Enterprises are rapidly adopting AI models into their business functions, emphasizing the need for easy scalability of AI solutions. According to McKinsey, 72% of organizations reported using AI in at least one business function as of early 2024, representing a significant increase from 50% in previous years. But with broader adoption comes a major challenge: deploying large models at scale without breaking the infrastructure or budget.
Models like the Llama series or larger Mistral models, or the Qwen series often have hundreds of millions or billions of parameters, which leads to high memory use and expensive compute requirements. In addition, businesses often need to deploy multiple instances of these models to achieve parallelism during inference (using vLLM or LiteLLM Proxy). This increases the cost of inference, and can create a hurdle in sovereign AI deployment. This is where Knowledge Distillation comes in.
Knowledge distillation solves this by shrinking the model without sacrificing much accuracy. In this technique, a smaller “student” model learns to mimic the behavior of a larger, more complex “teacher” model. The student doesn’t just learn from correct answers (hard labels); it also learns from the full set of probabilities the teacher outputs. This helps it pick up on subtle patterns and decision logic that hard labels alone don’t teach.
The result is a model that’s up to 6x smaller and 3x faster at inference, while delivering similar performance. For enterprises, that means faster response times, lower compute costs, and the ability to scale AI across the organization without hitting resource limits.
In this article, we will explain how Knowledge Distillation works, and showcase how to distil the knowledge of a larger teacher model into a smaller student model. When deploying AI in your infrastructure, you may need to use a similar tactic to reduce cost.
In This Guide, What You’ll Build:
- Working with the LEDGAR legal clause classification dataset (because legal text is notoriously tricky)
- Training a DistilBERT model as your knowledgeable teacher
- Setting up a BERT-Tiny model as your lightweight student
- Implementing the distillation process using KL divergence and cross-entropy loss
- Comparing the performance, model size, and speed of your before-and-after results
Model Comparison: DistilBERT vs BERT-Tiny
Before diving into the code, let’s understand the two architectures we’ll be working with:
DistilBERT: The Teacher
DistilBERT is a streamlined version of BERT-base. It keeps about 97% of BERT’s performance, but is 40% smaller and 60% faster. It’s often used as a compact teacher model when you want high performance without the bulk. With its 6 layers, 768 hidden dimensions, and 12 attention heads, it packs about 66 million parameters of concentrated knowledge.
BERT-Tiny: The Student
BERT-Tiny, on the other hand, is designed for speed and size. With just 4 layers and 4 attention heads, it’s ideal for deployment on devices with limited resources. At roughly 11 million parameters, it’s incredibly lightweight, but let’s be honest: on its own, it often struggles to match the performance of its bigger siblings.
Here’s what’s interesting:
table { border-collapse: collapse; width: 100%; font-family: Arial, sans-serif; } th, td { border: 1px solid #000; text-align: left; padding: 10px; vertical-align: top; } th { background-color: #f2f2f2; font-weight: bold; }
Feature
DistilBERT
BERT-Tiny
Hidden Layers
6
4
Hidden Size
768
256
Attention Heads
12
4
Parameters (approx)
~66M
~11M
Pretraining
Initialized from BERT weights
Trained from scratch or custom
The Goal Here?
By distilling DistilBERT’s knowledge into BERT-Tiny, we’re aiming to make the tiny model smarter: keeping the efficiency, while closing the performance gap. This can be a game-changer for real-world applications where speed and memory are dealbreakers.
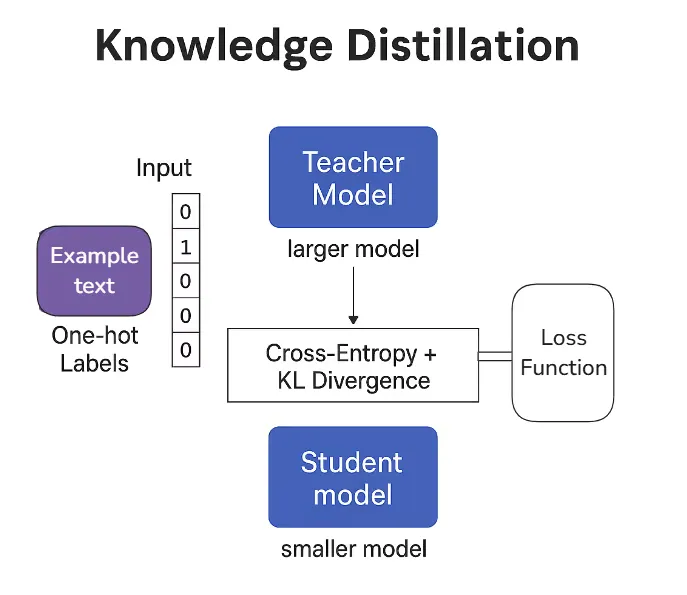
Figure 1: Knowledge Distillation
Ready to Get Started?
