Introduction
In the era of AI-driven search, finding the right information goes far beyond matching a few keywords. Modern language models and smart assistants can understand natural language, but answering complex questions—quickly, accurately, and at scale—requires more than traditional search or static databases.
**Why does this matter now?
**With the explosive growth of large language models (LLMs) and retrieval-augmented generation (RAG) systems, businesses and engineers face a new challenge: how do you enable your systems to understand what users mean, not just what they say? The old ways of searching—using exact keywords or static lists—fall short when queries are open-ended, ambiguous, or require deeper reasoning.
For example, if you ask ChatGPT, “Who’s the leading researcher in battery recycling in Asia, and what conferences are they speaking at this year?”, a simple keyword search is almost useless. What you need is a way to connect the dots: matching the question’s intent (even if it uses new phrases) and reasoning over structured data about people, topics, and events.
This is where vector search and knowledge graphs come in. Each offers a different way to bridge the gap between user intent and data:
- Vector search finds semantically similar content using AI-powered embeddings, surfacing meaning beyond keywords.
- Knowledge graphs organize information as interconnected entities and relationships, supporting logical reasoning and explainable answers.
In this deep dive, we’ll break down how both approaches work, where each excels, and why combining them is becoming essential for the next wave of AI-powered search and decision systems.
Insight #1: Vector search delivers relevant results even if you never use the “right” words.
Knowledge graphs connect the dots, showing how facts, people, and events relate.
Vector Search
Vector search is a modern AI retrieval technique that finds information based on meaning, not just keywords. Instead of matching words, it compares high-dimensional numeric representations—called embeddings—that capture the semantic content of text, images, or audio.
What are Embeddings?
Embeddings are dense vectors created by AI models (like BERT, CLIP, or Whisper) that represent the essence and context of data. These vectors allow search systems to retrieve relevant results even when there’s no direct keyword overlap between the query and the content.
How are Different Data Types Encoded?
- Data Collection & Preprocessing: Gather and clean text, images, or audio to create a suitable dataset.
- Embedding Generation: Feed this data into a neural network trained to encode meaning and context into numeric vectors.
- Storage & Retrieval: Store these vectors in a specialized vector database for fast, semantic searching.
How is Similarity Measured?
Vector search uses mathematical functions to measure how closely two vectors (embeddings) relate. The most common similarity measures are:
- Cosine Similarity: Compares the angle between vectors—ideal for text.
- Euclidean Distance: Measures straight-line distance—useful for images or audio.
- Dot Product: Weighs both direction and magnitude—favored in deep learning.
- Manhattan Distance: Sums absolute differences—effective for sparse data.
These measures help AI systems surface the most semantically relevant results, even across different data types and languages.
How Vector Search Works: Algorithms, Query Types, and Storage
ANN Algorithms
Approximate Nearest Neighbor (ANN) algorithms power fast, scalable vector search by finding “close enough” matches instead of comparing every vector in the database. This approach massively speeds up search across millions or billions of vectors, with only a minor trade-off in precision—an ideal compromise for most semantic search, recommendation, or RAG applications.
Popular ANN Algorithms and Tools:
- HNSW: Builds a navigable small-world graph of vectors for high-recall, efficient search.
- IVF + PQ: Clusters vectors (IVF) and compresses them (PQ) to save memory and speed up computation.
- ScaNN: Google’s algorithm that blends partitioning, quantization, and re-ranking for large-scale search.
- FAISS: Meta’s library for flexible indexing, supporting CPUs and GPUs for massive datasets.
Data Modeling and Query Paradigms
Vector databases store information as dense vector arrays (embeddings) along with associated metadata (such as titles, tags, or timestamps) to enable efficient, filtered search.
Query Types:
- Nearest Neighbor: Finds the vector most similar to a query embedding.
- Multi-Vector Search: Uses multiple query vectors to capture broader intent and improve relevance.
- Filtering: Narrows search results using metadata constraints (e.g., by category or date).
These capabilities let vector search systems retrieve the most relevant results quickly, even in huge, high-dimensional datasets.
Storage, Indexing, and Space Requirements
Vector search systems need to balance speed, memory use, and storage cost—especially as datasets grow into the millions or billions of vectors. Much depends on how vectors are stored, indexed, and compressed.
Insight #2:
Numeric Precision & Memory Use in Vector Embeddings
1.Float32: 4 bytes per value (highest precision, more memory)
2.Float16: 2 bytes per value (half the memory, minor impact on accuracy)
3.Int8: 1 byte per value (most efficient, can reduce recall slightly)
Choosing the right numeric precision for your vector embeddings directly affects both memory usage and search performance.
Index Construction
Specialized data structures (like HNSW or IVF) organize and accelerate nearest neighbor search, often storing indexes in RAM for low-latency queries. Some systems use on-disk indexes (SSDs/NVMe), which scale to larger datasets but may add a bit of latency.
Metadata & Hybrid Storage
Metadata (titles, tags, categories) is stored separately from the vectors, enabling powerful filtering and sorting. In hybrid search setups (combining keyword and vector search), fast access to both vectors and metadata is crucial for best results.
Scaling and Distributed Vector Search
Sharding, Replication, and Distributed ANN
- Sharding splits large vector datasets across multiple servers, enabling horizontal scaling and better performance as data grows.
- Replication copies embeddings and indexes to several servers, boosting availability and reliability, though it requires managing data consistency.
- Distributed ANN (e.g., HNSW, IVF) lets each shard run its own fast, approximate search—great for large-scale RAG, personalization, or semantic search pipelines. While this preserves speed, no single shard has full dataset visibility, so results may be “good enough” rather than globally optimal.
Hot/Cold Data Separation
- Hot data (frequently accessed vectors/metadata) lives on fast storage (like SSDs) for real-time search.
- Cold data (rarely accessed) moves to slower, cheaper storage to save cost.
CPU/GPU Acceleration
- GPU acceleration speeds up vector search on large datasets, especially for brute-force or quantized operations.
- CPUs still excel for ANN indexes like HNSW, which benefit more from lots of RAM and multi-threading than pure GPU power.
Popular Vector Database Implementations
- Milvus: Cloud-native, hardware-optimized for large-scale, high-speed vector search.
- Qdrant: Scalable with advanced filtering; integrates well with AI/ML workflows.
- Pinecone: Fully managed and cloud-native, built for fast, scalable similarity search.
- Weaviate: Open-source, supports hybrid queries and AI-native semantic search.
These platforms handle billions of vectors and power use cases like semantic search, recommendations, and RAG.
