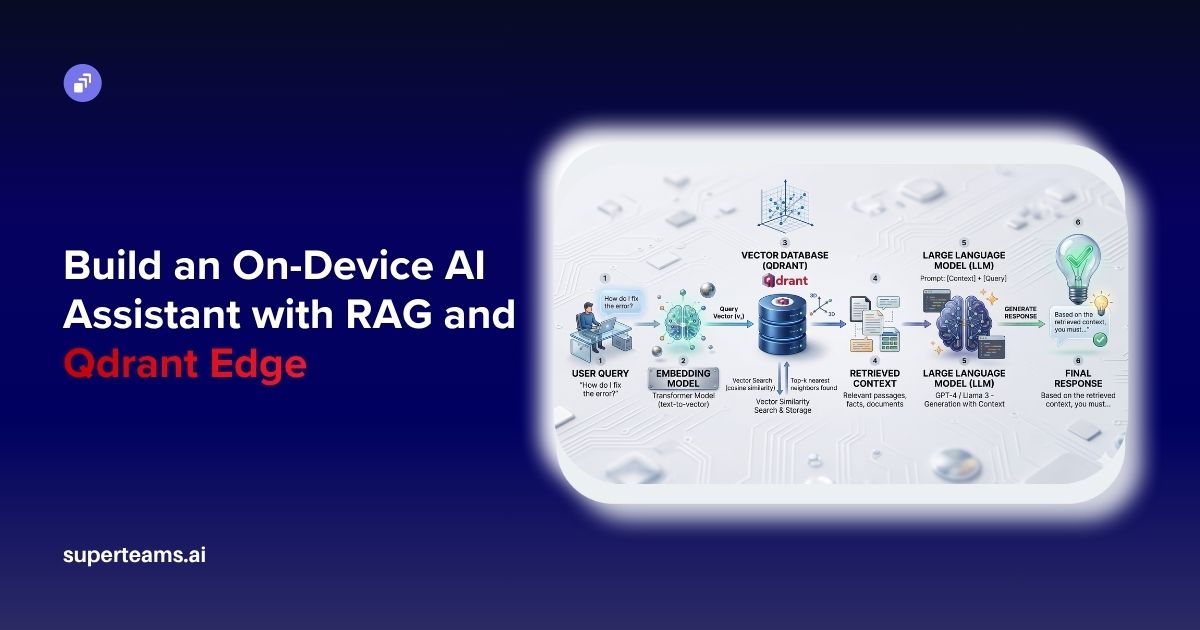
How to Generate Photorealistic Images from Text with the Next-Gen AI Framework PixArt-δ
This blog shows how to generate stunning advertising creatives with PixArt-δ.
.webp)
Introduction
Text-to-image generation models have been a game-changer. They have transformed image generation with the help of prompting. Many models have been introduced for this purpose, but they lack three major performance efficiencies: pixel dependency capturing, alignment between text and image, and high aesthetic quality assurance. OpenX Lab introduced PIXART-α as an answer to these challenges. It comes with variants like SDXL, SDXL LoRA, and SDXL LCM LoRA. OpenX Lab has since improved the model by introducing PIXART-δ, with its variants ControlNet and ControlNet LCM models.
Text-to-image synthesis offers numerous applications; here, we'll explore its use in generating images for an airplane crew member's training school and show how it can enhance advertising efforts on their website.
In this blog post, we'll delve into how PixArt-δ has developed strategies to address three key challenges in text-to-image synthesis and how it is meeting these challenges for advertisement-related image generation. But, first, let's familiarize ourselves with PIXART-α!
Fast Training of Diffusion Transformers with PIXART-α
PIXART-α is a Transformer-based text-to-image (T2I) diffusion model that represents an innovative approach to generating high-quality images from textual descriptions. Let’s take a look at its architecture.
Architecture
PIXART-α adopts the Diffusion Transformer (DiT) as its base architecture. The DiT architecture is specifically designed to handle the unique challenges of T2I tasks, which makes it well-suited for generating images from text descriptions. This is the basic architecture of PIXART-α. The model consists of Transformer blocks, which are the fundamental building blocks that process both textual and visual information. These blocks enable the model to effectively capture dependencies between words in the text and pixels in the image, which facilitates the generation of coherent and realistic images.