Next, we’ll set up the LEDGAR dataset and build your training pipeline step-by-step. Whether you’re optimizing for deployment or just curious about how distillation works under the hood, you’re in the right place. Let’s dive in.
2. Dataset & Setup: Legal NLP with LEDGAR
In this section, you’ll set up your dataset, apply necessary preprocessing, and prepare everything needed to train and evaluate both teacher and student models — starting with LEDGAR, a legal NLP dataset of labeled contract clauses.
We’re using Google Colab for demonstration, but you’re free to use any Jupyter Notebook or local environment that supports transformers and datasets.
Install Dependencies
Start by installing the libraries you’ll need for loading datasets, training models, and evaluating performance:
!pip install -U transformers datasets evaluate accelerateNow bring in the required libraries:
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
import torch
import evaluate
import numpy as np
import pandas as pd
from collections import Counter
from transformers import Trainer
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import CounterWhy LEDGAR?
The LEDGAR dataset contains legal clauses from contracts, labeled by type — for example: Confidentiality, Termination, Governing Law, and more. It’s a perfect testbed for knowledge distillation because:
-
Legal text is complex, making it a great challenge for small models.
-
It supports fine-grained classification, useful for real applications.
-
We can test whether a tiny model can retain performance after distillation.
To speed things up and ensure meaningful training, you’ll focus on the 40 most common clause types.
Load & Filter the Dataset
First, load the dataset and identify the most frequent labels:
# Load the training split of LEDGAR dataset
dataset = load_dataset("lex_glue", "ledgar", split="train")
# Count original integer label IDs
label_counter = Counter(dataset["label"])
# Get top 40 most frequent label IDs
top_40 = label_counter.most_common(40)
top_40_label_ids = [label_id for label_id, _ in top_40]Want to see what these labels look like?
# Optional: Print string label names
label_names = dataset.features["label"].names
print("Top 40 labels:")
for i, label_id in enumerate(top_40_label_ids):
print(f"{i}: {label_names[label_id]} (ID={label_id})")Now filter the dataset to only include those top 40 classes:
# Filter dataset to include only samples from top 40 labels
filtered = dataset.filter(lambda x: x["label"] in top_40_label_ids)
]]})And remap the label IDs to range from 0 to 39, which is required for the classification models:
# Remap original label IDs to a new 0–39 range
id_map = {old: new for new, old in enumerate(top_40_label_ids)}
filtered = filtered.map(lambda x: {"label": id_map[x["label"This makes your dataset more balanced and digestible for training — especially on smaller hardware.
This preprocessing ensures a balanced and well-scoped dataset, ready for training the teacher and student models.
Data Sampling & Tokenization
To keep things lightweight and fast, you’ll sample a subset of the data:
# Split dataset and take a manageable sample size
split = filtered.train_test_split(test_size=0.2, seed=42)
train_set = split["train"].select(range(min(3000, len(split["train"]))))
test_set = split["test"].select(range(min(600, len(split["test"]))))
# Tokenization function
def tokenize(examples):
return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=128)
# Apply tokenizer to the train and test datasets
tokenized_train = train_set.map(tokenize, batched=True)
tokenized_test = test_set.map(tokenize, batched=True)Here’s what’s happening:
-
80/20 split for train-test sets ratio using a fixed seed (seed=42) for reproducibility.
-
3000 samples for training
-
600 samples for testing
Next, tokenize the text using the tokenizer from the teacher model (distilbert-base-uncased):
# Load tokenizer from the teacher model
teacher_model_name = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(teacher_model_name)Define the tokenization logic and apply it:
Tokenization converts raw legal clauses into fixed-length input IDs that models can understand. Here we use:
# Apply tokenizer to the train and test datasets
tokenized_train = train_set.map(tokenize, batched=True)
tokenized_test = test_set.map(tokenize, batched=True)Here we are using:
- padding=“max_length”: Makes all sequences exactly 128 tokens long.
