Retrieval Augmented Generation (RAG) has mitigated the challenges of Large Language Models’ knowledge limitation by reducing hallucinations, incorporating external data, and enhancing contextual understanding. It is clear that RAG has made LLMs efficient, but when it comes to domain-specific RAG applications, we also need fine-tuning. Combining fine-tuning with a RAG pipeline can overcome the challenges faced by employing the RAG method alone.
In this blog post, we will build an advanced RAG application by fine-tuning Gemma 7B on a medical dataset. Let’s get started.
Fine-Tuning + RAG: An Efficient Method for Domain-Specific Applications
Before we get started, let’s see our torch version.
%pip install -q torch
torch.__version__The torch version is:
'2.2.1+cu121'To fine-tune the Gemma 7B model, we’ll use “Unsloth”. Unsloth makes fine-tuning and training faster. It supports SFT, LoRA, and DPO training. It also converts the model to the GGUF model type with desired quantization by leveraging Llama.cpp. We’ll now install Unsloth according to our torch version.
%pip install "unsloth[colab-new] @git+https://github.com/unslothai/unsloth.git"
%pip install --no-deps xformers trl peft accelerate bitsandbytesTo not interrupt the process of importing and exporting of the model, log into the Hugging Face Hub.
%pip install -q ipywidgets huggingface_hub
from huggingface_hub import notebook_login
notebook_login()Fine-Tuning Gemma 7B
Using Unsloth, start the fine-tuning of the model.
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "google/gemma-7b",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj","up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = True,
random_state = 3407,
use_rslora = False,
loftq_config = None,
)To fine-tune we chose the medical_meadow_alpaca dataset from Hugging Face. This dataset contains inputs and outputs about allergies, the immune system, and other common illnesses that we usually search for on Google.
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
from datasets import load_dataset
dataset = load_dataset("monology/medical_meadow_alpaca", split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)The dataset is formatted; now we’ll prepare the trainer using SFT trainer.
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "input",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)Let’s check the status of our GPU before training the trainer.
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024,3)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.")
GPU = Tesla V100-PCIE-32GB. Max memory = 31.739 GB.
6.318 GB of memory reserved.We have enough memory to train the trainer.
trainer_stats = trainer.train()The training has started using Unsloth.
==((====))== Unsloth - 2x faster free finetuning | Num GPUs = 1
\\ /| Num examples = 5,942 | Num Epochs = 1
O^O/ \_/ \ Batch size per device = 2 | Gradient Accumulation steps =
4
\ / Total batch size = 8 | Total steps = 60
"-____-" Number of trainable parameters = 50,003,968Let’s check the GPU memory after training.
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory /max_memory*100, 3)
lora_percentage = round(used_memory_for_lora/max_memory*100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")
201.1437 seconds used for training.
3.35 minutes used for training.
Peak reserved memory = 10.111 GB.
Peak reserved memory for training = 3.793 GB.
Peak reserved memory % of max memory = 31.857 %.
Peak reserved memory for training % of max memory = 11.951 %.The training was quick and little GPU memory was consumed.
Now, we’ll infer the fine-tuned model with text streaming.
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
alpaca_prompt.format(
"Answer the question truthfully", # instruction
"What causes drug allergy?", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)The response is fast and fairly accurate, as you can see below.
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Answer the question truthfully
### Input:
What causes drug allergy?
### Response:
Drug allergies are caused by the body's immune system reacting to a drug. The immune system is the body's defense system. It protects the body from harmful substances.
The immune system makes proteins called antibodies. These antibodies are made to fight off harmful substances called antigens. Antigens are usually bacteria, viruses, or other foreign substances.
When the immune system makes antibodies against a drug, the drug is called an antigen. The antibodies that are made against the drug are called drug-specific antibodies.
The drug-specific antibodies can cause a drug allergy. The drug allergy can be mild or severe.Now we push the merged model to the Hugging Face repository with LoRA adapters.
model.push_to_hub_merged("akrititiwari/model", tokenizer, save_method = "lora", token = "hf_xxxxxx")
Saved lora model to https://huggingface.co/akrititiwari/modelThe model is ready to be used for our advanced RAG application.
