The financial advisory industry is ripe for disruption. Traditional wealth management services are expensive, often inaccessible to average investors, and limited by human availability. What if we could democratize financial expertise by building an AI system that combines the depth of historical market knowledge with real-time data insights?
In this comprehensive guide, we’ll walk through creating an intelligent wealth management advisor that thinks like a seasoned financial analyst while being available 24/7 to anyone with questions about stocks, investments, and market trends.
The Vision: Your Personal Financial AI Assistant
Imagine having a conversation with a financial expert who has instant access to years of market data, can fetch the latest stock prices in real-time, and never gets tired of answering your questions. Our AI Wealth Management Advisor makes this vision a reality by intelligently routing queries between a comprehensive local knowledge base and live market data APIs.
When you ask, “What is the PE ratio of Infosys?” or “How has Apple’s performance compared to the market this quarter?”, the system doesn’t just return raw numbers. Instead, it provides contextual analysis, explains the significance of the metrics, and delivers insights in plain English, just like a human advisor would.
The Architecture: Smart Data Routing at Its Core
The genius of this system lies in its hybrid approach to data retrieval. Rather than relying solely on either static databases or live APIs, our AI advisor intelligently determines the best data source for each query:
Local Knowledge Base (Qdrant Vector Database)
- Stores comprehensive historical stock data, financial ratios, and market analysis
- Enables semantic search through vector embeddings
- Provides instant responses for historical queries and established financial metrics
- Offers consistent performance regardless of external API availability
Real-Time Market Data (Gemini API)
- Fetches current stock prices, volumes, and market movements
- Provides breaking news and recent financial events
- Ensures users get the most up-to-date information when it matters
- Handles queries requiring live market conditions
Intelligent Query Router (LLM-Powered)
- Analyzes user questions to determine optimal data source
- Extracts key information like stock symbols, date ranges, and query intent
- Falls back gracefully when primary data sources don’t have relevant information
- Formats responses in natural, advisor-like language
The User Experience: Natural Conversations About Finance
The beauty of this system is its conversational interface. Users don’t need to learn complex financial terminals or memorize stock symbols. They can ask questions the same way they would speak to a human advisor:
- “What’s driving Tesla’s stock movement today?”
- “Compare the dividend yields of Microsoft and Apple”
- “Should I be concerned about the tech sector’s recent volatility?”
- “What was Amazon’s revenue growth last quarter?”
Each query triggers a sophisticated decision-making process that ensures users receive the most accurate, relevant, and timely information available.
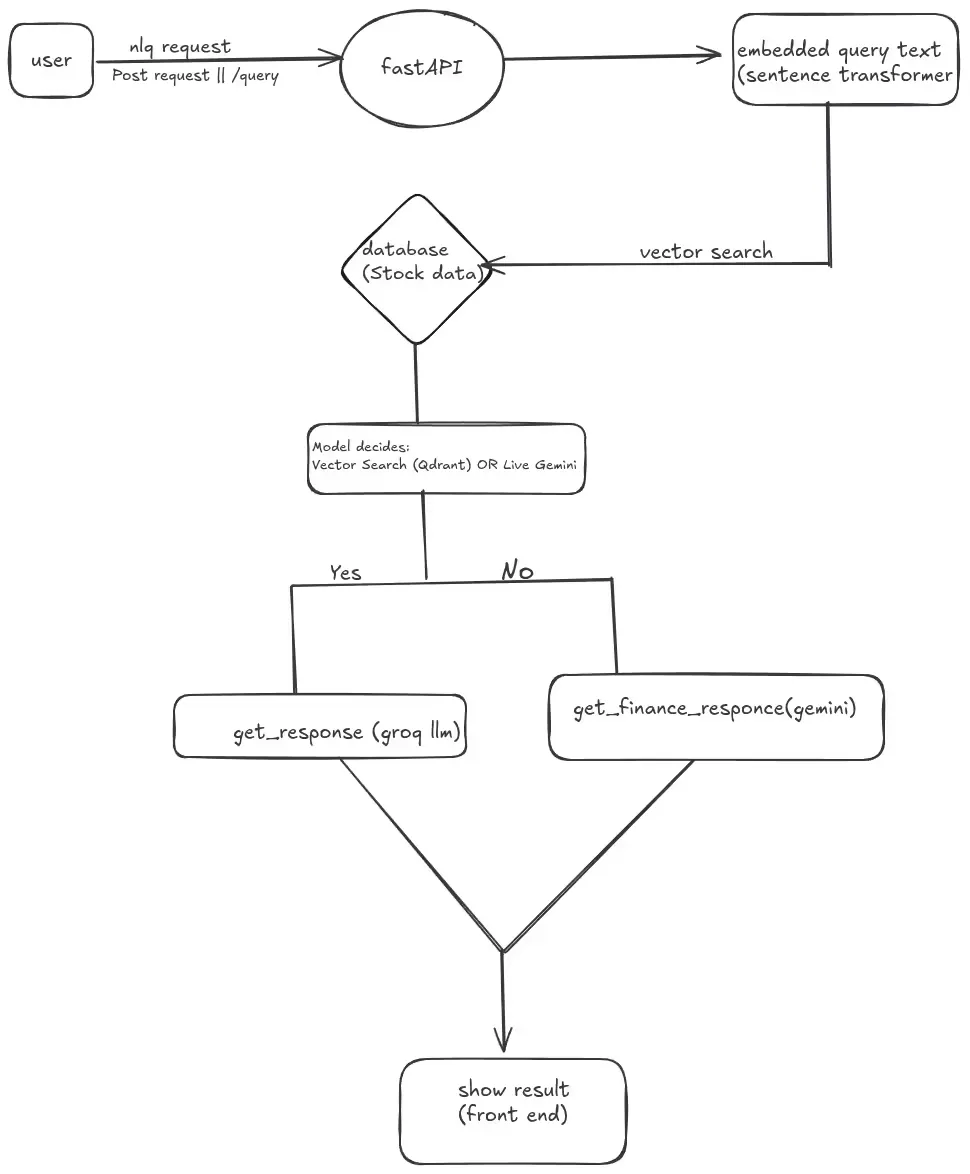
Technical Deep Dive: The 7-Step Query Processing Pipeline
Let’s explore how the system processes user queries from initial input to final response:
Step 1: Capturing User Intent
The journey begins with natural language input from the user:
# Ask user
user_query = input("Enter your query: ")
This simple interface masks the complexity happening behind the scenes. The system is designed to handle various question formats, from simple stock lookups to complex analytical queries about market trends and financial performance.