Insight #3: In vector search, speed, accuracy, and memory use are always in balance—tune your system carefully to get the best results for your application.
Retrieval Quality, Accuracy, and Tradeoffs
Key Metrics:
- Precision: Proportion of retrieved results that are relevant.
- Recall: How many relevant results are returned.
- Recall@k: Relevant results in the top k.
ANN Tradeoffs
ANN algorithms trade a bit of accuracy for speed, with parameters like ef (HNSW) and nprobe (IVF) letting you balance recall versus latency.
Quantization
Compresses vectors (e.g., PQ, int8) to save space and speed up search—reducing memory at a slight cost to accuracy.
Handling Noise & Semantic Drift
- Vector search can sometimes surface irrelevant results or shift meaning as models/data change.
- Best practices:
- Regularly re-embed and re-index with updated models.
- Use hybrid search (vector + keyword/metadata filters).
- Re-rank top results for precision.
Managing these tradeoffs is crucial for consistent, production-grade retrieval.
Tutorial
Let’s use ChromaDB for vector storage and Sentence-Transformers to create, store, and retrieve embeddings.
1. Install and Set Up
First, install the required libraries:
pip install chromadb sentence-transformers2. Insert Data
Embed your text data and store it in ChromaDB for semantic retrieval:
from sentence_transformers import SentenceTransformer
import chromadb
# 1. Load embedding model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# 2. Init Chroma (in-memory for simplicity)
client = chromadb.Client()
collection = client.create_collection(name="docs")
# 3. Extended dataset - 20 short factual paragraphs
texts = [
"Marie Curie was a physicist and chemist who conducted pioneering research on radioactivity in Paris.",
"Ada Lovelace is regarded as one of the first computer programmers for her work on Charles Babbage's analytical engine.",
"Alan Turing developed the concept of a theoretical computing machine and helped crack the Enigma code during WWII.",
"Nelson Mandela served as the first democratically elected president of South Africa and fought against apartheid.",
"Mahatma Gandhi led India to independence through nonviolent civil disobedience.",
"Martin Luther King Jr. was a civil rights leader who promoted equality through peaceful protest in the United States.",
"The city of Kyoto in Japan is famous for its ancient temples, gardens, and traditional tea ceremonies.",
"Machu Picchu is a 15th-century Inca citadel located in the Andes Mountains of Peru.",
"The Colosseum in Rome is an ancient amphitheater and one of the greatest works of Roman architecture.",
"The Great Wall of China was built over centuries to protect Chinese states from invasions.",
"The Eiffel Tower in Paris was completed in 1889 and has become a global symbol of France.",
"The Taj Mahal in India is a white marble mausoleum built by Mughal emperor Shah Jahan.",
"Isaac Newton formulated the laws of motion and universal gravitation.",
"Galileo Galilei made foundational contributions to modern physics and astronomy.",
"The moon landing in 1969 by Apollo 11 was the first time humans set foot on the Moon.",
"Wright brothers invented and flew the first successful motor-operated airplane in 1903.",
"Alexander Fleming discovered penicillin, the first widely used antibiotic.",
"Florence Nightingale is known as the founder of modern nursing.",
"Leonardo da Vinci was a Renaissance polymath known for his art, science, and engineering insights.",
"Charles Darwin introduced the theory of evolution by natural selection in his book 'On the Origin of Species'."
]
ids = [str(i) for i in range(1, len(texts) + 1)]
# 4. Add to Chroma
embeddings = model.encode(texts).tolist()
collection.add(ids=ids, documents=texts, embeddings=embeddings)
# 5. Search helper
def search(query, k=3):
q_emb = model.encode([query]).tolist()
results = collection.query(query_embeddings=q_emb, n_results=k)
return results["documents"][0]3. Query and Explore
Now you can search the vector database by embedding a query and finding semantically similar text:
queries = [
"Name three scientists whose discoveries fundamentally changed how we understand the natural world",
"Name two influential leaders who played a major role in civil rights or independence movements.",
"Which landmarks are UNESCO World Heritage Sites or famous historical monuments?"
]
# Run searches
for q in queries:
print(f"\n🔍 Query: {q}")
for doc in search(q):
print(" -", doc)Outputs
🔍 Query: Name three scientists whose discoveries fundamentally changed how we understand the natural world
- Galileo Galilei made foundational contributions to modern physics and astronomy.
- Charles Darwin introduced the theory of evolution by natural selection in his book 'On the Origin of Species'.
- Isaac Newton formulated the laws of motion and universal gravitation.
🔍 Query: Name two influential leaders who played a major role in civil rights or independence movements.
- Martin Luther King Jr. was a civil rights leader who promoted equality through peaceful protest in the United States.
- Mahatma Gandhi led India to independence through nonviolent civil disobedience.
- Nelson Mandela served as the first democratically elected president of South Africa and fought against apartheid.
🔍 Query: Which landmarks are UNESCO World Heritage Sites or famous historical monuments?
- The city of Kyoto in Japan is famous for its ancient temples, gardens, and traditional tea ceremonies.
- The Taj Mahal in India is a white marble mausoleum built by Mughal emperor Shah Jahan.
- The Colosseum in Rome is an ancient amphitheater and one of the greatest works of Roman architecture.Use Cases of Vector Search in RAG and AI Applications
Vector search powers modern AI by retrieving meaning-based matches—crucial for Retrieval-Augmented Generation (RAG) pipelines, recommendation engines, and smart assistants.