RAG Using HyDE Query Transformation
HyDE (Hypothetical Document Embeddings) enables zero-shot prompt-based instruction-following in a large language model. It generates a hypothetical document that encapsulates relevant text patterns, converts these into embedding vectors, and then averages them to create a single embedding. This process identifies the corresponding actual embedding through vector similarity in the document embedding space, thereby eliminating the need for a retrieval step that involves querying an input and obtaining a document from a large database.
We’ll use the HyDE Query Transformation for our RAG application. Let’s start building!
Install the important dependencies.
%pip install -q llama-index
%pip install -q llama-index-llms-huggingface
%pip install -q llama-index-embeddings-huggingfaceImport the fine-tuned model.
from llama_index.llms.huggingface import HuggingFaceLLM
llm = HuggingFaceLLM(
context_window=4096,
max_new_tokens=256,
generate_kwargs={"temperature": 0.7, "do_sample": False},
tokenizer_name="akrititiwari/model",
model_name="akrititiwari/model",
device_map="auto",
stopping_ids=[50278, 50279, 50277, 1, 0],
tokenizer_kwargs={"max_length": 4096},
model_kwargs={"torch_dtype": torch.float16}
)Though the model is already fine-tuned on the medical_meadow_alpaca dataset, for building the RAG Chatbot, we will use the Medical Wikidoc Patient Information Dataset.
from datasets import load_dataset
document =
load_dataset("xDAN-datasets/medical_meadow_wikidoc_patient_information_6k", split="train")
documentSave the dataset in a directory.
document.to_csv("./dataset/patient_info.csv")Load the dataset, and initiate the embedding model.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.indices.query.query_transform import HyDEQueryTransform
from llama_index.core.query_engine import TransformQueryEngine
from IPython.display import Markdown, display
documents = SimpleDirectoryReader("./dataset").load_data()
from llama_index.embeddings.huggingface import HuggingFaceEmbeddingembed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")Set the LLM, Chunk Size, Embedding model, and the transformations.
from llama_index.core import Settings
Settings.llm = llm
Settings.chunk_size = 1024
Settings.embed_model = embed_model
from llama_index.core.node_parser import SentenceSplitter
Settings.transformations = [SentenceSplitter(chunk_size=1024)]Initiate the vector index and pass the query.
index = VectorStoreIndex.from_documents(documents)
query_str = "What causes Alstrom syndrome?"
query_engine = index.as_query_engine()
response = query_engine.query(query_str)
display(Markdown(f"<b>{response}</b>"))The response is this:
The cause of primary amyloidosis is unknown. The condition is related to abnormal and excess production of antibodies by a type of immune cell called plasma cells. Primary amyloidosis can lead to conditions that include:
Carpal tunnel syndrome Heart muscle damage (cardiomyopathy) leading to congestive heart failure Intestinal malabsorption Liver enlargement Kidney failure Nephrotic syndrome Neuropathy (nerves that do not work properly) Orthostatic hypotension (abnormal drop in blood pressure with standing) The deposits build up in the affected organs, causing them to become stiff, which decreases their ability to function.In the response, the number of tokens is too high. It is not giving the responses in a concise manner. Now, let’s see how HyDE responds to the same query. HyDE query transformation helps with direct and concise responses.
hyde = HyDEQueryTransform(include_original=True)
hyde_query_engine = TransformQueryEngine(query_engine, hyde)
response = hyde_query_engine.query(query_str)
display(Markdown(f"<b>{response}</b>"))The response is the following:
The cause of primary amyloidosis is unknown. The condition is related to abnormal and excess production of antibodies by a type of immune cell called plasma cells. Primary amyloidosis can lead to conditions that include: Carpal tunnel syndrome Heart muscle damage (cardiomyopathy) leading to congestive heart failure Intestinal malabsorption Liver enlargement Kidney failure Nephrotic syndrome Neuropathy (nerves that do not work properly) Orthostatic hypotension (abnormal drop in blood pressure with standing).The response by HyDE is straightforward. Now, we’ll initiate the retriever using the index without the HyDE Query Transformation.
index = VectorStoreIndex.from_documents(
documents, embed_model=embed_model,
transformations=Settings.transformations
)
from llama_index.core import get_response_synthesizer
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import VectorIndexRetriever
vector_retriever = VectorIndexRetriever(index=index, similarity_top_k=2)
response_synthesizer = get_response_synthesizer()
vector_query_engine = RetrieverQueryEngine(
retriever=vector_retriever,
response_synthesizer=response_synthesizer,
)Let’s pass the query in the Transform Query Engine and see the response.
