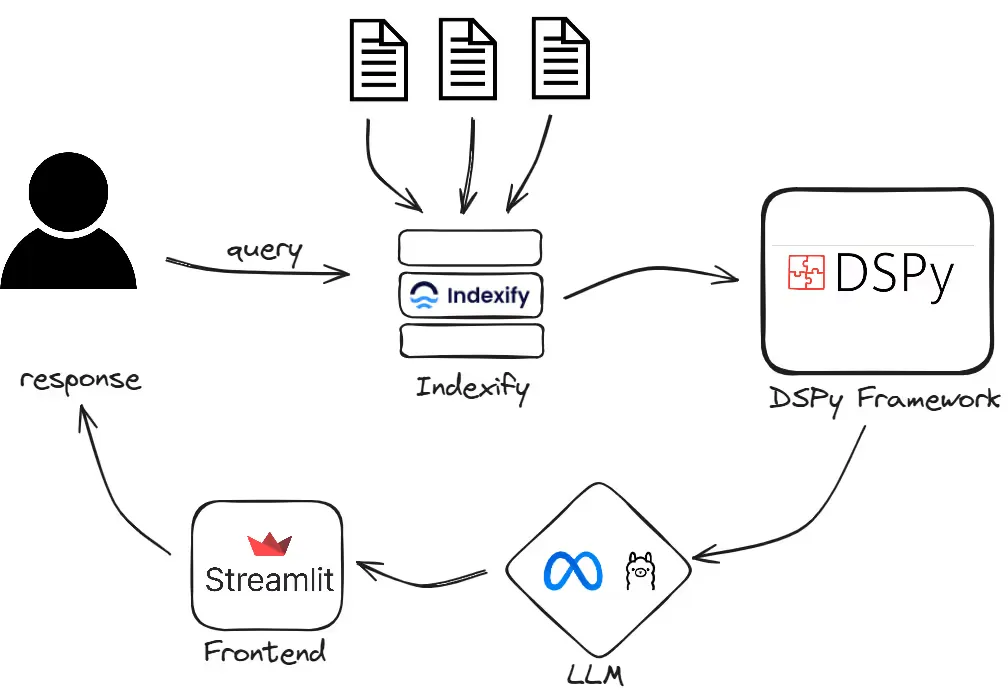
Here, we will guide you through the process of designing a RAG (Retrieval-Augmented Generation) application capable of handling multiple documents simultaneously and answering user queries. By utilizing Indexify for indexing documents in chunks, DSPy as the framework, and Llama 3 as the language model, we’ll demonstrate how to create a powerful system that transforms the way we interact with large volumes of information.
But first, let’s start by understanding what’s Indexify:
What’s Indexify?
Indexify is a data framework designed for building ingestion and extraction pipelines for unstructured data through its connectivity with different LLM frameworks like LangChain, DSPy, etc.
There are various issues with traditional vector databases for storing embeddings. Some of them are:
- Incomplete or inaccurate data ingestion.
- Slow ingestion and extraction speed.
- Incompatibility with different data formats available.
These issues are resolved by switching to Indexify to store the data, as it provides a smooth and effortless way for data ingestion and extraction from the database.
Indexify supports a variety of documents like PDFs, videos, audios, texts, and images.
It also offers a variety of data operations like text extraction, markdown conversion, audio extraction, facial detection, embeddings, text splitting, summarization, etc.
Next, let’s understand DSPy.
Why DSPy?
DSPy is an open-source Python framework that prioritizes programming over prompting in the building of large-scale RAG applications. It provides many ways to tune the RAG pipeline with the help of custom and predefined Signatures, Modules, and Optimizers.
GitHub
Access the full code and implementation on GitHub.
Let’s Code
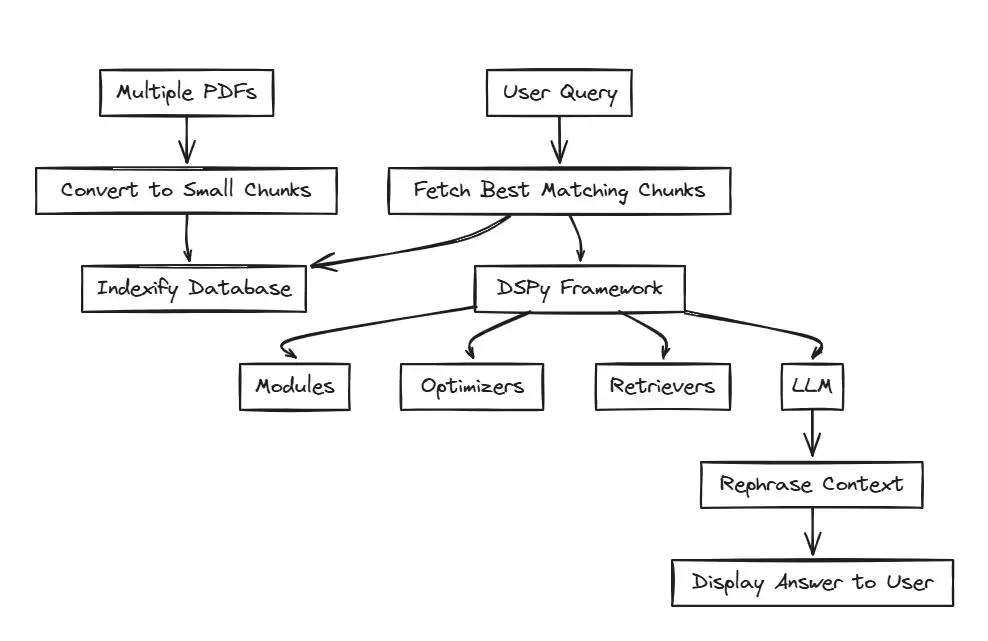
Setting Up the Environment
Let’s start by downloading and starting the Indexify server.