- **RAG Example:
**When a user asks, “What are the latest developments in lithium-ion battery recycling?”, a RAG system splits a research corpus into paragraphs, embeds them, and retrieves only the most relevant chunks—even if the user’s phrasing never appears in the original text. - **E-commerce Example:
**Online stores use vector search to recommend products by matching your preferences (from reviews, browsing, and purchase history) to product descriptions—surfacing the best options, even if you never type the exact keywords
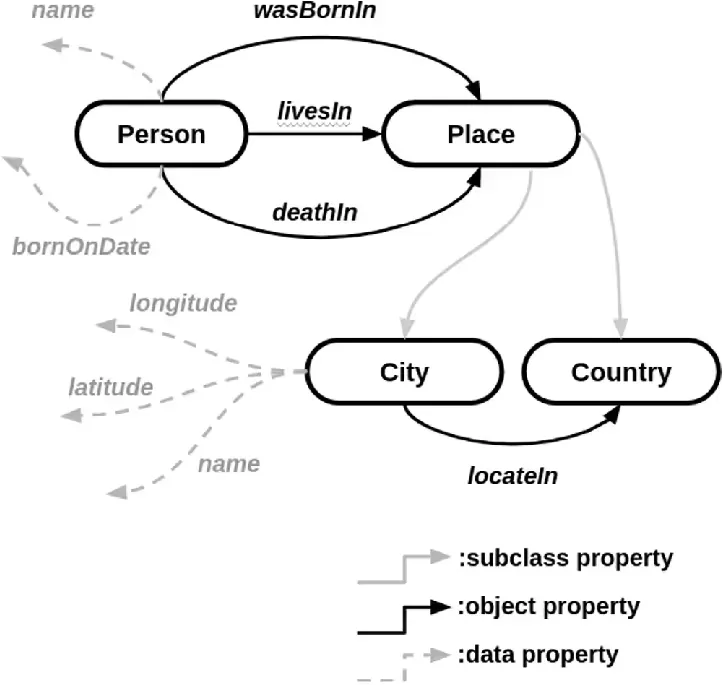
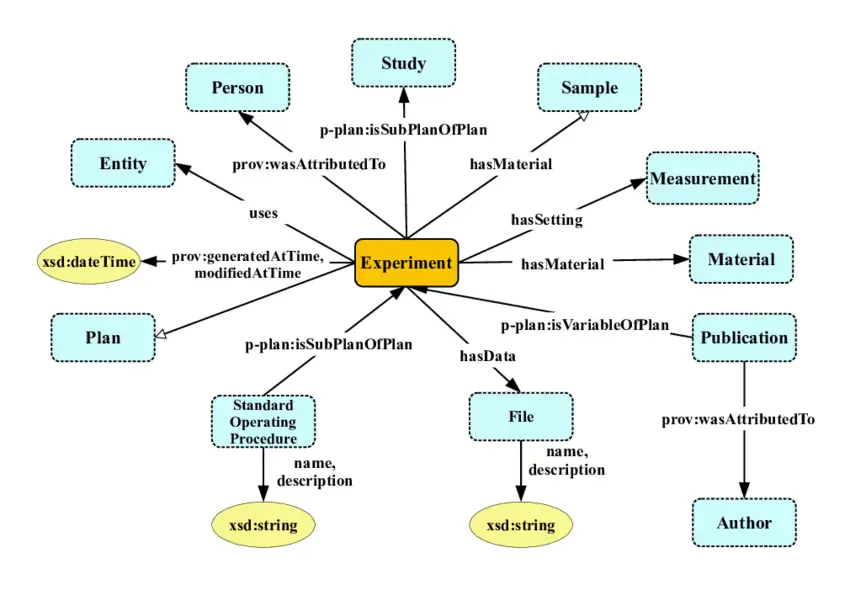
Knowledge Graphs: Concepts and Architecture
A knowledge graph (sometimes called a semantic network) is a powerful way to organize information as a network of interconnected entities and their relationships. These graphs help systems reason, answer complex questions, and trace how facts relate—making them a backbone for explainable AI.
Key Components:
- Nodes: Represent real-world entities, such as people, products, organizations, or events.
- Edges: Show relationships between nodes (e.g., “works at”, “located in”, “related to”).
- Properties: Additional details about nodes or edges (like a person’s age or a relationship’s start date).
Graph Models: Labeled Property Graphs vs. RDF Triples
- Labeled Property Graphs:
- Nodes and edges are both labeled and can have multiple key-value properties.
- Flexible and ideal for modeling complex, richly-attributed networks, such as social graphs or enterprise knowledge systems.
- RDF Triples:
- Information is stored as simple subject-predicate-object triples (e.g., “Ada Lovelace” – “worked on” – “early computers”).
- Well-suited for semantic web, interoperability, and data integration across diverse sources.
Schemas, Ontologies and Semantics
Schemas act as blueprints, specifying what kinds of nodes, edges, and properties are allowed in the graph. Examples: Entity-Relationship (ER) diagrams for conceptualizing structure, JSON-LD schemas for encoding data.
Insight #4: Why does schema matter? A well-designed schema is the foundation of a useful knowledge graph—it ensures data is organized, meaningful, and queryable for both humans and machines.
Types of schema:
- Entity-Relationship (ER) schema is used to visualize and specify nodes, relationships, and their allowed properties.
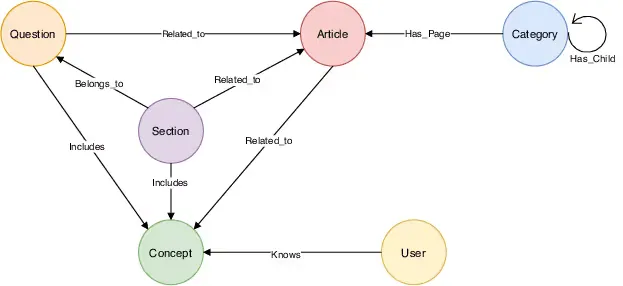
- RDF/OWL Ontology Schema is a type of schema that specifies classes, properties, and constraints, often as subject-predicate-object triples.