query_str = "What causes Alstrom syndrome?"
hyde = HyDEQueryTransform(include_original=True)
hyde_query_engine = TransformQueryEngine(vector_query_engine, hyde)
response = hyde_query_engine.query(query_str)
display(Markdown(f"<b>{response}</b>"))The response is the following:
The cause of primary amyloidosis is unknown. The condition is related to abnormal and excess production of antibodies by a type of immune cell called plasma cells.
Primary amyloidosis can lead to conditions that include:
Carpal tunnel syndrome Heart muscle damage (cardiomyopathy) leading to congestive heart failure Intestinal malabsorption Liver enlargement Kidney failure Nephrotic syndrome Neuropathy (nerves that do not work properly) Orthostatic hypotension (abnormal drop in blood pressure with standing).You can see the difference between the responses – you can see how the HyDE Query Transform’s response is more concise.
Deploying the Gradio Chatbot
To deploy the Gradio chatbot, we’ll define a function that will query the question string from the HyDE Query Engine and return the response.
def queries(query_str):
response = hyde_query_engine.query(query_str)
return str(response)Now that the function is defined, we’ll initiate the Gradio Chatbot.
import gradio as gr
import os
gr.close_all()
with gr.Blocks(theme=gr.themes.Soft()) as demo:
gr.Markdown(
"""
# Welcome to Fine-Tuned RAG Application with Gemma 7B!
""")