Note: Indexify requires a Linux-based terminal. If you are using any other operating system, please refer here.
curl https://getindexify.ai | sh
./indexify server -dNow, we need to install and run some of the necessary Indexify extractors required for processing the documents.
pip install indexify-extractor-sdk
indexify-extractor download tensorlake/minilm-l6
indexify-extractor download tensorlake/chunk-extractor
indexify-extractor join-serverLet’s install the necessary libraries that we’ll be using in this project.
pip install indexify
pip install indexify-dspy
pip install ollama
pip install streamlit
pip install langchain_communityDatabase Setup
In this section, we will set up the structural graph to process all the documents. We will start by declaring the name of the graph and then specify all the functions that need to be performed by different Indexify extractors.
from indexify import IndexifyClient, ExtractionGraph
client = IndexifyClient()
extraction_graph_spec = """
name: 'testdb'
extraction_policies:
- extractor: 'tensorlake/chunk-extractor'
name: 'chunker'
input_params:
chunk_size: 1000
overlap: 100
- extractor: 'tensorlake/minilm-l6'
name: 'embeddings'
content_source: 'chunker'
"""
extraction_graph = ExtractionGraph.from_yaml(extraction_graph_spec)
client.create_extraction_graph(extraction_graph)After setting up the structural graph, it’s time to import all the necessary libraries required for the application:
import streamlit as st
import dspy
from indexify import IndexifyClient
from indexify_dspy import retriever
from langchain.document_loaders import PyPDFLoaderNow, we need to instantiate the Indexify client and declare the database name to be used, along with the retriever model to fetch the data from the Indexify retriever.
Note: The database name should be equivalent to the name given during the creation of the graph.
client = IndexifyClient()
index_name = "testdb.embeddings.embedding"
indexify_retriever_model = retriever.IndexifyRM(index_name,client)Once Indexify is ready, let’s instantiate DSPy and configure it with the retriever and language model.
lm = dspy.OllamaLocal(model="llama3",timeout_s = 180)
dspy.settings.configure(lm=lm, rm=indexify_retriever_model)Now, we need to declare a function get_context that will take the user query as input, retrieve the three best matching results from the database, and return them as output.
def get_context(question):
retrieve = retriever.IndexifyRM(client)
context = retrieve(question, index_name, k=3).passages
return contextIt’s time to create our custom DSPy Signature, but first let’s understand: what are Signatures in DSPy?
Signatures in DSPy
A DSPy Signature is a basic form of algorithmic steps that simply require inputs and outputs, and optionally, a small description about them and the tasks too.
input -> output
Generally, there are two types of Signatures in DSPy:
- Inline Signatures
- Class-based Signatures
Inline signatures can work with small tasks where complex reasoning is not required, but for a robust RAG application, class-based signatures are best suited.
Refer here for a better understanding of DSPy Signatures.
Let’s build up a simple class-based signature for our application.
class GenerateAnswer(dspy.Signature):
"""Answer questions with factoid answers."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="an explained answer")Moving forward, we need to build a module in DSPy, so let’s understand the concept of modules.
Modules in DSPy
A module in DSPy is like a block for programs that use Large Language Models. They provide a simplified way to handle any DSPy Signature. The structure of modules in DSPy is very similar to the structure of neural networks in PyTorch.
Just like signatures, DSPy modules can also be categorized into two types:
- Built-in modules
- User-defined modules
Refer here for a better understanding of DSPy Modules.
We are going to create a user-defined module built with small built-in modules. In our program, we have used Prediction and ChainOfThought as the built-in modules.
class RAG(dspy.Module):
def __init__(self, num_passages=3):
super().__init__()
self.retrieve = dspy.Retrieve(k=num_passages)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
context = get_context(question)
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)
rag = RAG()Now that our DSPy framework section is ready, we can begin the frontend part. But before that, we need to create a few more functions to simplify and enhance the understandability of the code.
The first one needed is the upload_data function to upload document data into Indexify..
def upload_data(doc_list):
for doc_name in doc_list:
pdf_loader = PyPDFLoader(file_path=doc_name)
documents = pdf_loader.load()
for doc in documents:
print(doc.page_content)
content_id = client.add_documents("testdb", doc.page_content)
client.wait_for_extraction(content_id)We also need one more function extract_file_names that will extract the file names from the uploaded files and return a list of all the files uploaded by the user.
def extract_file_names(uploaded_files):
file_names = []
for file in uploaded_files:
file_names.append(file.name)
return file_namesIt’s time to create the frontend for the application. We will be using Streamlit for this purpose.