PIXART-α incorporates a multi-head cross-attention mechanism into each Transformer block. This mechanism allows the model to flexibly interact with the textual conditions extracted from the language model while processing image data. It helps align the textual descriptions with the corresponding image features by enhancing the quality of generated images.
The model utilizes adaptive layer normalization (adaLN) modules within each Transformer block. These modules enable the model to adaptively adjust the normalization parameters based on the input data by enhancing the flexibility and effectiveness of the model in handling different types of input conditions. It also incorporates re-parameterization techniques to improve the efficiency and scalability of the model. This involves initializing certain parameters in the model to specific values that facilitate training and inference, which leads to better performance and reduced computational complexity.
Training Strategy Decomposition
Stage 1: Pixel Dependency Learning: This stage focuses on understanding the intricate pixel-level dependencies within images. The goal is to generate realistic images by capturing the distribution of pixel-level features. The approach involves training a class-conditional image generation model using a pre-trained model as a starting point. By leveraging pre-trained weights and designing the model architecture to be compatible with these weights, the training process becomes more efficient.
Stage 2: Text-Image Alignment Learning: The primary challenge in transitioning from pre-trained class-guided image generation to text-to-image generation is achieving accurate alignment between textual descriptions and images. In this stage, a dataset consisting of precise text-image pairs with high concept density is constructed. This dataset helps the model learn to align textual descriptions with images effectively, thus improving the overall quality of generated images.
Stage 3: High-Resolution and Aesthetic Image Generation: In the final stage, the model is fine-tuned using high-quality aesthetic data for generating high-resolution images. By incorporating additional datasets and leveraging prior knowledge gained from the previous stages, the adaptation process in this stage converges faster, which results in higher-quality generated images.
Performance
When it comes to evaluating the quality of generated images, the key metric Frechet Inception Distance (FID) is used. FID measures the similarity between the distributions of real and generated images based on features extracted from a pre-trained neural network. PIXART-α achieves a low FID score, which indicates high fidelity in generating images that closely match real images. This model outperforms other T2I models.

In terms of training efficiency like GPU days and the total volume of training images, this model showed high fidelity with relatively lower resource consumption compared to other T2I models. In the evaluation of the alignment between generated images and textual descriptions, metrics such as attribute binding, object relationships, and overall compositionality are used. This model demonstrates its capability to accurately translate textual descriptions into visually coherent images. PIXART-α has a higher user satisfaction compared to other T2I models.
Now let’s understand PIXART-δ.
Fast and Controllable Image Generation with PIXART-δ
PIXART-δ is a cutting-edge text-to-image generation model designed to significantly enhance the efficiency and control of image synthesis from textual descriptions. It stands out by integrating Latent Consistency Models (LCM) to achieve a remarkable 4-step sampling acceleration by ensuring the generation of high-quality images at an impressively fast pace.

Let's delve into its key features:
Key Features
- Latent Consistency Models (LCM): PIXART-δ incorporates LCM to expedite the sampling process. LCM works by ensuring consistency in the latent space during the generation process by allowing the model to produce detailed images more quickly compared to previous models. This integration is pivotal for achieving high-quality outputs with significantly reduced computation time.
- Transformer-Based ControlNet: A specialized component designed for Transformer architectures, ControlNet allows users to have granular control over the generated images. This means that users can specify intricate details, from the overall composition down to the texture and style of minute elements by ensuring the output closely aligns with their vision.
- High-Resolution Image Generation: PIXART-δ excels in generating high-quality images by up to 1024 pixels by offering unprecedented detail and clarity. This capability is especially noteworthy for applications requiring fine-grained visual details, such as digital art, game development, and professional design.
- Fast Convergence: The model demonstrates rapid convergence in training by achieving satisfactory results within approximately 1,000 steps. This efficiency is important for quickly adapting to new datasets or evolving requirements in dynamic environments.
- "Sudden Converge" Phenomenon: PIXART-δ exhibits a unique "sudden converge" behavior, where it quickly adapts to training conditions by optimizing the generation process based on the complexity of the specified conditions. This feature enhances the model's responsiveness and versatility in producing varied image styles and compositions.
ControlNet Architecture
ControlNet-UNet
The ControlNet-UNet architecture is inspired by the classic UNet model, which is widely used for image segmentation tasks. UNet's architecture is fundamentally a convolutional neural network (CNN) that expands the typical structure with a symmetrically designed decoder path to perform precise localization. This makes it exceptionally suitable for tasks requiring detailed control over the pixel-level attributes of images.
How It Works:
- Encoder-Decoder Structure: The ControlNet-UNet incorporates an encoder-decoder structure, where the encoder progressively downsamples the input image to capture context and the decoder upsamples the encoded representation to generate a high-resolution output. Skipping connections between corresponding layers in the encoder and decoder facilitates the flow of fine-grained details.
- Control Mechanism: In the context of PIXART-δ, ControlNet-UNet is designed to manipulate specific aspects of the image generation process, such as style, texture, or color. This is achieved by modifying the encoded representation of the image before it is passed through the decoder. The exact nature of the control can vary, ranging from simple parameter adjustments to incorporating external data or constraints.

