Introduction
The creation of stock video and stock animation is a massive hurdle in the media industry. These stock images are often used in conjunction with actual footage, and become part of the ‘B-Roll’ that media houses and video editors use during editing to ensure the flow of narrative. However, the availability of the right kind of stock footage has been one of the challenges that everyone, from an individual video editor to a larger media house, faces.
One of the areas where Generative AI is showing promise is the ability to rapidly generate stock footage or stock media purely through simple text prompts. The way it works is fairly simple: you write the description of the concept or video you want to generate, ideally with style, background and other details. Text to video generation using AI will then take that text and generate a video that visually represents your idea. This can potentially simplify life for creators, editors, content companies and media houses, helping them scale their production rapidly.
In this article, we discuss text-to-video and text-to-animation generation using Diffusion Models and Zero-Shot Video Generators. Earlier, text-to-video generation approaches relied on computationally heavy training and required large-scale video datasets. Now we can look at a low-cost approach - without any training or optimization - by leveraging the power of existing text-to-image synthesis methods (e.g., Stable Diffusion).
Public vs Private Generative AI Tech
There are a few publicly available text-to-video generation platforms out there now, such as InVideo, Wave.Video and several others. However, the challenge with public text-to-video generation systems - Glia.Cloud, Synthesia, Lumen5, Veed etc. - are several. First, they have been trained on public data sets, so getting the exact footage you need will be difficult. Second, with each prompt, you run the risk of ‘leaking’ your creative project details, which could lead to legal issues in the long run. Finally, your data may be used to further train the models, which you might be averse to.
In the future, privately deployed Generative AI technology is likely to be the best way to generate images / videos apt for the media industry. In this walkthrough, we will showcase the open-source technologies that are there for this, and demonstrate how you can create your own set-up to do this at scale.
Note: you would need the help of a developer to implement this, or you can simply get in touch with us at [email protected] and we will help you set this up.
Another point to keep in mind – this technology is currently in an early phase, so the key to getting the right results is through trying out a range of prompts and then discovering what works.
Method
By building upon an already trained text-to-image generation model, we can take advantage of high-quality public datasets. However, if you want to take it a step further, you should consider further training it on your own dataset in the long run. In this experiment, we will use a public dataset. At a fundamental level, the way it works is simple – we generate a series of images and combine them together to form a video.
Theoretical Concept
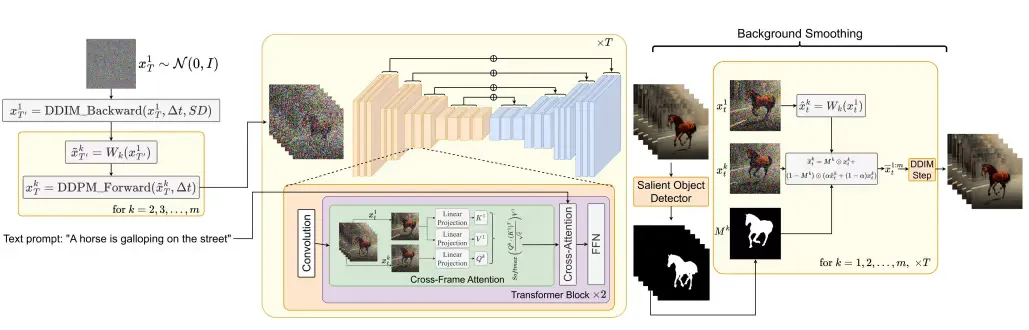
The zero-shot text-to-video synthesis makes use of the Stable Diffusion model in such a manner that the motion dynamics between the latent vectors and the global scene is time consistent. A cross frame attention mechanism is used to preserve the appearance and identity of the foreground object.
Now let’s break down what motion dynamics actually means. The Stable Diffusion model learns to generate images that have realistic motion. This is done by adding a noise residual to the latent image representation during the denoising process. The noise residual is a representation of the motion of the image, and it is added to the latent image representation in a way that preserves the overall shape of the image, but also introduces some randomness. This randomness allows the model to generate images that have a variety of different motions.
The following diagram shows the method overview:
Implementation
The following steps can be used to implement text-to-video. The official code repo is here.
In order to implement this, you will need at least 12 GB vRAM of GPU. We will test this experiment on E2E Cloud, our preferred Cloud GPU provider, which comes with the Ubuntu 22.04 virtual node with CUDA and python 3.10 pre-installed. The cheapest node will do for generating small GIFs. If you want to scale it up further, you can opt for the more expensive nodes.
Set-up
Start with cloning the above repository and installing requirements:
git clone https://github.com/Picsart-AI-Research/Text2Video-Zero.git
cd Text2Video-Zero/
# Install requirements using Python 3.10 and CUDA >= 11.6
virtualenv --system-site-packages -p python3.10 venv
source venv/bin/activate
pip install -r requirements.txt
NOTE: The official repository asks to create a Python 3.9 virtual environment, but it is no longer maintained so we went with Python 3.10.
Inference API
To run inferences, create an instance of Model class
import torch
from model import Model
model = Model(device = "cuda", dtype = torch.float16)This will load the model.
Text-to-Video
To directly call our text-to-video generator, run this Python command which stores the result in tmp/text2video/A_horse_galloping_on_a_street.mp4 :
prompt = "A horse galloping on a street"
params = {"t0": 44, "t1": 47 , "motion_field_strength_x" : 12, "motion_field_strength_y" : 12, "video_length": 8}
out_path, fps = f"./text2video_{prompt.replace(' ','_')}.mp4", 4
model.process_text2video(prompt, fps = fps, path = out_path, **params)

Other animations generated are given below:




Next Steps
The above steps showcase the proof-of-concept zero shot text-to-video creation process. As the next step, you can think about an automation workflow that allows you to generate this at scale. Alternatively, you could integrate this with your current media workflow, through building out an API on top of this.
You could additionally think about further fine-tuning or custom training the model with your own dataset to get footage that’s aligned with the creative work that you do.
At Superteams.ai, we are conducting experiments that are on the bleeding edge of Generative AI, and are happy to discuss a pilot if you would want to test it with your internal stack. Reach out to us by writing to [email protected].



-Feature-Image.CjBFdO7y_Z1bTNvg.webp)