- truncation=True: Cuts off any input longer than 128 tokens.
- AutoTokenizer.from_pretrained(“distilbert-base-uncased”): We stick to the teacher model’s tokenizer for consistency.
This prepares your samples to be fed directly into a transformer model.
Evaluation Metric and Label Setup
You’ll evaluate model performance using accuracy, which is simple and reliable for multi-class classification:
# Load accuracy metric
accuracy = evaluate.load("accuracy")
# Define metric computation function
def compute_metrics(eval_pred):
logits, labels = eval_pred
preds = np.argmax(logits, axis=1)
return accuracy.compute(predictions=preds, references=labels)Finally, define how many output labels your model needs:
# Set number of labels for classification
num_labels = len(top_40_label_ids)This value is passed into both teacher and student models to configure their classification heads correctly.
**Accuracy Metric
**We use the Hugging Face evaluate library to compute accuracy during evaluation. It measures the percentage of predictions that exactly match the true labels.
**Metric Function
**The compute_metrics function extracts logits (raw model outputs), converts them into predicted class indices using argmax, and compares them with the true labels.
**Label Count Setup
**num_labels is set to the number of unique labels in our classification task specifically, the top 40 most frequent label IDs selected earlier. This is passed to all classification models to configure their output layer dimensions.
3. The Teacher: DistilBERT for Legal Classification
Even though DistilBERT is already a compressed version of BERT, it still packs a punch — and makes a fantastic teacher for our much smaller BERT-Tiny student. In this step, you’ll fine-tune DistilBERT on the LEDGAR dataset so it can generate the high-quality predictions we’ll later use to guide the student model during distillation.
Loading the Teacher Model
Let’s start by loading a pretrained DistilBERT model with a classification head. Since we’re working on a multi-class problem (40 clause types), we need to specify the number of output labels:
# Initialize teacher model
teacher_model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=num_labels
)This pulls in DistilBERT from Hugging Face’s model hub and configures it for classification. The output layer is automatically set up to handle num_labels classes — one for each of our clause types.
Training Configuration
Now, define your training setup using Hugging Face’s TrainingArguments. Here’s where you decide on batch sizes, how long to train, and when to evaluate:
teacher_args = TrainingArguments(
output_dir="./teacher",
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
eval_strategy="epoch",
save_strategy="epoch",
report_to=[],
)Here’s what each argument means:
-
batch_size=16: A balanced size that works well even on moderate hardware
-
num_train_epochs=3: We train for three full passes over the data
-
eval_strategy=“epoch”: Runs evaluation after each epoch
-
save_strategy=“epoch”: Saves a checkpoint after every epoch
-
output_dir=”./teacher”: The trained model and checkpoints will be saved here
Training the Model
Thanks to Hugging Face’s Trainer class, training your model is as simple as a few lines of code. It handles all the heavy lifting — batching, evaluation, logging, and optimization.
teacher_trainer = Trainer(
model=teacher_model,
args=teacher_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_test,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
teacher_trainer.train()
teacher_trainer.save_model("teacher")Now train the model:
teacher_trainer.train()
teacher_trainer.save_model("teacher")And finally, save the fine-tuned teacher for future use:
teacher_trainer.save_model("teacher")Why Use Trainer?
The Hugging Face Trainer is ideal when you want to:
-
Train and evaluate models quickly
-
Avoid writing boilerplate PyTorch code
-
Focus on experimentation and results
It’s a reliable, high-level training loop that just works — especially when you’re iterating fast and don’t need full customization.
With DistilBERT now fine-tuned on the LEDGAR dataset, you’ve set a strong performance baseline. This teacher will now serve as the knowledge source for your distillation step, helping BERT-Tiny learn from the best.
4. Baseline Model: Training Without Distillation
Before you introduce knowledge distillation, it’s crucial to first understand how well the student model performs on its own. This gives you a baseline — a reference point to measure improvement once distillation is applied.
In this setup, the student learns only from the ground-truth labels — no teacher guidance, no soft targets. It’s a fast and lightweight approach, but because the model is much smaller, it usually underperforms. That’s exactly why distillation is needed.
Meet the Student: BERT-Tiny
For our baseline, we’re using bert-mini, a variant of BERT-Tiny from Hugging Face. This model is tiny: just 4 transformer layers (compared to 6 in DistilBERT and 12 in BERT-base) making it ideal for fast inference and edge deployment.