chatbot = gr.Chatbot()
msg = gr.Textbox()
clear = gr.ClearButton([msg, chatbot])
def respond(message, chat_history):
bot_message = queries(message)
chat_history.append((message, bot_message))
return "", chat_history
msg.submit(respond, [msg, chatbot], [msg, chatbot])
demo.launch(share=True)Let’s see the response.
Question 1
What causes aortic stenosis?
Aortic stenosis is a narrowing of the aortic valve, which is the valve that controls the flow of blood from the heart to the body. The narrowing of the valve causes the heart to work harder to pump blood through the valve. This can lead to chest pain, shortness of breath, and other symptoms. Aortic stenosis can be caused by a number of things, including calcium deposits on the valve, a congenital heart defect, or a previous heart attack.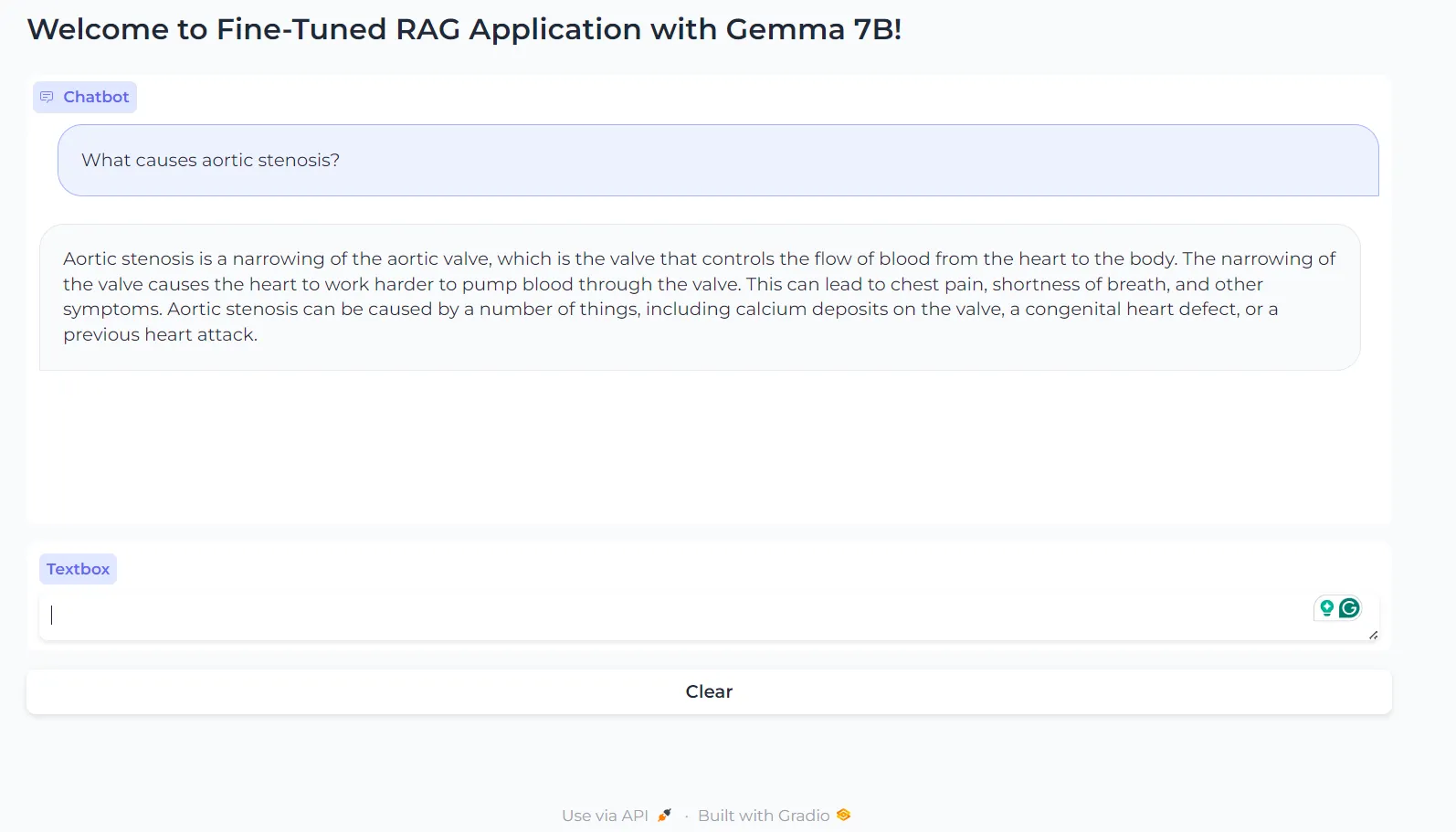
Question 2
What causes Dyspnea?
Dyspnea is a medical term for shortness of breath. It is a symptom of many different conditions, including heart failure, lung disease, and anxiety. Dyspnea can be caused by a number of different things, including:
-Heart failure: When the heart is not able to pump enough blood to the rest of the body, it can cause shortness of breath.
-Lung disease: Conditions like asthma, COPD, and pneumonia can all cause shortness of breath.
-Anxiety: When you are anxious, your body releases adrenaline, which can cause your breathing to become rapid and shallow.