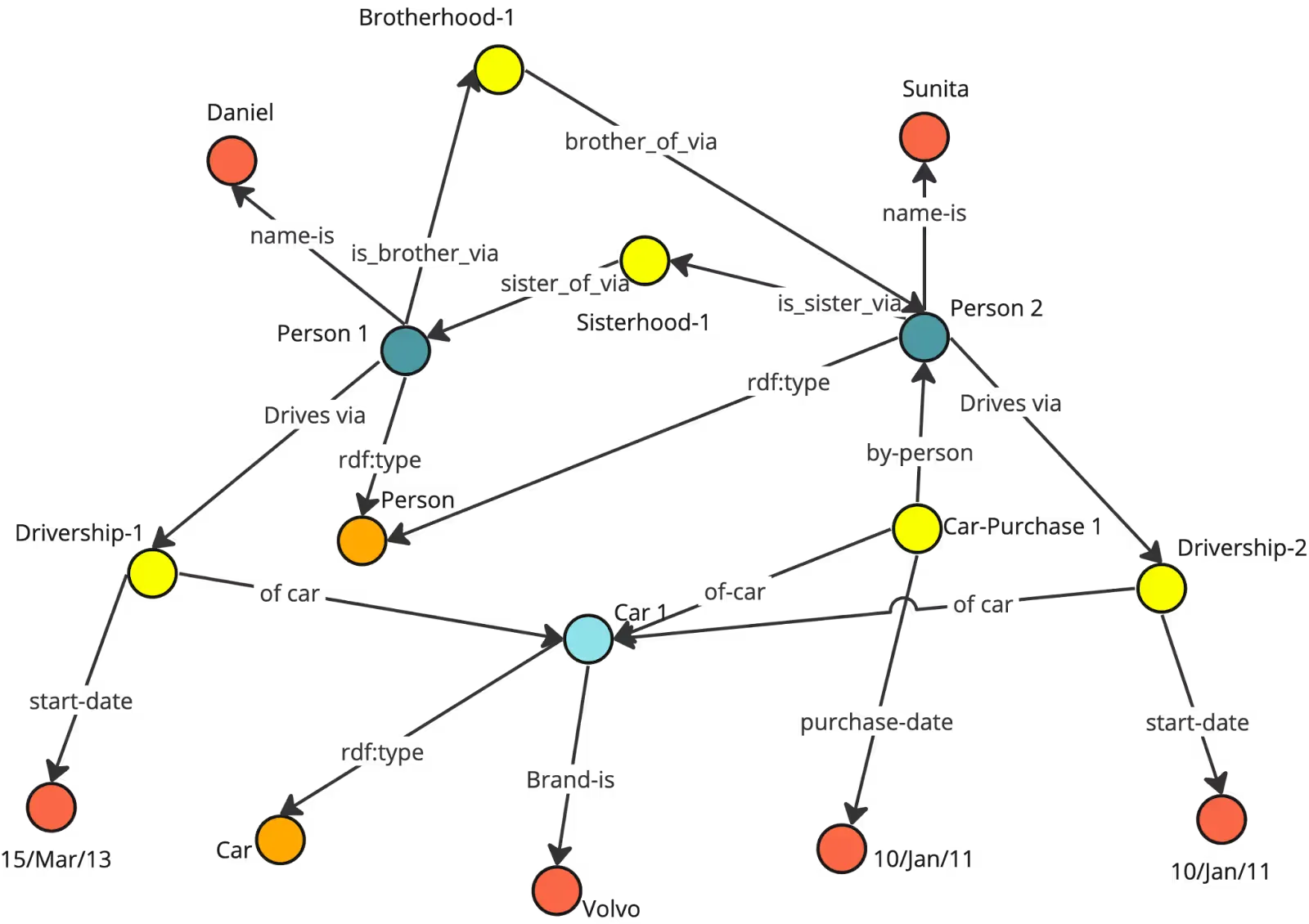
- Property Graph (Labeled Property Graph) Schema, in which entities and relationships are annotated using standardized types and attributes, often encoded in JSON-LD.
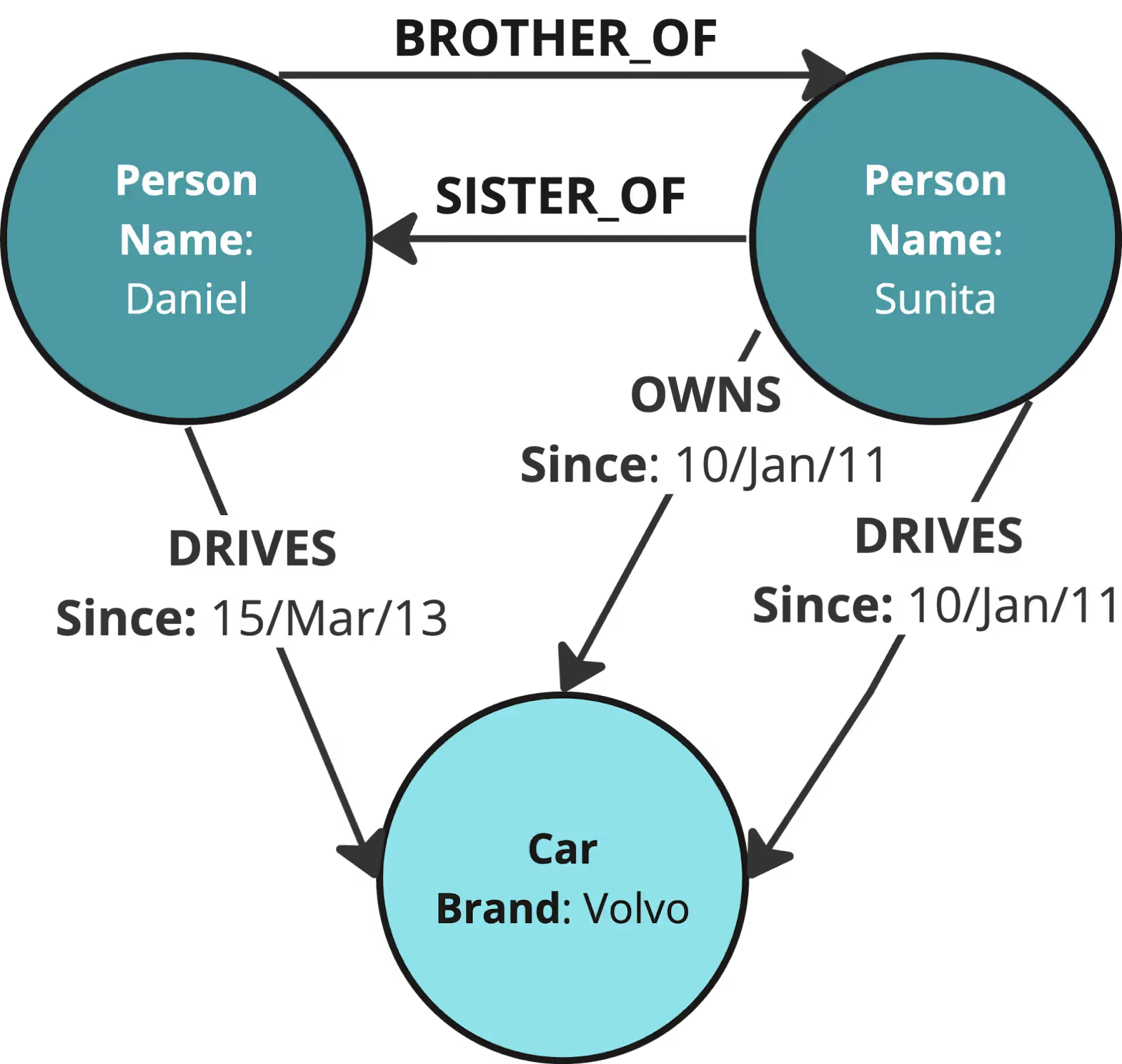
Ontologies provide formal definitions, hierarchies, and constraints for entities and relationships within a specific domain (e.g., medicine, finance).