Step 2: Intelligent Query Parsing
Before any data retrieval begins, the system must understand what the user is actually asking:
parsed_query = parse_query(user_query)
stocks = parsed_query["stocks_mentioned"]
date_range = parsed_query["date_range"]
routing = parsed_query["if_vector_or_live"]
print(f"\nParsed Query: {parsed_query}")
The parse_query() function leverages large language models to extract structured information from natural language. This parsing step identifies:
- Stock mentions: Company names, ticker symbols, or sector references
- Time context: Specific dates, quarters, or relative time frames like “recent” or “last month”
- Data freshness requirements: Whether the query needs live data or can be answered from historical records
This structural understanding is crucial for making smart routing decisions and providing contextually appropriate responses.
Step 3: Smart Routing Decision
With parsed query data in hand, the system makes its first major decision:
if routing == "live":
print("\n> Fetching live data...\n")
print(get_finance_response(user_query))
When the LLM determines that a query requires real-time information, such as current stock prices, recent news, or today’s market movements, it immediately routes to the live data pipeline. This ensures users get the freshest possible information for time-sensitive financial decisions.
Step 4: Vector Search in the Knowledge Base
For queries that can be answered from historical data, the system performs semantic search in Qdrant:
else:
# Vector search
query_vector = model.encode(user_query).tolist()
query_filter = None
if date_range != "none":
query_filter = {"must": [{"key": "date", "match": {"value": date_range}}]}
query_points = client.query_points(
collection_name="stock",
query=query_vector,
limit=5,
with_payload=True,
query_filter=query_filter
)
This step demonstrates the power of vector databases for financial applications. The system:
- Converts queries to embeddings: Using SentenceTransformer models to create semantic representations
- Performs similarity search: Qdrant finds the most relevant historical data points
- Applies temporal filters: If the user specified a time range, only relevant historical periods are considered
- Retrieves comprehensive data: Each match includes full payload data for detailed responses
Step 5: Selecting the Best Match
Vector searches return multiple potential matches, so the system must identify the most relevant result:
best_response = None
best_score = float('-inf')
for point in query_points.points:
score = point.score
payload = point.payload
if score > best_score:
best_score = score
best_response = payload
This scoring mechanism ensures that users receive the most relevant historical data available. The similarity scores provide confidence metrics that help the system decide whether to use the vector search results or fall back to live data.
Step 6: Relevance Validation
Even the best vector search match might not be good enough to answer the user’s question. The system includes a relevance check:
if not best_response or not is_relevant(user_query, best_response):
print("\n> No good match in database. Fetching live data...\n")
print(get_finance_response(user_query))
This fallback mechanism is crucial for maintaining response quality. When historical data doesn’t adequately address the user’s query—perhaps they’re asking about a very recent event or a company not well-represented in the knowledge base—the system gracefully switches to live data retrieval.
Step 7: Natural Language Response Generation
Finally, when a good match is found in the historical database, the system generates a natural language response:
else:
print("\n> Found in database:\n")
print(get_response(best_response))
print(f"\n(Qdrant match score: {best_score:.2f})")The get_response() function transforms raw financial data into advisor-like explanations. Instead of just showing numbers, it provides context, explains significance, and offers insights that help users understand the implications of the data.
The Technology Stack: Why These Choices Matter
Qdrant for Vector Search
Qdrant was selected for its exceptional performance with financial data embeddings. Financial queries often have subtle semantic similarities: “earnings growth” and “revenue increase” should return similar results even though they use different words. Vector search excels at capturing these semantic relationships.
