Introduction
In the rapidly evolving field of Large Language Models, AI coding copilots have emerged as powerful productivity tools for programmers. The most popular proprietary one is Github copilot. However, the challenge with proprietary AI coding copilots is that when enterprises deploy them, they risk sharing their internal code and IP with an external platform. A powerful alternative strategy is to use open source AI coding copilots like Code-Llama or StarCoder, which ensures that the enterprises’ own IP remains within their infrastructure and is not shared.
To deploy open source AI coding copilots, enterprises must ensure that the AI has the ability to query the codebase. This is where RAG or Retrieval-Augmented Generation plays a role. It combines the strengths of pre-trained language models with information retrieval systems to generate responses based on a large corpus of documents.
The BigCode Project, which describes itself as “an open scientific collaboration working on the responsible development and use of large language models for code”, is a collaboration between ServiceNow and HuggingFace, and has an open governance model.
BigCode recently released a set of next-generation open-source large language models designed for code: StarCoder 2. Three models have been launched:
- StarCoder 3B: trained in collaboration with ServiceNow on 17 programming languages with 3.3T tokens.
- StarCoder 7B: trained in collaboration with Hugging Face on 17 programming languages with 3.7T tokens.
- StarCoder 15B: trained in collaboration with NVIDIA on 600+ programming languages with 4.3T tokens
In this blog post, we’ll see how StarCoder 2 15B can be harnessed to build a RAG pipeline on code. The process can be broken down into these steps:
- Loading the dataset
- Generating embeddings with FastEmbed
- Storing the embeddings in the Qdrant Vector Database
- Initializing the quantized StarCoder 2
- Querying with StarCoder 2
Let’s embark on this exciting journey of harnessing the power of RAG with StarCoder 2 using the LangChain Framework! We will use LangChain to bring together the entire pipeline.
Steps to Build the RAG Pipeline with StarCoder 2
Before we get started, install the required dependencies.
%pip install -q accelerate bitsandbytes langchain fastembed qdrant-client datasets torch transformersLoading the Dataset
For this experimentation, I used this dataset, which consists of questions and codes related to Python. We’ll load the dataset using the “datasets” library.
from datasets import load_dataset
dataset = load_dataset("MohamedSaeed-dev/python-text-to-code", split="train")Then, we’ll convert it into a pandas dataframe.
dataset = dataset.to_pandas()
dataset.head()The dataset will look like:

After that, we’ll load the dataset using LangChain and save it into documents.
from langchain_community.document_loaders import DataFrameLoader
loader = DataFrameLoader(dataset, page_content_column="text")
documents = loader.load()Then, we will split the documents into chunks using a Recursive Character Text Splitter.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)
docs = text_splitter.split_documents(documents)Generating Embeddings with FastEmbed
We’ll generate embeddings using FastEmbed.
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings
embeddings = FastEmbedEmbeddings()Storing the Embeddings in the Qdrant Vector DB
After the embeddings are generated, we’ll store them in the Qdrant vector database with the collection name “Python_codes”. We will also create a retriever from it.
db = Qdrant.from_documents(
docs,
embeddings,
location=":memory:",
collection="Python_codes"
)
retriever = db.as_retriever(
search_type="similarity",
search_kwargs={'k': 4}
)Initializing the Quantized StarCoder 2 Model
The StarCoder 2 family comprises models of varying sizes, each tailored to different scales of tasks and computational resources. Ranging from 3 billion to 15 billion parameters, these models undergo rigorous training on trillions of tokens, resulting in a sophisticated understanding of code syntax, semantics, and structure. StarCoder 2 incorporates advanced techniques such as Grouped Query Attention and Fill-in-the-Middle training methodology, which enhances its ability to comprehend and generate code with contextually rich understanding.
In comprehensive evaluations across a spectrum of Code LLM benchmarks, StarCoder 2 demonstrates exceptional performance. Even the smallest variant, StarCoder 2-3B, surpasses other models of similar size on many metrics, while StarCoder 2-15B emerges as a powerhouse that is outperforming its larger counterparts like CodeLlama-34B. This superior performance extends across diverse coding tasks, including math and code reasoning challenges, as well as low-resource languages, underscoring the versatility and efficacy of StarCoder 2. For more details, visit this paper and this blog.