Here’s how to load it with a classification head:
student_baseline = AutoModelForSequenceClassification.from_pretrained("prajjwal1/bert-mini", num_labels=num_labels)This model will try to learn the clause classification task without any help from a teacher.
Training Setup
Because the student model has limited capacity, we give it a bit more training time:
baseline_args = TrainingArguments(
output_dir="./student_baseline",
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=8,
eval_strategy="epoch",
report_to=[],
)Here’s what these settings do:
- 8 epochs: Gives the model more chances to learn patterns from the data
- Batch size of 16: A balanced size for most hardware
- Evaluation every epoch: So you can track performance after each full pass
Train the Baseline Model
Now use the Trainer class again to handle the training process:
baseline_trainer = Trainer(
model=student_baseline,
args=baseline_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_test,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
baseline_trainer.train()
baseline_trainer.save_model("student_baseline")Why This Matters
This baseline model is trained only using hard labels. In other words, it doesn’t get any help from the teacher model. It’s your control group. By comparing the performance of this baseline against the distilled student, you’ll clearly see how much of an advantage the knowledge transfer gives.
5. Knowledge Distillation
Training small models directly on ground-truth labels often isn’t enough, especially when the model is tiny and the task is complex. That’s where knowledge distillation comes in.
Instead of just telling the student model the correct answer, distillation lets it peek at how confident the teacher is in all possible answers. This extra signal or the “soft” predictions , gives the student a richer, more nuanced understanding of the task.
How It Works
We combine two training signals:
-
Cross-entropy loss: The classic way of comparing predictions to hard labels.
-
KL-divergence: A way for the student to mimic the teacher’s softened predictions across all classes.
Together, they help the student model learn both the correct answer and the distribution of confidence that led to it.
Define a Custom Distillation Trainer
We’ll create a custom Trainer class that incorporates both loss functions:
def compute_loss(self, model, inputs,num_items_in_batch= None, return_outputs=False):
labels = inputs.pop("labels")
outputs = model(**inputs)
logits = outputs.logits
# Prepare teacher inputs (remove token_type_ids as DistilBERT does not use it)
teacher_inputs = {k: v for k, v in inputs.items() if k != "token_type_ids"}
with torch.no_grad():
teacher_outputs = self.teacher_model(**teacher_inputs)
teacher_logits = teacher_outputs.logits
# Compute losses
loss_kl = self.kl_loss(
F.log_softmax(logits / self.temperature, dim=-1),
F.softmax(teacher_logits / self.temperature, dim=-1),
) * (self.temperature ** 2)
loss_ce = self.ce_loss(logits, labels)
loss = self.alpha * loss_ce + (1 - self.alpha) * loss_kl
return (loss, outputs) if return_outputs else lossWhat Makes Distillation Work?
To implement knowledge distillation, we define a custom training loop that mixes two loss functions:
-
Cross-Entropy Loss – so the student still learns from the ground-truth labels
-
KL-Divergence Loss – so it also learns from the teacher’s softer predictions
By combining these two signals, the student doesn’t just memorize the correct answers — it also picks up on how confident the teacher is in each class. That’s often where the real learning happens.
Key Parameters Explained
Here are the knobs you can tune in the distillation process:
-
**temperature
**This controls how “soft” the logits from both models are. A higher temperature (like 2.0) spreads out the probabilities, making it easier for the student to see which wrong answers the teacher still considered plausible.
This reveals patterns you’d miss if you only focused on the top prediction. -
**alpha
**This sets the balance between the two learning signals:-
alpha = 1.0: You’re training only on hard labels (no teacher guidance)
-
alpha = 0.0: You’re training only on the teacher’s predictions
-
In practice, values like 0.7 strike a good balance
-
The Two Loss Terms
Let’s break down what each part of the loss function does:
-
**Cross-Entropy Loss (loss_ce)
**This is the standard loss used in classification. It ensures the student learns to predict the correct class from the labeled data. -
**KL-Divergence (loss_kl)
**This measures the difference between the student’s prediction distribution and the teacher’s. But before comparing, both outputs are passed through softmax with the temperature scaling applied.
6.Train the Student Model with Distillation
Now that you’ve defined the distillation logic and built your custom trainer, it’s time to put it to work. We’ll train the same compact bert-mini model used in the baseline — but this time, it will learn not just from the labels, but also from the soft predictions of our fine-tuned teacher (DistilBERT).