-Exercise: When you exercise, your body needs more oxygen, which can cause shortness of breath.
-Pregnancy: During pregnancy, your body produces more blood and your heart has to work harder to pump it, which can cause shortness of breath.
-Obesity: Being overweight can put extra strain on your heart and lungs, which can cause shortness of breath.
-Smoking: Smoking can damage your lungs and make it harder for you to breathe.
-Age: As you get older, your lungs and heart may not work as well as they used to, which can cause shortness of breath.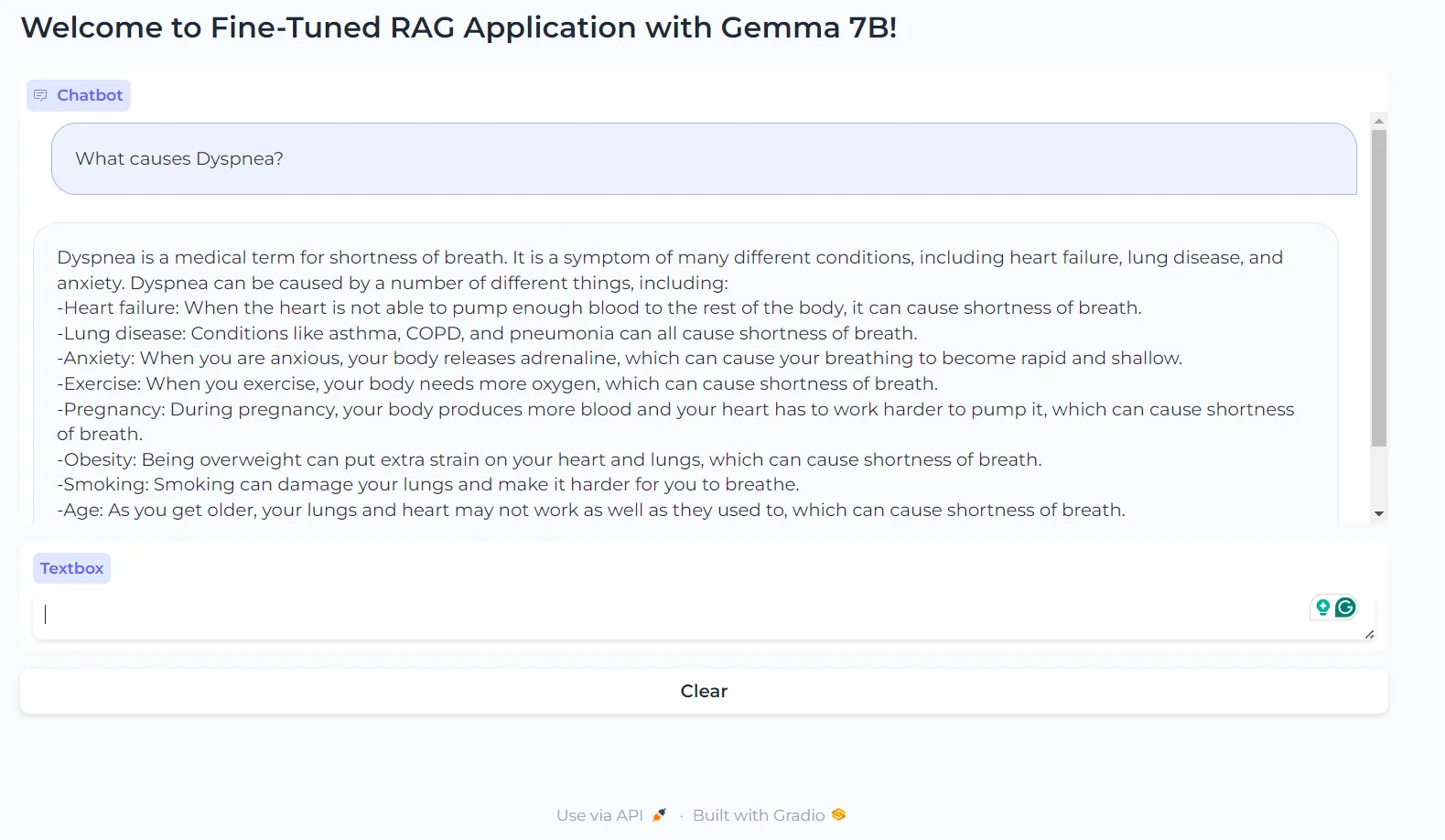
Question 3
What causes Hypokalemia?
Hypokalemia occurs when the level of potassium in the bloodstream is lower than normal. This may be related to a decrease in total body potassium or the loss of potassium from the cells into the bloodstream.
The kidneys normally remove excess potassium from the body. Most cases of hypokalemia are caused by disorders that reduce the kidneys' ability to get rid of potassium.This may result from disorders such as:
Acute kidney failure Chronic kidney failure Glomerulonephritis Obstructive uropathy Rejection of a kidney transplant
The hormone aldosterone regulates kidney removal of sodium and potassium. Lack of aldosterone can result in hypokalemia with a decrease in total body potassium. Addison's disease is one disorder that causes reduced aldosterone production.