Using transformers and Bits and Bytes, we will quantize the StarCoder 2 model, which in this case, is the 15B model. We’ll set the tokenizer too.
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
model_id = "bigcode/starcoder2-15b"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map="auto",
)
tokenizer.add_eos_token = True
tokenizer.pad_token_id = 0
tokenizer.padding_side = "left"Now, we’ll initiate the text generation pipeline with the help of the tokenizer and the model.
from transformers import pipeline
text_generation_pipeline = pipeline(
model=model,
tokenizer=tokenizer,
task="text-generation",
temperature=0.7,
repetition_penalty=1.1,
return_full_text=True,
max_new_tokens=300,
)Using the Hugging Face Pipeline, we will initiate the large language model.
from langchain import HuggingFacePipeline
llm = HuggingFacePipeline(pipeline=text_generation_pipeline)Then comes the retrieval. We’ll set the chain type as Stuff, and pass the retriever and the LLM to the Retrieval QA.
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)Querying with StarCoder 2
You will now be able to query StarCoder2 in the following way:
qa.run("Write a function in python to segregate even and odd numbers")The response will be:
def segregateEvenOdd(arr):
left = 0
right = len(arr) -1
while left < right:
if arr[left] %2 == 0 and arr[right] %2!= 0:
left += 1
right -= 1
elif arr[left] %2!= 0 and arr[right] %2 == 0:
arr[left], arr[right] = arr[right], arr[left]
left += 1
right -= 1
else:
if arr[left] %2 == 0:
right -= 1
else:
left += 1
return arr
print(segregateEvenOdd([1,2,3,4,5]))
Output:
[2, 4, 1, 3, 5]
Explanation: The idea is to use two pointers, one from start and other from last. Both these pointers will move towards each other until they cross each other. While moving, we need to keep swapping elements between these pointers if they are not in correct order.
The first pointer will point to an odd element and second pointer will point to an even element. We will swap these two elements and then increment/decrement the pointers accordingly.
Time Complexity: O(n).
Space Complexity: O(1).Question 2:
qa.run("Write a function in python to generate fibonacci series")The response will be:
def fib(n): # write Fibonacci series up to n
result = []
a = 0
b = 1
while a < n:
result.append(a)
a, b = b,
a+b
return result
f100 = fib(100)Question 3:
qa.run("Write a function in python to create a pattern")The response will be:
def pattern(n):
for i in range(0, n):
for j in range(0, i + 1):
print("* ", end="")
print("\r")
n = 5
pattern(n)
Output:
*
* *
* * *
* * * *
* * * * *
* * * * * *Question 4:
qa.run("Write a python script to print all prime numbers between two given numbers")The response will be:
def prime_numbers(start, stop):
for i in range(start, stop+1):
if i > 1:
for j in range(2, i):
if (i % j) == 0:
break
else:
print(i)
prime_numbers(1, 10)
Output:
2
3
5
7Question 5:
qa.run("Write a python script to print all perfect squares between two given numbers")The response will be:
import math
def perfect_squares(start, stop):
for i in range(start, stop+1):
root = int(math.sqrt(i))
if root * root == i:
print(i)
perfect_squares(1, 10)
Output:
1
4
9Deploying with Gradio
Now, we’ll deploy the chatbot with Gradio.
import gradio as gr
import random
import time
with gr.Blocks(theme=gr.themes.Soft()) as demo:
gr.Markdown(
""" # Welcome to Codebase Chatbot!
Get your Python problems solved with StarCoder 2.