Types of ontologies:
- Domain Ontologies capture concepts, properties, and relationships relevant to an industry or area.
- Foundational Ontologies are used for establishing basic categories like “Object,” “Event,” or “Agent,” setting a common ground for domain ontologies to build upon.
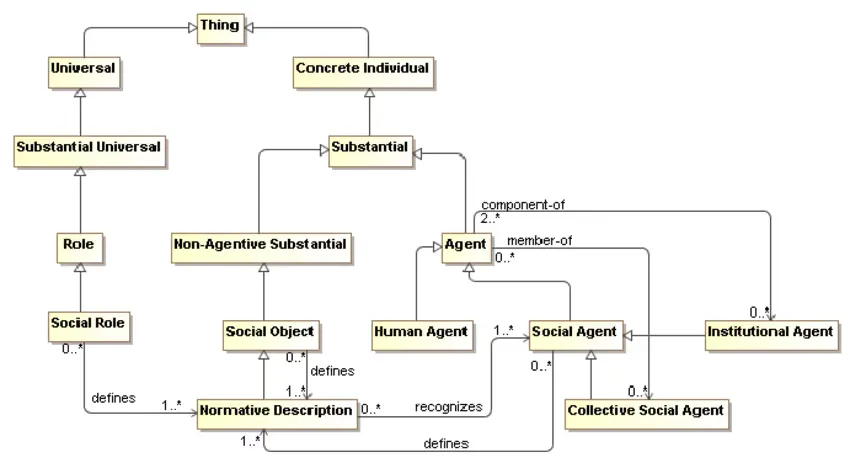
Task Ontologies: structure the knowledge around repeatable operations within or across domains.
Semantics ensure the graph is meaningful for both humans and machines.
Types of semantics:
- Structural Semantics: The basic level where nodes represent entities and edges represent relationships, defining the fundamental structure of the graph.
Domain Semantics: Provides rich, domain-specific meaning by aligning entities and relationships with formal ontologies or controlled vocabularies.
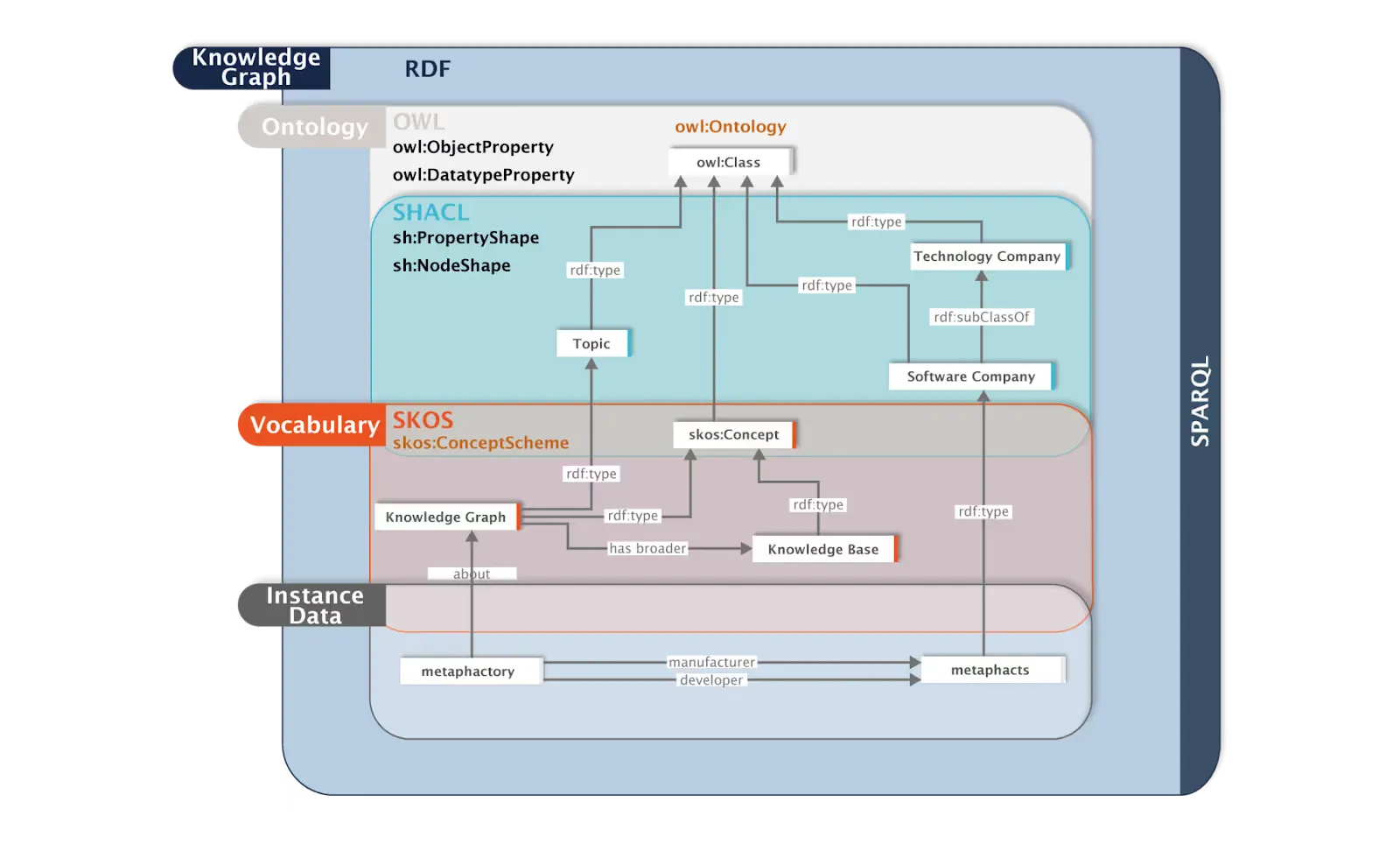
- Logical Semantics: Encodes rules, constraints, and inferencing logic within the graph, allowing automated reasoning and deduction of new facts.