Any time potassium is released from the cells, it may build up in the fluid outside the cells and in the bloodstream. Acidosis leads to the movement of potassium from inside the cells to the fluid outside the cells. Tissue injury can cause the cells to release potassium. Such injury includes:
Burns Disorders that cause blood cells to burst (hemolytic conditions) Gastrointestinal bleeding Rhabdomyolysis from drugs, alcoholism, coma, or certain infections Surgery Traumatic injury Tumors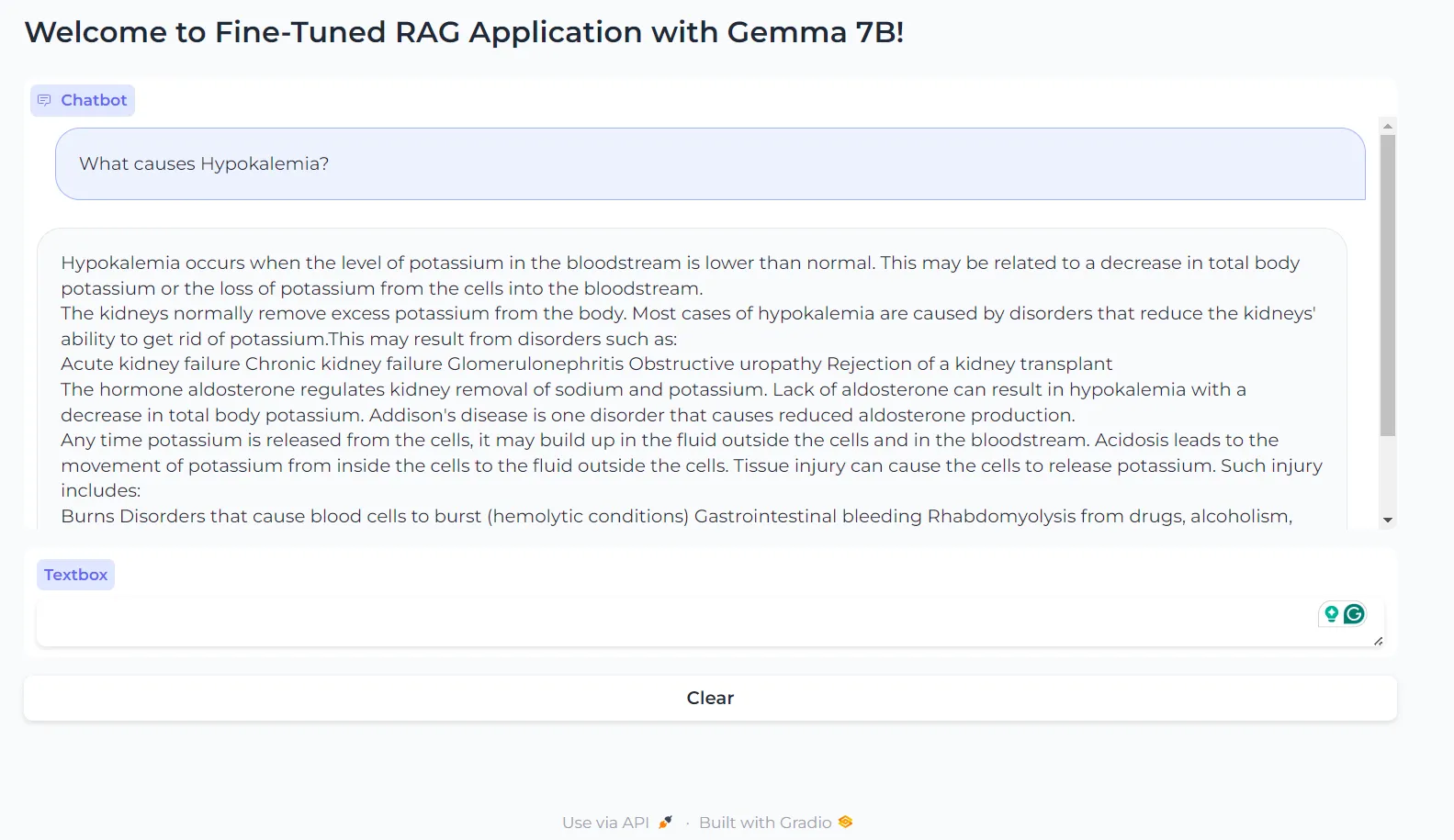
We hope you enjoyed reading the responses. They were concise and straightforward.
About Superteams.ai
Superteams.ai connects top AI talent with companies seeking accelerated product and content development. Superteamers offer individual or team-based solutions for projects involving cutting-edge technologies like YOLO-World, knowledge graphs, image, video & audio synthesis, and other open-source AI solutions. We have facilitated diverse projects in 3D e-commerce model generation, advertising creative generation, enterprise-grade RAG pipelines, geospatial applications, and more. Focusing on talent from India and the global South, Superteams offers competitive solutions for companies worldwide. To explore partnership opportunities, please write to [email protected] or visit this link.



-Feature-Image.CjBFdO7y_Z1bTNvg.webp)