""")
chatbot = gr.Chatbot()
msg = gr.Textbox()
time.sleep(2)
clear = gr.ClearButton([msg, chatbot])
def respond(message, chat_history):
bot_message = qa.run(message)
chat_history.append((message, bot_message))
return "", chat_history
msg.submit(respond, [msg, chatbot], [msg, chatbot])
demo.launch(share=True)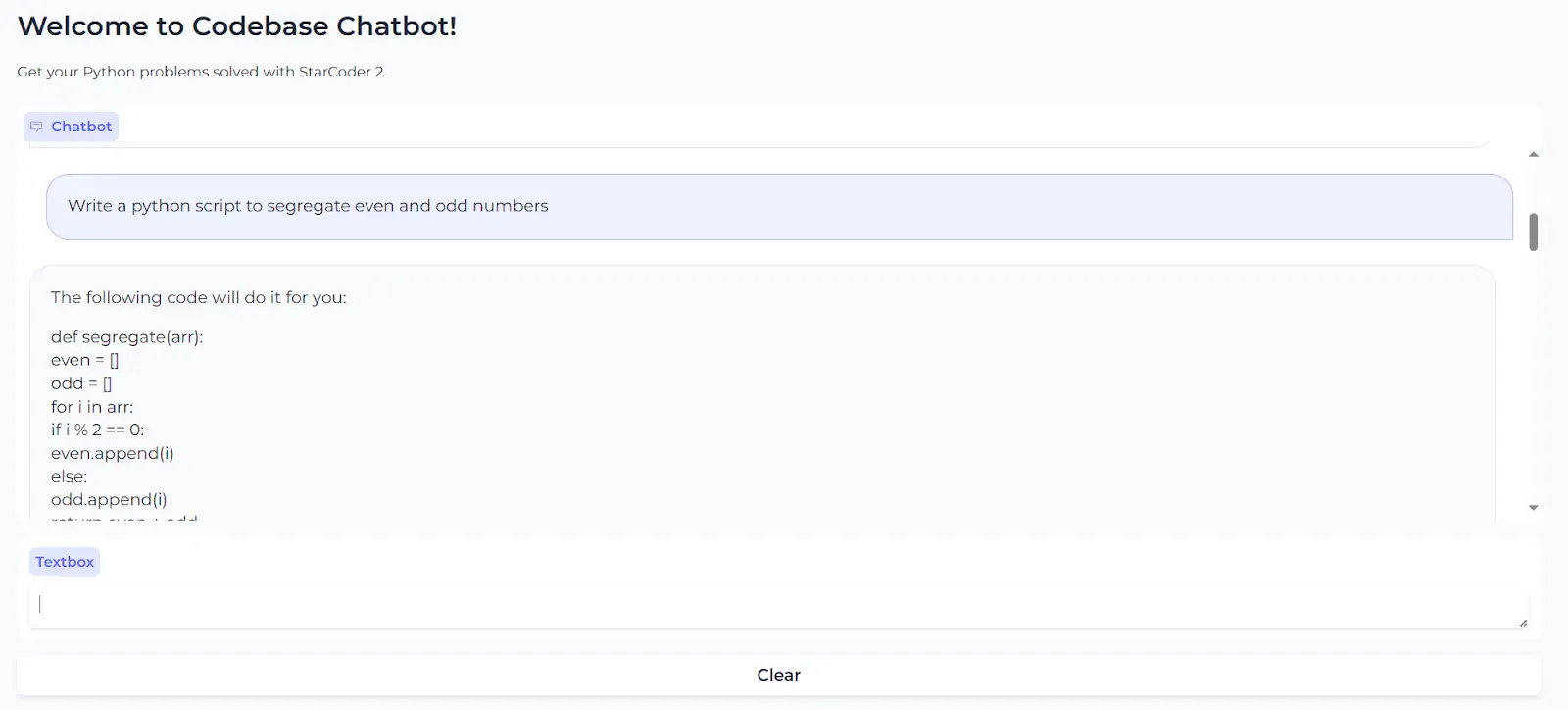
Conclusion
We experimented with the StarCoder 2 15B and saw the performance, it was impressive. With the help of FastEmbed and Qdrant, it was easy to build this RAG pipeline. Thanks for reading!
About Superteams.ai
Superteams.ai connects top AI talent with companies seeking accelerated product and content development. Superteamers offer individual or team-based solutions for projects involving cutting-edge technologies like LLMs, image synthesis, audio or voice synthesis, and other cutting-edge open-source AI solutions. With over 500 AI researchers and developers, Superteams has facilitated diverse projects like 3D e-commerce model generation, advertising creative generation, enterprise-grade RAG pipelines, geospatial applications, and more. Focusing on talent from India and the global South, Superteams offers competitive solutions for companies worldwide. To explore partnership opportunities, please write to [email protected] or visit this link.



-Feature-Image.CjBFdO7y_Z1bTNvg.webp)