Load the Student Model
Start by loading the student architecture — just like before:
student_distilled = AutoModelForSequenceClassification.from_pretrained("prajjwal1/bert-mini", num_labels=num_labels)This ensures we’re comparing apples to apples: same architecture, same tokenizer, same dataset — but now guided by a smarter training signal.
Define Training Arguments for Distillation
Here’s the training configuration:
distill_args = TrainingArguments(
output_dir="./student_distilled",
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs= 8,
learning_rate=5e-5,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=50,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
greater_is_better=True,
report_to=[],
seed=42,
eval_strategy="epoch",
save_strategy="epoch",
)
Let’s break that down:
-
8 epochs: We give the student more time to learn from the richer distillation signal.
-
Logging and evaluation per epoch: Track progress and performance regularly.
-
load_best_model_at_end=True: Keeps the best checkpoint based on validation accuracy.
-
seed=42: Ensures reproducibility.
Train with the Distillation Trainer
Now plug everything into your custom DistillationTrainer and kick off training:
distill_trainer = DistillationTrainer(
teacher_model=teacher_model,
model=student_distilled,
args=distill_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_test,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
temperature=2.0, # Controls softening of logits
alpha=0.7, # Weight more on hard labels
)
distill_trainer.train()
distill_trainer.save_model("student_distilled")Why This Setup Works
We’re using the same tokenizer, data splits, and base model as the baseline — so any improvement you see now comes purely from knowledge distillation.
Here’s what’s different:
-
temperature=2.0: Softens the output distribution, so the student learns from the teacher’s confidence across all classes — not just the top answer.
-
alpha=0.7: Gives slightly more weight to ground-truth labels (real-world supervision), while still letting the student learn from the teacher’s generalization behavior.
Key Highlights
-
We use the same tokenizer and data splits to maintain consistency.
-
load_best_model_at_end=True ensures we keep the best-performing student checkpoint based on validation accuracy.
-
Training and evaluation strategies mirror earlier setups for comparability.
This wraps up the distillation step.
7. Results and Comparison
Now that you’ve trained all three models — the Teacher, the Baseline Student, and the Distilled Student — it’s time to see how they actually perform on the same test set.
Let’s run evaluations and print the results side by side:
print("=== Evaluation Results ===")
print("\n>> Teacher Model:")
teacher_results = teacher_trainer.evaluate(tokenized_test)
print(teacher_results)
print("\n>> Student Baseline Model:")
baseline_results = baseline_trainer.evaluate(tokenized_test)
print(baseline_results)
print("\n>> Distilled Student Model:")
distilled_results = distill_trainer.evaluate(tokenized_test)
print(distilled_results)
Figure 2: Comparison of Performance
Table 1: Comparing Three different models:
table { border-collapse: collapse; width: 60%; font-family: Arial, sans-serif; } th, td { border: 1px solid #000; text-align: left; padding: 10px; } th { background-color: #f2f2f2; font-weight: bold; }
Model
Accuracy (%)
Eval Loss
Teacher
88.5
0.479
Student Baseline
80.3
1.159
Student Distilled
81.3
1.146
What These Results Tell Us
-
**Teacher Model (DistilBERT)
**As expected, the teacher leads the pack with 88.5% accuracy and the lowest evaluation loss. It sets the upper bound for performance — but also comes with more computational cost. -
**Baseline Student (BERT-mini)
**Despite its compact size, the baseline student puts up a solid 80.3%. But the higher eval loss indicates it’s less confident and less consistent in its predictions. -
**Distilled Student
**This is where things get interesting. The distilled model climbs to 81.3% accuracy — a full percentage point better than the baseline — and shows a small but meaningful drop in evaluation loss. That tells us it’s making more informed, stable predictions than the non-distilled version.
8. Conclusion: When and Why Distillation Helps
In this guide, you’ve built a complete, end-to-end knowledge distillation pipeline using Hugging Face Transformers and applied it to a real-world legal classification task with the LEDGAR dataset.
Here’s a quick recap of what you accomplished:
-
Trained a DistilBERT teacher model on legal clause classification
-
Built a BERT-mini student and trained it directly on labeled data as a baseline
-
Trained a distilled student, learning from both ground-truth labels and the teacher’s soft predictions using a dual-loss approach (Cross-Entropy + KL-Divergence)
-
Evaluated and compared performance, and saw that distillation gave the student model a clear boost — improving accuracy while keeping the model small and efficient
Why Distillation Works
The magic of knowledge distillation is in what the student sees during training. Instead of only learning the final label, the student also observes the confidence distribution the teacher assigns to all possible classes.