First, we need to configure the layout of the web page and set up the sidebar where users can upload their documents to perform RAG operations.
st.set_page_config(layout="wide")
with st.sidebar:
st.title("Upload PDFs")
uploaded_files = st.file_uploader("Choose PDFs", accept_multiple_files=True, type=["pdf"])
if st.button("Upload"):
if uploaded_files:
file_names = extract_file_names(uploaded_files)
upload_data(file_names)
st.success("PDFs uploaded successfully!")
for uploaded_file in uploaded_files:
st.write(uploaded_file.name)
else:
st.error("Please select PDFs to upload.")Our next step will be to set up the chatbot where users can put up their queries and get the relevant answers from the documents uploaded.
st.title("Indexify Chatbot")
user_input = st.text_input("You: ", "")
if user_input and st.button("Submit"):
bot_response = rag(user_input).answer
st.text_area("Bot response:", bot_response, height=100)Now our web app is ready to run and retrieve answers for any question based on the documents uploaded.
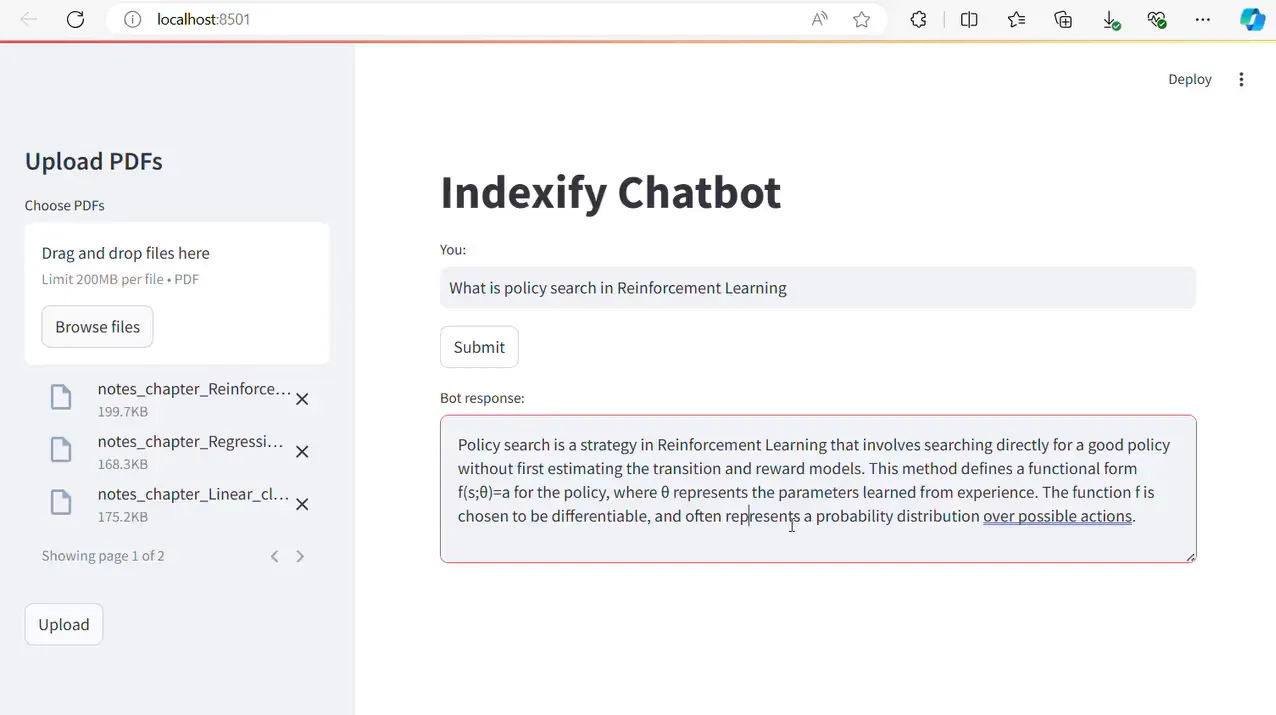
Final Output
When a user uploads documents from the Streamlit web app, the Indexify and DSPy pipeline converts the documents into small chunks and stores them in Indexify. After all the files are uploaded successfully, the user can enter a query in the input box. Based on the query, the chatbot finds the best answers, which are rephrased by the LLM and displayed on the page.
You can see the video demo here:
https://youtu.be/B99NQQK7mxU?si=R6hnCwHRkiPgS0dS
Conclusion
In summary, this project showcases the effectiveness of building RAG applications that can handle multiple PDFs simultaneously using Indexify, DSPy, and Llama 3. By following this comprehensive guide, we have demonstrated how to utilize these powerful tools to create an efficient and accurate information retrieval system.
References
https://docs.getindexify.ai/getting_started/#indexify-server
https://docs.getindexify.ai/integrations/dspy/python_dspy/
https://docs.getindexify.ai/usecases/rag/
https://dspy-docs.vercel.app/docs/building-blocks/signatures




-Feature-Image.CjBFdO7y_Z1bTNvg.webp)