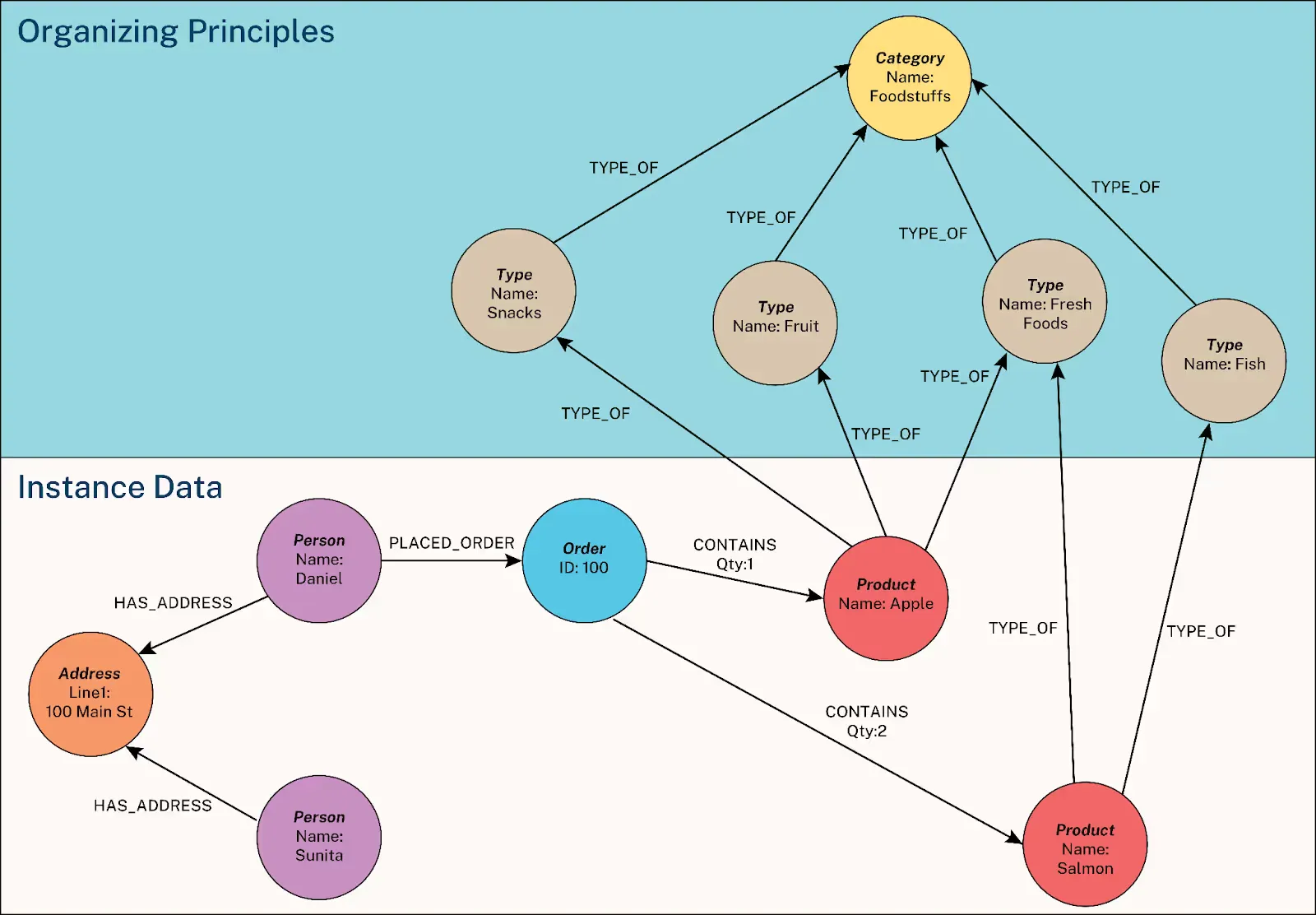
Data Modeling and Query Paradigms
**Expressive Queries
**Knowledge graphs excel at supporting pattern-based queries that can traverse multiple relationships, filter by type, and leverage schema logic—making them ideal for complex reasoning.
Key Query Capabilities
- Multi-hop Traversals: Explore paths that cross several nodes to reveal indirect or deep relationships within the data.
- Pattern Matching: Use query languages to find complex substructures, not just direct links.
- Filtering & Aggregation: Filter results by node or edge attributes and compute aggregates (like the number of papers per author).
Common Query Languages
Cypher: A user-friendly language for labeled property graphs, visually mirroring graph structures and supporting advanced traversals.
MATCH (a:Person)-[:WORKS_FOR]->(c:Company) WHERE c.name = "Acme Corp" RETURN a.name
SPARQL: Designed for querying RDF graphs, especially useful in semantic web and data integration contexts.
SELECT ?person
WHERE {
?person rdf:type :Employee.
?person :worksFor :AcmeCorp.
}
GraphQL: Open-source query language for APIs that lets clients request exactly the data they need, solving the problems of over-fetching and under-fetching common with REST APIs.
query {
author(id: "A123") {
name
affiliation {
name
country
}
publications {
title
year
coAuthors {
Name
}}}}Relationship Modeling, Constraints, and Inference
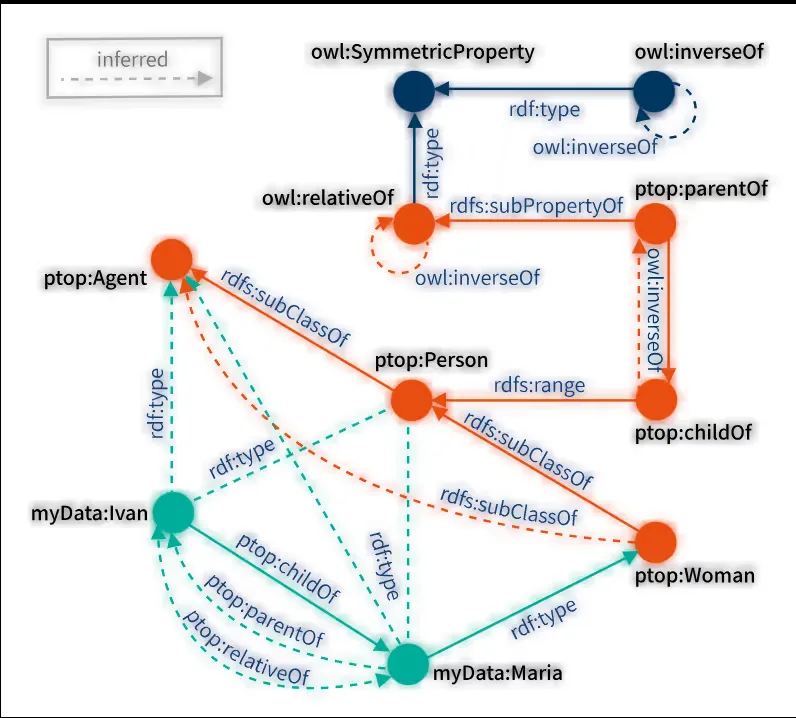
In knowledge graphs, relationships are explicitly defined through edges connecting entities. Each edge has a type, direction, and properties (like timestamps or roles), capturing real-world associations and hierarchies. Entities can participate in multiple relationships simultaneously.