This helps in two big ways:
-
It gives the student richer supervision, especially in edge cases or ambiguous samples
-
It improves generalization, which is especially valuable when you’re working with smaller datasets or deploying in low-resource environments
Real-World Inference Example
To make it practical, here’s how we can use the distilled student model in production using Hugging Face’s pipeline. We test it on a few legal clauses:
import re
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
id2label = {
0: "Governing Laws",
1: "Notices",
2: "Counterparts",
3: "Entire Agreements",
4: "Severability",
5: "Survival",
6: "Amendment",
7: "Assignment",
8: "Expenses",
9: "Terms",
10: "Terminations",
11: "Insurances",
12: "Taxes",
13: "Litigations",
14: "Confidentiality",
15: "Further Assurances",
16: "General",
17: "Compliance With Laws",
18: "Indemnifications",
19: "Waivers",
20: "Use Of Proceeds",
21: "Payments",
22: "Waiver Of Jury Trials",
23: "No Conflicts",
24: "Financial Statements",
25: "Remedies",
26: "Base Salary",
27: "Releases",
28: "Authorizations",
29: "Disclosures",
30: "Binding Effects",
31: "Headings",
32: "Fees",
33: "Representations",
34: "Definitions",
35: "Subsidiaries",
36: "Authorit",
37: "Closings",
38: "Withholdings",
39: "Warranties"
}Prepare Inference Pipeline for the Distilled Student Model
label2id = {v: k for k, v in id2label.items()}
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("student_distilled")
student_model = AutoModelForSequenceClassification.from_pretrained("student_distilled")
# Set proper label mappings
student_model.config.id2label = id2label
student_model.config.label2id = label2id
# Create pipeline
student_pipe = pipeline("text-classification", model=student_model, tokenizer=tokenizer)- id2label and label2id: These mappings ensure that predictions return human-readable class names instead of just numerical IDs.
- Tokenizer and Model Loading: We reload the tokenizer and the distilled student model from the saved directory.
- Pipeline Creation: The Hugging Face pipeline abstracts away most preprocessing and model forwarding. It takes raw text and returns a list of predicted labels with associated confidence scores.
Examples:
# Sample legal clauses
texts2 = [ # Governing Laws
"This Agreement shall be governed by and construed in accordance with the internal laws of the State of New York, without giving effect to any choice or conflict of law provision or rule that would cause the application of laws of any other jurisdiction.",
# Payments
"The Client agrees to remit full payment of all invoices within thirty (30) days of receipt. Late payments shall incur an interest charge of 1.5% per month or the maximum rate permitted by law, whichever is lower.",
# Confidentiality
"Each Party agrees that it shall not disclose, divulge, reveal, or use any Confidential Information, including trade secrets, client lists, and proprietary methodologies, for any purpose other than to perform its obligations under this Agreement, without the prior written consent of the disclosing Party.",
# Terminations
"This Agreement may be terminated by either Party with thirty (30) days' written notice if the other Party materially breaches any provision of this Agreement and fails to cure such breach within fifteen (15) days after receiving written notice thereof.",
# Representations
"The Seller represents and warrants that it has good and marketable title to the goods being sold, free and clear of all liens, claims, encumbrances, and security interests, and that it has the full right, power, and authority to enter into and perform this Agreement.",
# Indemnifications
"The Service Provider shall indemnify, defend, and hold harmless the Client and its affiliates from and against any and all claims, damages, losses, liabilities, costs, and expenses, including reasonable attorneys’ fees, arising out of or resulting from the Provider’s breach of this Agreement or negligent performance of its duties hereunder.",
# Severability
"If any provision of this Agreement is found to be invalid, illegal, or unenforceable in any respect, the validity, legality, and enforceability of the remaining provisions shall not in any way be affected or impaired thereby.",
# Amendments
"No amendment or modification of this Agreement shall be valid or binding unless set forth in writing and duly executed by both Parties. Email communications alone shall not constitute valid amendments unless expressly agreed otherwise.",
# Notices
"All notices or other communications required or permitted under this Agreement shall be in writing and shall be deemed to have been duly given when delivered in person or sent by certified mail, return receipt requested, to the addresses provided by each Party.",
# Waivers
"The failure of either Party to enforce any rights under this Agreement shall not be construed as a waiver of such rights or any other rights hereunder, unless such waiver is given in writing and signed by the Party waiving such rights."
