
In machine learning, anomaly detection plays a critical role in identifying unusual patterns and outliers in vast datasets. From detecting fraudulent activities in financial systems to spotting manufacturing defects in industrial processes, anomaly detection has wide-ranging applications across industries.
This guide explores how you can use a vector database to implement efficient and accurate anomaly detection systems.
Introduction to Anomaly Detection
Anomaly detection is the process of identifying data points, events, or observations that deviate significantly from the expected pattern in a dataset. These anomalies, also known as outliers, can provide valuable insights in various domains:
- Fraud Detection: Identifying unusual transactions or user behaviors.
- Network Security: Detecting potential cyber attacks or intrusions.
- Manufacturing: Spotting defects or irregularities in production processes.
- Healthcare: Identifying unusual patient symptoms or test results.
- Finance: Detecting market manipulations or insider trading.
Traditional anomaly detection methods often rely on statistical techniques or machine learning algorithms. However, these approaches can be computationally expensive and may struggle with high-dimensional data. This is where vector databases like Qdrant come into play, offering efficient similarity search capabilities that can be leveraged for anomaly detection.
Understanding the Dataset
For this guide, we’ll be working with a synthetic dataset of customer transactions. In this we have nine columns consisting of Customer ID, Name, Surname, Gender, Birthdate, Transaction Amount, Date, Merchant Name, and Category.
Here’s a sample of the first few rows of our dataset:
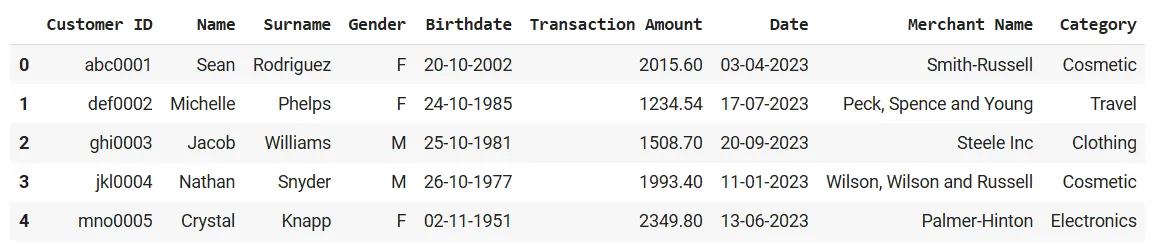
Out of these columns, we’ll be focusing on detecting anomalies in three main areas:
Customer IDs: Identifying unusual patterns in customer identifiers.
Transaction Amounts: Detecting unusually high transaction values.
Categories: Spotting infrequent or suspicious transaction categories.
We will use Qdrant vector DB. By using Qdrant’s vector similarity search capabilities, we’ll be able to efficiently identify these anomalies without relying on traditional statistical methods or complex machine learning algorithms.
Now, let’s dive into the step-by-step process of setting up our environment and using Qdrant for anomaly detection.
Implementation Steps
Step 1: Setting Up the Environment
First, we need to install the required libraries. Run the following command in your Jupyter notebook:
! pip install qdrant-client sentence-transformersStep 2: Importing Libraries and Loading Data
Next, we’ll import the necessary libraries and load our dataset:
import pandas as pd
file_path = '/content/updated_file.csv'
data = pd.read_csv(file_path)Step 3: Initializing Qdrant Client and Sentence Transformer
Now, we’ll set up our Qdrant client and load a pre-trained sentence transformer model:
from qdrant_client import QdrantClient
from qdrant_client.http import models
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')
client = QdrantClient(":memory:")Step 4: Preparing Data for Anomaly Detection
We’ll extract the relevant columns from our dataset and create embeddings:
cust_ids = data['Customer ID'].astype(str).tolist()
transaction_amounts = data['Transaction Amount'].astype(str).tolist()
categories = data['Category'].tolist()
cust_id_vectors = model.encode(cust_ids).tolist()
transaction_vectors = model.encode(transaction_amounts).tolist()
category_vectors = model.encode(categories).tolist()Step 5: Creating Qdrant Collections
We’ll define a function to create Qdrant collections and insert our data:
def create_and_insert(collection_name, vectors, items):
client.create_collection(
collection_name=collection_name,
vectors_config=models.VectorParams(size=len(vectors[0]), distance=models.Distance.COSINE)
)
points = [
models.PointStruct(id=i, vector=vector, payload={"item": item})
for i, (vector, item) in enumerate(zip(vectors, items))
]
client.upsert(collection_name=collection_name, points=points)
create_and_insert("customer_id_collection", cust_id_vectors, cust_ids)
create_and_insert("transaction_amount_collection", transaction_vectors, transaction_amounts)
create_and_insert("category_collection", category_vectors, categories)
print("Collections created and data inserted!")Step 6: Performing Anomaly Detection on Customer IDs
Now, let’s perform anomaly detection on our customer IDs. We’ll break this process down into several steps for clarity:
6.1 Defining Non-Anomalous Customer IDs
First, we need to define some customer IDs that we consider “normal” or non-anomalous. These will serve as our baseline for detecting unusual IDs:
positive_points = [
"stu9101",
"vwx3456",
"rst6789",
"stu7890",
"lmn9101",
]These customer IDs follow the expected pattern of three lowercase letters followed by four digits.