ControlNet-Transformer
The ControlNet-Transformer variant is built upon the Transformer architecture, which has been very successful in natural language processing and is increasingly used in image-related tasks.
How It Works:
- Attention Mechanism: ControlNet-Transformer utilizes an attention mechanism to focus on different parts of the image during the generation process. This enables the model to generate images with a high level of detail and coherence, as it can consider the entire context of the image.
- Control Through Prompts: In PIXART-δ, ControlNet-Transformer likely leverages text or command prompts to guide the image generation process. The model can interpret these prompts to apply specific controls over the aesthetics, content, and structure of the generated images.
Performance with 1024X

The 1024px results in PIXART-δ are impressive, which showcase the model's ability to generate high-resolution images with fine details and controllability. By leveraging the multi-scale image generation capabilities of PIXART-α, PIXART-δ achieves remarkable results even at the high resolution of 1024x1024 pixels. The generated images demonstrate fidelity to the input prompts while maintaining high visual quality and coherence. Developers can exert precise control over the geometric composition and visual elements of the generated images, which allows for customization and fine-tuning according to specific requirements.
How Is PIXART-δ Different from PIXART-α?
PIXART-δ differs from PIXART-α in several key aspects:
- Inference Speed: One of the most significant differences is in the inference speed. PIXART-δ leverages the Latent Consistency Model (LCM) to accelerate inference by enabling the generation of high-quality images in just 2-4 steps. This results in a remarkable improvement in speed compared to PIXART-α, which requires more steps for inference.
- Efficiency: PIXART-δ is designed to be more efficient in terms of both training and inference. The model is trainable on 32GB V100 GPUs within a single day, which makes it more practical for training on standard hardware setups. Additionally, PIXART-δ supports 8-bit inference, which allows it to generate high-resolution images within 8GB GPU memory constraints.
- ControlNet Integration: PIXART-δ integrates a ControlNet-like module, which provides fine-grained control over text-to-image diffusion models. This integration enhances the controllability and flexibility of PIXART-δ compared to PIXART-α.
- ControlNet-Transformer Architecture: PIXART-δ introduces a novel ControlNet-Transformer architecture, specifically tailored for Transformer-based models. This architecture seamlessly integrates ControlNet with the inherent characteristics of Transformers by ensuring explicit controllability alongside high-quality image generation.
- Overall Performance: While PIXART-α is recognized for its high-quality image generation at 1024px resolution, PIXART-δ not only maintains this level of quality but also significantly improves the speed and efficiency of the synthesis process. This makes PIXART-δ a more versatile and practical solution for text-to-image synthesis tasks, particularly in real-time applications where speed is important.
Generating Images with PIXART-α and PIXART-δ
In this blog post, we have experimented with PIXART-α’s SDXL Standard Version and PIXART-δ’s ControlNet LCM version. So, roll up your sleeves and get started with your Colab notebook Let’s see which model is generating the best images.
PIXART-α’s SDXL Standard Version
Install the dependencies.
!pip install -q diffusers transformers sentencepiece accelerateImport torch and PixArtAlphaPipeline from Diffusers.
import torch
from diffusers import PixArtAlphaPipelineLoad the ControlNet version model and load it to “CUDA”.
pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-XL-2-1024-MS", torch_dtype=torch.float16)
pipe = pipe.to('cuda')Pass the prompt, and observe the results.
Prompt 1:
prompt = "A real air hostess, airplane background, wearing red dress and hat, photorealistic"
pipe(prompt).images[0]Result:

Prompt 2:
prompt = "A real airplane crew member, man, white shirt and black tie, photorealistic"
pipe(prompt).images[0]Result:

Prompt 3:
prompt = "A real airplane pilot, woman in airplane, white shirt, airplane background, photorealistic"
pipe(prompt).images[0]Result:

PIXART-δ ControlNet LCM Version
Initiate the model.
pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", torch_dtype=torch.float16)
pipe = pipe.to('cuda')Pass the prompt and observe the results.
Prompt 1:
prompt = "A real air hostess, airplane background, wearing red dress and hat, photorealistic"
pipe(prompt).images[0]Result:

Prompt 2:
prompt = "A real airplane crew member, man, white shirt and black tie, photorealistic"
pipe(prompt).images[0]Result:

Prompt 3:
prompt = "A real airplane pilot, woman in airplane, white shirt, airplane background, photorealistic"
pipe(prompt).images[0]Result:

We saw that after comparing the two models, the latter gave better results.
Conclusion
We saw how easy it was to use PIXART-δ on the Colab notebook. The image results for the PIXART-δ ControlNet LCM version were better, more realistic than the PIXART-α SDXL Standard version. It is wonderful to see that PixArt-δ has built a training strategy by identifying the challenges faced by T2I models. Thanks for reading this blog!
References
https://arxiv.org/pdf/2310.00426.pdf
https://arxiv.org/pdf/2401.05252.pdf
https://github.com/PixArt-alpha/PixArt-alpha
About Superteams.ai
Superteams.ai connects top AI talent with companies seeking accelerated product and content development. Superteamers offer individual or team-based solutions for projects involving cutting-edge technologies like LLMs, image synthesis, audio or voice synthesis, and other open-source AI solutions. Superteams have facilitated diverse projects with over 500 AI researchers and developers like 3D e-commerce model generation, advertising creative generation, enterprise-grade RAG pipelines, geospatial applications, and more. Focusing on talent from India and the global South, Superteams offers competitive solutions for companies worldwide. To explore partnership opportunities, please write to founders@superteams.ai or visit this link.
Authors
Want to Scale Your Business with AI Deployed on your Cloud?