FastAPI for Backend Architecture
FastAPI provides the high-performance, async-capable backend needed for financial applications. When users ask questions, they expect fast responses, whether that data comes from local databases or external APIs. FastAPI’s automatic API documentation and type validation also make the system more maintainable as it grows.
React for Interactive Frontend
The conversational interface built with React provides an intuitive chat experience that feels natural for asking financial questions. Users can see their query history, understand the system’s reasoning process, and interact with responses in ways that traditional financial terminals don’t support.
LLM Integration for Intelligence
Large language models provide the natural language understanding and generation capabilities that make this system feel like talking to a human advisor. The LLM handles query interpretation, response formatting, and the complex reasoning required to determine appropriate data sources.
Real-World Applications and Use Cases
This AI wealth management advisor serves multiple user segments with different needs:
Individual Investors
- Quick stock research and company analysis
- Portfolio performance tracking and insights
- Market trend understanding without jargon
- Educational financial content tailored to their questions
Financial Advisors
- Rapid client research preparation
- Historical data analysis for presentations
- Real-time market updates during client meetings
- Automated initial research for new investment opportunities
Small Investment Firms
- Cost-effective research capabilities without expensive Bloomberg terminals
- 24/7 availability for client inquiries
- Standardized analysis across different analysts
- Educational tool for junior team members
Financial Educators
- Interactive teaching tool for investment concepts
- Real examples to illustrate financial principles
- Historical case studies for market behavior analysis
- Personalized learning experiences for students
Performance Considerations and Optimizations
Building a responsive financial AI system requires careful attention to performance:
Embedding Caching: Common financial terms and company names are pre-computed and cached to reduce query latency.
API Rate Limiting: Smart queuing and caching strategies prevent hitting external API limits during high-traffic periods.
Vector Index Optimization: Qdrant indices are tuned for financial data patterns, improving search speed and accuracy.
Response Streaming: Long analytical responses are streamed to users, providing immediate feedback while complete analysis generates.
Security and Compliance Considerations
Financial applications require robust security measures:
Data Privacy: User queries and responses are handled according to financial privacy regulations.
API Key Management: External service credentials are securely managed and rotated regularly.
Audit Trails: All queries and responses are logged for compliance and system improvement purposes.
Rate Limiting: Protection against abuse while maintaining responsive service for legitimate users.
Future Enhancement Opportunities
This foundation opens up numerous possibilities for expansion:
Portfolio Management: Integration with brokerage APIs for real-time portfolio analysis and recommendations.
Risk Assessment: Advanced modeling to provide personalized risk analysis based on user profiles and market conditions.
Automated Alerts: Proactive notifications about portfolio changes, market events, or investment opportunities.
Multi-Asset Support: Expansion beyond stocks to include bonds, cryptocurrencies, commodities, and alternative investments.
Regulatory Integration: Real-time incorporation of SEC filings, earnings reports, and regulatory announcements.
Social Sentiment: Analysis of social media and news sentiment to provide additional market context.
Getting Started: Setting Up Your Own Financial AI
The complete implementation is available on GitHub, making it easy to deploy your own instance or contribute to the project.
The modular architecture means you can start with basic functionality and gradually add more sophisticated features as your needs grow. Whether you’re building internal tools for an investment firm or creating consumer-facing financial applications, this codebase provides a solid foundation.
Key Technical Insights
Several important patterns emerge from this implementation that apply to other AI applications:
Hybrid Data Architecture: Combining static knowledge bases with live APIs provides the best of both worlds—speed and freshness.
Intelligent Routing: LLM-powered decision making can significantly improve user experience by automatically choosing optimal data sources.
Graceful Fallbacks: Multiple fallback mechanisms ensure users always get useful responses, even when primary systems fail.
Semantic Search: Vector databases excel in domains like finance where terminology variety is high but concepts often overlap.
Context Preservation: Maintaining query context throughout the pipeline enables more sophisticated and relevant responses.
The Future of AI in Financial Services
This project represents just the beginning of AI’s transformation of financial services. As language models become more sophisticated and financial data becomes more accessible, we can expect to see AI advisors that rival human experts in many areas.
The democratization of financial expertise through AI has profound implications. Investment advice that was once available only to high-net-worth individuals can now be accessible to anyone with an internet connection. Complex market analysis that required years of training can now be performed instantly by AI systems.
However, the human element remains crucial. AI advisors excel at data processing, pattern recognition, and consistent analysis, but humans provide the emotional intelligence, ethical judgment, and personalized understanding that many financial decisions require.
Conclusion: Building the Future of Financial Advice
Creating an AI wealth management advisor demonstrates how modern AI technologies can be combined to solve real-world problems. By thoughtfully integrating vector databases, real-time APIs, and large language models, we can build systems that provide genuine value to users while maintaining the performance and reliability that financial applications demand.
The code is open source, the architecture is extensible, and the potential applications are vast. Whether you’re interested in learning about AI system design, building financial applications, or exploring the intersection of technology and investment management, this project provides practical insights and a working foundation to build upon.
To learn more, speak to us.



-Feature-Image.CjBFdO7y_Z1bTNvg.webp)