Aviation didn’t become the world’s safest mode of travel by building the perfect aircraft. It got there by accepting that no single component is flawless and we need to build a system designed to catch what each layer misses.
The result was the Swiss Cheese Model, a safety framework built on a simple but powerful idea: no single defence is perfect, but enough imperfect defences, if stacked strategically, could make catastrophic failure nearly impossible.
AI Agents are now complex enough to warrant the same thinking.
Not because they are dangerous, but because they operate in environments where even a small error can compound exponentially. An agent can retrieve stale data, interpret an ambiguous instruction in a way that executes an action in the wrong order, thus making your business pay for multiple serious follies.
What follows is a framework we call the Swiss Cheese Model for AI Agent Accuracy. It emerged from deploying agentic systems across real estate, finance, logistics, and customer operations, often into environments where getting it wrong meant real financial or reputational consequences. Four layers. Each one designed to catch what the last one misses.

Lessons from 30,000 Feet
In 1990, psychologist James Reason introduced the Swiss Cheese Model to explain how catastrophic failures occur in complex systems like aviation. Imagine multiple slices of Swiss cheese stacked together. Each slice represents a defensive layer: pilot training, equipment checks, air traffic control, weather monitoring. Each slice has holes, representing potential failures or weaknesses.
The genius of the model is this: a single hole doesn’t cause a disaster. It’s only when the holes in multiple layers align, when every defense fails simultaneously, that catastrophe strikes.
This model revolutionized aviation safety. Instead of relying on a single point of defense, the industry built redundant, overlapping systems. The result? Air travel became one of the safest modes of transportation in human history.
The same principle can apply to AI agents, particularly as they move from answering questions to executing decisions. An agent handling a customer refund, updating a record, or rerouting a shipment isn’t just generating documents. It’s taking actions with real consequences. When it fails, the failure may not always be a single cause. It could be the result of multiple layers failing at once.
Slice 1: The Foundation (Data Quality & Agent Knowledge Base)
Before an AI agent ever executes its first action, it needs reliable information about the world it operates in. This foundational layer is where most agent failures actually begin—long before the agent starts “deciding” what to do.
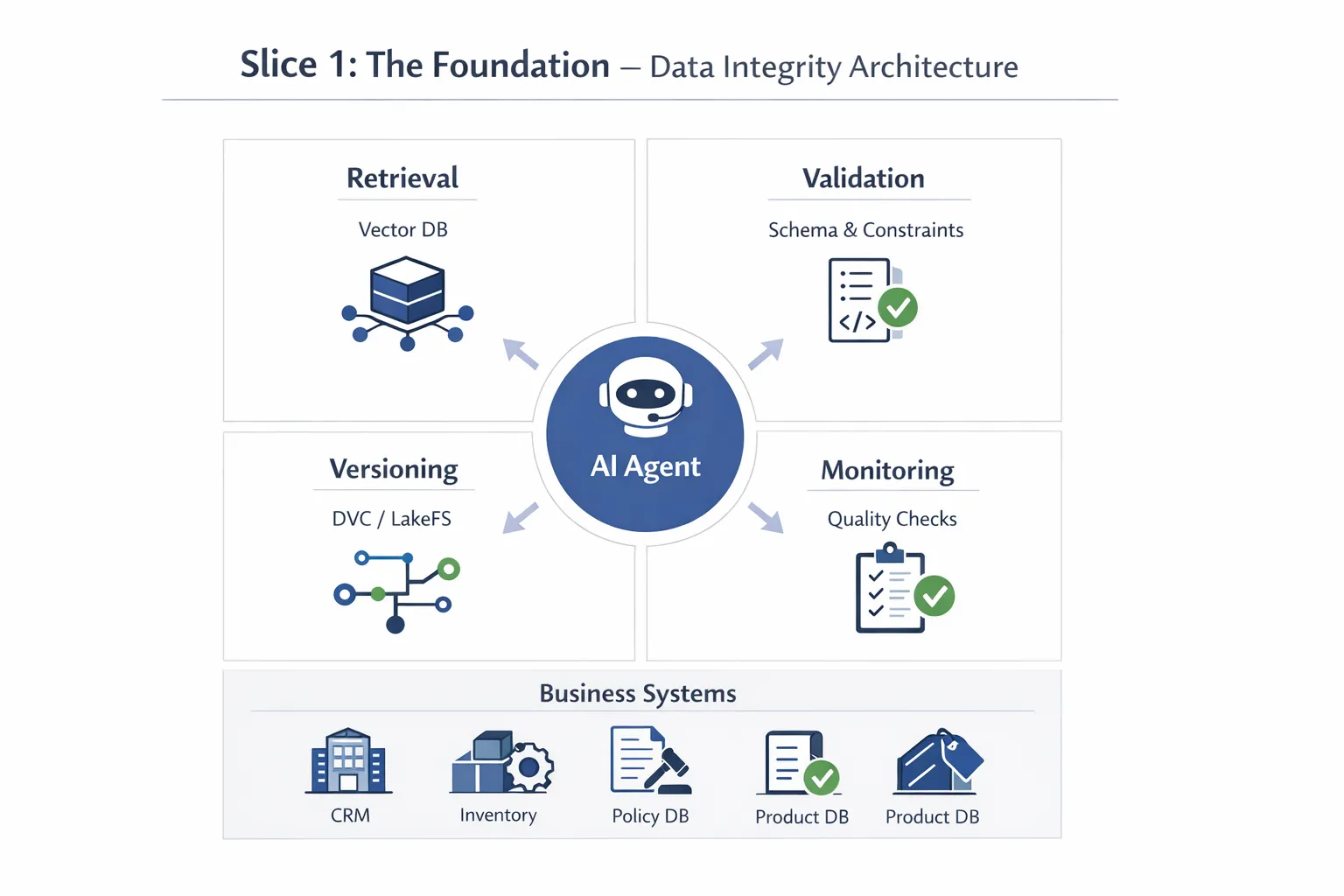
High-Quality Base Data is the bedrock of agent reliability. An agent handling customer support doesn’t just need clean FAQs; it needs access to real-time inventory systems, accurate customer records, updated product specifications, and current policy documents. When you’re building an agent that can process refunds, feeding it outdated pricing data or stale inventory information creates immediate vulnerabilities.