Constraints ensure data quality and enforce rules:
- Type constraints: Limit which properties nodes/edges can have.
- Cardinality constraints: Restrict the number of relationships.
- Property constraints: Define valid property values.
Inference lets the graph deduce new facts from existing data using logical rules or ontologies (e.g., knowing “Every manager is an employee” and “Alice is a manager” lets the system infer “Alice is an employee”).
Storage, Indexing, and Space Requirements
Knowledge graphs use specialized storage structures to support efficient traversals, filtering, and reasoning. Two common representations are:
- Edge lists: Store relationships as (source, target, label) tuples.
- Adjacency matrices: Map node connections for fast, parallel analysis.
Graph compression (like dictionary or delta encoding, and bit-vectors) reduces space, speeds up queries, and is crucial for very large or RDF-based graphs.
Indexes improve query speed:
- Traversal indexes: Speed up neighbor lookups and multi-hop traversals.
- Property indexes: Accelerate filtering on node/edge attributes.
- Path indexes: Precompute common paths for faster queries.
Schema Evolution and Cost of Updates
Knowledge graphs offer flexible schemas but updating them (adding new types, relationships, or updating ontologies) can introduce complexity and require re-annotation or costly reindexing, especially in compressed or indexed systems. Tools like SHACL and OWL help enforce integrity but also add to update overhead.
Insight #5: The real power of a knowledge graph comes from well-modeled relationships and strong constraints—they turn raw data into a trustworthy, reasoning-friendly network that delivers accurate answers, not just connections.
Scaling Knowledge Graphs
As knowledge graphs grow to billions of nodes and edges, distributing them across multiple machines becomes essential to maintain fast, reliable queries and robust data consistency.
Partitioning Strategies
- Vertex-cut: Spreads nodes across machines, duplicating edges if needed—reduces node load per server but can slow traversals.
- Edge-cut: Divides edges, keeping related node data local—simple but may overload servers with popular nodes.
- Hybrid approaches: Combine both methods using algorithms to balance storage and minimize cross-partition queries.
Partitioning quality directly affects performance, scalability, and fault tolerance.
Distributed Traversal and Algorithms
Complex queries often cross partitions. Systems coordinate this with techniques like message passing (sharing partial results), query shipping (moving the query itself), or caching common subgraphs.
Consistency and Transaction Models
- ACID: Guarantees strict transaction safety for mission-critical workloads (used by Neo4j Fabric, TigerGraph).
- BASE: Prioritizes availability and scalability, accepting temporary inconsistencies—suitable for analytical or read-heavy loads (e.g., Amazon Neptune).
Failure Recovery
Replication, consensus protocols (like Raft), and checkpointing help recover quickly from node or network failures, ensuring resilience and minimizing data loss.
Examples of Distributed Graph Databases
- Neo4j Fabric: Horizontal scaling with strong transaction guarantees.
- TigerGraph: Parallel, high-performance analytics with full ACID support.
- Amazon Neptune: Managed, cloud-native, flexible for RDF and property graphs.
FalkorDB: Open-source, Redis-compatible, optimized for real-time distributed analytics.
Retrieval Quality, Accuracy, and Tradeoffs
Knowledge graphs excel at delivering structured, explainable, and semantically precise answers by modeling data explicitly. But, as with any system, there are tradeoffs—especially when dealing with incomplete or evolving data.
- Semantic Precision: Every entity and relationship is typed and scoped, minimizing ambiguity. Queries yield results that are fully traceable—crucial for fields like finance or healthcare, where every answer must be justified.
- Path Accuracy: Multi-hop queries rely on well-modeled and complete relationships; missing or noisy edges can impact answer quality.
Handling Ambiguity: Knowledge graphs reduce confusion by enforcing clear types and metadata, but ambiguous or incomplete data still pose challenges. Techniques like schema-based inference and external linking help fill gaps but add complexity.
Tutorial
You can use FalkorDB to quickly create and query a simple graph of people, places, and events.
1. Install and Set Up
Install the FalkorDB Python client:
pip install falkordb
To launch FalkorDB with a browser interface using Docker:
$docker run -p 6379:6379 -p 3000:3000 -it --rm -v ./data:/var/lib/falkordb/data falkordb/falkordb:edge2. Insert Data
Create nodes and relationships to represent people, cities, and events:
from falkordb import FalkorDB
# Connect to FalkorDB (adjust host/port if needed)
db = FalkorDB(host="localhost", port=6379)
g = db.select_graph("General-Graph")
# Create nodes
g.query("""
CREATE
(:Person {name: 'Alice', age: 34}),
(:Person {name: 'Bob', age: 29}),
(:City {name: 'Kyoto', country: 'Japan'}),
(:City {name: 'Lima', country: 'Peru'}),
(:Event {name: 'AI Conference 2025'})
""")
# Create relationships
g.query("""
MATCH (alice:Person {name:'Alice'}), (bob:Person {name:'Bob'}),
(kyoto:City {name:'Kyoto'}), (lima:City {name:'Lima'}),
(ai_conf:Event {name:'AI Conference 2025'})
CREATE
(alice)-[:LIVES_IN]->(kyoto),
(bob)-[:LIVES_IN]->(lima),
(alice)-[:FRIEND_OF]->(bob),
(alice)-[:ATTENDS]->(ai_conf)
""")3. Query and Explore
Retrieve data by matching patterns in the graph with Cypher-like queries:
# People living in Kyoto
res = g.query("MATCH (p:Person)-[:LIVES_IN]->(c:City {name:'Kyoto'}) RETURN p.name")
print("People in Kyoto:", [row[0] for row in res.result_set])
# Friends of Alice
res = g.query("MATCH (a:Person {name:'Alice'})-[:FRIEND_OF]->(f:Person) RETURN f.name")
print("Friends of Alice:", [row[0] for row in res.result_set])
# Events attended by Alice
res = g.query("MATCH (a:Person {name:'Alice'})-[:ATTENDS]->(e:Event) RETURN e.name")
print("Events Alice attends:", [row[0] for row in res.result_set])
Outputs
People in Kyoto: ['Alice']
Friends of Alice: ['Bob']
Events Alice attends: ['AI Conference 2025']Use Cases of Knowledge Graphs in RAG and AI Applications
- **Healthcare Q&A:
**When a doctor asks, “What are the approved drugs for treating pediatric epilepsy and their most recent clinical trial outcomes?”, a RAG system can use a knowledge graph to return not just a list of drug names, but their relationships to specific conditions, linked directly to trial records, regulatory approvals, and expert-authored guidelines—making answers both precise and fully traceable.