]
# Run inference and display predictions
for i, text in enumerate(texts2, 1):
pred = student_pipe(text, truncation=True, max_length=128)[0]
label_name = pred["label"]
score = pred["score"]
print(f"\nExample {i}:")
print(f"Text: {text}")
print(f"Predicted Label: {label_name} (confidence: {score:.4f})")
Results:
Example 1:
Text: This Agreement shall be governed by and construed in accordance with the internal laws of the State of New York, without giving effect to any choice or conflict of law provision or rule that would cause the application of laws of any other jurisdiction.
Predicted Label: Governing Laws (confidence: 0.9499)
Example 2:
Text: The Client agrees to remit full payment of all invoices within thirty (30) days of receipt. Late payments shall incur an interest charge of 1.5% per month or the maximum rate permitted by law, whichever is lower.
Predicted Label: Payments (confidence: 0.1904)
Example 3:
Text: Each Party agrees that it shall not disclose, divulge, reveal, or use any Confidential Information, including trade secrets, client lists, and proprietary methodologies, for any purpose other than to perform its obligations under this Agreement, without the prior written consent of the disclosing Party.
Predicted Label: Confidentiality (confidence: 0.5435)
Example 4:
Text: This Agreement may be terminated by either Party with thirty (30) days' written notice if the other Party materially breaches any provision of this Agreement and fails to cure such breach within fifteen (15) days after receiving written notice thereof.
Predicted Label: Terminations (confidence: 0.5175)
Example 5:
Text: The Seller represents and warrants that it has good and marketable title to the goods being sold, free and clear of all liens, claims, encumbrances, and security interests, and that it has the full right, power, and authority to enter into and perform this Agreement.
Predicted Label: Representations (confidence: 0.1401)
Example 6:
Text: The Service Provider shall indemnify, defend, and hold harmless the Client and its affiliates from and against any and all claims, damages, losses, liabilities, costs, and expenses, including reasonable attorneys’ fees, arising out of or resulting from the Provider’s breach of this Agreement or negligent performance of its duties hereunder.
Predicted Label: Indemnifications (confidence: 0.4526)
Example 7:
Text: If any provision of this Agreement is found to be invalid, illegal, or unenforceable in any respect, the validity, legality, and enforceability of the remaining provisions shall not in any way be affected or impaired thereby.
Predicted Label: Severability (confidence: 0.8920)
Example 8:
Text: No amendment or modification of this Agreement shall be valid or binding unless set forth in writing and duly executed by both Parties. Email communications alone shall not constitute valid amendments unless expressly agreed otherwise.
Predicted Label: Amendment (confidence: 0.3623)
Example 9:
Text: All notices or other communications required or permitted under this Agreement shall be in writing and shall be deemed to have been duly given when delivered in person or sent by certified mail, return receipt requested, to the addresses provided by each Party.
Predicted Label: Notices (confidence: 0.8894)
Example 10:
Text: The failure of either Party to enforce any rights under this Agreement shall not be construed as a waiver of such rights or any other rights hereunder, unless such waiver is given in writing and signed by the Party waiving such rights.
Predicted Label: Waivers (confidence: 0.2891)Final Thoughts
Knowledge distillation is one of those rare techniques that gives you real-world performance wins without adding complexity. It lets you take large, high-performing models and compress them into smaller, faster versions — with only a small trade-off in accuracy.
In this hands-on tutorial, you saw just how effective it can be. Even a tiny model like BERT-mini was able to narrow the performance gap with its teacher, simply by learning from the teacher’s soft labels.
When Should You Use Distillation?
Distillation is especially useful when:
-
You’re targeting edge devices or low-latency environments — like mobile apps, legal SaaS platforms, or compliance tools
-
You’ve trained a powerful teacher model but need something lighter for **real-time use
**
-
You want to retain most of the model’s accuracy while **cutting down size, memory, and inference costs
**
Get Enterprise-Grade NLP Without the Engineering Overhead
If you’re exploring AI for legal tech, enterprise NLP, or compliance, but don’t have the in-house team to build and optimize these systems, Superteams can help. We specialize in deploying high-accuracy, low-latency models using techniques like knowledge distillation, tailored to your business needs.
Let’s talk.
Get in touch with Superteams to accelerate your AI deployment.