6.2 Converting to Vector Embeddings
Next, we need to convert these customer IDs into vector embeddings that Qdrant can work with:
positive_point_vectors = model.encode(positive_points).tolist()This step uses our pre-trained sentence transformer model to convert each customer ID into a numerical vector representation.
6.3 Querying Qdrant for Initial Anomalies
Now, we can use these vector representations of normal customer IDs to find the most dissimilar IDs in our database. These dissimilar IDs are likely to be our anomalies:
response = client.recommend(
collection_name='customer_id_collection',
negative=positive_point_vectors,
limit=3,
with_payload=True,
strategy=models.RecommendStrategy.BEST_SCORE
)
for point in response:
print(f"Anomaly: {point.payload['item']}, Score: {point.score}")This code will print the top three odd ones or the anomalies in the Customer ID column since we have set the limit to three.

These customer IDs clearly don’t follow the expected pattern, confirming they are indeed anomalies.
6.4 Finding More Anomalies
Now that we have identified some clear anomalies, we can use these to find more similar anomalous IDs:
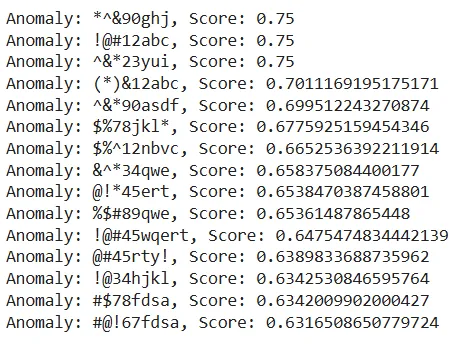
negative_points = ['!@#12abc', '^&*23yui', '*^&90ghj',]
negative_points_vectors = model.encode(negative_points).tolist()
response = client.recommend(
collection_name='customer_id_collection',
positive=negative_points_vectors,
limit=15,
with_payload=True,
strategy=models.RecommendStrategy.BEST_SCORE
)
for point in response:
print(f"Anomaly: {point.payload['item']}, Score: {point.score}")This approach has identified a number of customer IDs that don’t follow the expected pattern of three lowercase letters followed by four digits. These are our detected anomalies.
Step 7: Identifying Unusual Categories
Finally, let’s detect any unusual transaction categories:
positive_points = [
"Clothing",
"Electronics",
"Travel",
"Market",
"Restaurant",
]
positive_point_vectors = model.encode(positive_points).tolist()
response = client.recommend(
collection_name='category_collection',
negative=positive_point_vectors,
limit=3,
with_payload=True,
strategy=models.RecommendStrategy.BEST_SCORE
)
for point in response:
print(f"Anomaly: {point.payload['item']}, Score: {point.score}")
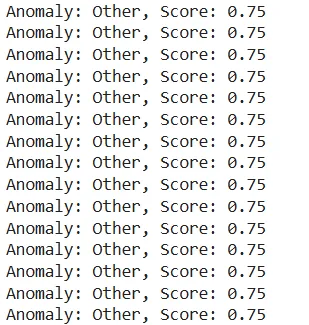
negative_points = ['other', 'other', 'other',]
negative_points_vectors = model.encode(negative_points).tolist()
response = client.recommend(
collection_name='category_collection',
positive=negative_points_vectors,
limit=15,
with_payload=True,
strategy=models.RecommendStrategy.BEST_SCORE
)
for point in response:
print(f"Anomaly: {point.payload['item']}, Score: {point.score}")
This will result in finding the categories which are not as the usual ones.
Conclusion
In this guide, we have explored how to use a vector database for anomaly detection in a customer transaction dataset. We have demonstrated how to detect anomalies in customer IDs, transaction amounts, and transaction categories using vector similarity search.
This approach offers several advantages over traditional anomaly detection methods:
- Efficiency: A vector DB’s search capabilities allow for fast querying, even with large datasets.
- Flexibility: The method can be easily adapted to different types of data and anomaly patterns.
- No need for explicit rules: Unlike rule-based systems, this approach can detect novel anomalies without predefined criteria.
- Scalability: As your dataset grows, Qdrant can handle increasing amounts of data efficiently.
By using the power of vector databases, you can build more effective and efficient anomaly detection systems, helping to identify potential fraud and other unusual activities in various domains.
If you want to learn more about how this approach can work for your organization, write to us at [email protected].




-Feature-Image.CjBFdO7y_Z1bTNvg.webp)