**Financial Compliance & Fact-Checking:
**A financial analyst asks, “Has Company A been acquired by another firm in the past five years, and what are its current major subsidiaries?” Instead of sifting through pages of filings, a RAG assistant queries a knowledge graph to provide a clear acquisition chain and subsidiary structure, all sourced from regulatory filings and news, ensuring answers are accurate and auditable.
Direct Comparison: Vector Search vs. Knowledge Graphs
Vector search and knowledge graphs are both essential to modern AI retrieval, but they’re optimized for different needs.
Data Representation & Indexing
- Vector Search: Uses high-dimensional embeddings for text, images, or other content; indexes (HNSW, IVF, PQ) are optimized for speed and scale. Updates often require re-indexing if embeddings change.
- Knowledge Graphs: Store data as nodes (entities) and edges (relationships), clearly typed and linked to ontologies. Indexes are designed for traversal and can be updated locally, making them better for evolving, highly structured domains.
Querying & Expressiveness
- Vector Search: Excels at finding semantically similar content—perfect for natural language search, recommendations, and open-ended queries. However, it lacks support for complex logic, path queries, or deep filtering.
- Knowledge Graphs: Shine at structured, multi-hop, and rule-based queries using languages like Cypher or SPARQL. Great for precise questions, reasoning, and queries that follow explicit relationships or require explainability.
Scalability & Performance
- Vector Search: Scales easily in distributed/cloud environments; designed for low-latency, high-throughput retrieval, especially with GPU support. However, large embeddings and re-ranking can create bottlenecks.
- Knowledge Graphs: Can scale to billions of relationships, but complex queries or deep traversals may introduce latency. Partitioning and caching are key for distributed performance, but design is more complex than vector sharding.
Precision, Recall & Retrieval Quality
- Vector Search: Delivers high recall—good at surfacing “close enough” results, even when the wording differs. Quality depends on embedding model, chunking, and ANN settings.
- Knowledge Graphs: Delivers high precision—every result is type-safe, explainable, and grounded in explicit relationships, minimizing false positives.
Handling Ambiguity & Drift
- Vector Search: May confuse unrelated concepts (e.g., “Java” language vs. island); sensitive to drift as language evolves.
- Knowledge Graphs: Strong at disambiguation, as entities are clearly typed and contextualized.
Security, Compliance & Auditability
- Vector Search: Good for index-level isolation but offers limited fine-grained controls or auditability, and PII removal is challenging.
- Knowledge Graphs: Natively support row- and edge-level permissions, full data lineage, and easier compliance with regulations (e.g., PII tracking and deletion).
Ecosystem & Tooling
- Vector Search: Rapidly growing open-source tools (Milvus, Qdrant, Pinecone, Weaviate); integrates easily with ML frameworks and AI pipelines.
Knowledge Graphs: Mature platforms (Neo4j, TigerGraph, Amazon Neptune); rich in visualization, monitoring, and schema management.
Insight #6: Bottom line: Use vector search for broad, meaning-based retrieval at scale. Use knowledge graphs when you need structured, explainable, and auditable answers. For many modern AI and RAG systems, the most powerful approach combines both.
Hybrid and Future Approaches
The strengths of vector search and knowledge graphs are deeply complementary, and many advanced retrieval systems now combine both to improve accuracy, explainability, and flexibility—especially in Retrieval-Augmented Generation (RAG) pipelines.
Graph-Augmented Vector Search and Vice Versa
Rather than relying solely on embedding proximity, graph-augmented retrieval overlays symbolic or knowledge-based edges on top of vector spaces. This “semantic compression” technique diversifies semantic coverage and enables multi-hop, context-aware search, often outperforming standard top‑k ANN in both relevance and diversity.
Conversely, leading graph database systems like Neo4j and TigerGraph have begun to embed vector search natively within the graph itself. This integration allows for seamless hybrid queries where vector similarity feeds directly into graph traversal and filtering logic—uniting performance and expressive access in a single framework.
Neural-Symbolic Retrieval and Knowledge-Infused RAG
Hybrid frameworks such as HybridRAG and GraphRAG use a two-stage approach, combining initial vector-based recall with subsequent graph-based constraint filtering or traversal. In practical applications, such as financial question answering, HybridRAG has achieved better context accuracy and answer quality than systems that use either vectors or graphs alone.
Other approaches, such as SymRAG, introduce adaptive query routing that dynamically chooses whether to apply neural (vector) or symbolic (graph) retrieval, or both, depending on query complexity and system load. This dynamic orchestration enables strong accuracy while optimizing resource utilization.
Emerging Standards and Research Directions
Ongoing academic research is formalizing graph-augmented retrieval as a principled approach, with particular focus on techniques like submodular optimization and embedding neighbor graphs over vector spaces to provide richer context exploration. There’s also growing interest in vector-enhanced graph engines and federated or hypergraph-based architectures that blend embeddings and triples within a shared structure—ideal for open-source RAG frameworks and semantically aware AI pipelines.
Insight #7: The future is hybrid. The most powerful AI systems will combine the nuance of vector search with the reasoning of knowledge graphs, unlocking richer context, more relevant answers, and a new standard for intelligent retrieval.
Conclusion
The worlds of vector search and knowledge graphs are converging—and organizations that master both will have a clear advantage in the new era of AI-driven search, reasoning, and RAG. But designing, building, and deploying these hybrid retrieval pipelines in production is no small feat. From data modeling and embedding optimization to graph design, query engineering, and seamless integration with LLMs, each layer introduces new technical challenges and real-world trade-offs.
This is where Superteams comes in.
At Superteams, we help companies go beyond the hype:
We design, build, and deploy hybrid vector–graph pipelines tailored to your use case: whether it’s advanced enterprise search, retrieval-augmented generation, smart assistants, or next-generation recommendation engines. Our engineers work alongside your team to:
- Choose the right mix of vector and graph technology for your needs.
- Architect scalable, maintainable retrieval and reasoning systems.
- Optimize for speed, explainability, and business value.
- Deliver end-to-end solutions that move smoothly from prototype to production, no matter your scale.
If you’re ready to build the next generation of intelligent search or RAG pipelines—without reinventing the wheel—let’s talk.
-Feature-Image.CjBFdO7y_Z1JlSjK.webp)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}