In practice, this means implementing:
Vector Databases for Semantic Search: Tools like Pinecone, Weaviate or Qdrant store your knowledge base as embeddings, enabling the agent to retrieve contextually relevant information rather than relying on keyword matching. When an agent encounters a customer question about “laptop battery life,” semantic search can surface documentation about “portable computer power duration” even if the exact phrase doesn’t match.
Data Versioning Systems: Implement systems like DVC (Data Version Control) or LakeFS to track changes to your knowledge base over time. When an agent generates an incorrect response, you need to know: Was this based on version 2.3 of the product documentation or version 2.4? This traceability is essential for debugging and rollback.
Automated Data Quality Checks: Run scheduled validation jobs that check for:
- Broken links in documentation
- Outdated timestamps (e.g., policy documents older than 6 months)
- Schema drift in connected databases
- Duplicate or conflicting information across sources
But clean data alone isn’t enough for agents that need to take actions.
Clear Schema Definitions and Tool Descriptions act as the instruction manual for the agent’s capabilities. When an agent has access to a function called update_customer_record(), it needs crystal-clear documentation: What parameters does it accept? What are the validation rules? What are the side effects? Can it be reversed? What permissions are required?
Consider an agent with access to a CRM database. If a column is labeled “AMT,” the agent needs explicit metadata: “Annual Maintenance Total (USD, fiscal year basis, range: $0-$50,000, nullable: false).” This prevents the agent from interpreting “AMT” as “Amount Due” and accidentally updating the wrong field, or from entering an invalid value that breaks downstream systems.
This foundational slice also includes tool versioning and dependency mapping. When an agent has access to multiple APIs and databases, you need to track which versions of which tools are being used, how they interact, and what happens when one service goes down. Without this infrastructure, you’re giving an agent powerful capabilities without a proper understanding of what those capabilities actually do.
Slice 2: Eliminate Ambiguity (Agent Prompting & Action Constraints)
Even with perfect data and well-documented tools, an agent can go catastrophically wrong if you don’t constrain its decision-making process. This slice is about defining the agent’s operational boundaries and decision logic with precision.
Precision in Agent Instructions means crafting system prompts that define not just what the agent should do, but when and how it should act. A vague instruction like “Help customers with their orders” opens the door for the agent to improvise dangerously.
Here’s what a precise agent prompt template actually looks like:
ROLE AND SCOPE:
You are a customer service agent for [Company Name] with access to order management systems.
CAPABILITIES:
You can perform the following actions:
- View order details (read-only)
- Process standard refunds under $500
- Update shipping addresses for unshipped orders
- Cancel orders that haven't entered fulfillment
CONSTRAINTS:
You CANNOT:
- Process refunds over $500 (escalate to supervisor)
- Modify orders in fulfillment or delivered status
- Access payment methods or financial information
- Make policy exceptions
DECISION PROTOCOL:
Before executing ANY action that modifies data:
1. State what action you intend to take
2. Explain why this action is appropriate
3. Request explicit user confirmation ("Should I proceed with [specific action]?")
4. Wait for affirmative response before proceeding
ERROR HANDLING:
If an API call fails:
- Do not retry automatically
- Inform the user of the failure
- Escalate to human support
If information is ambiguous or missing:
- Do not make assumptions
- Ask clarifying questions
- Default to the safest option (escalation or no action)
ESCALATION TRIGGERS:
Immediately route to human supervisor when:
- Refund amount exceeds $500
- Customer requests policy exception
- Multiple API failures occur
- Customer expresses strong dissatisfaction (detected sentiment < 0.3)
- You are uncertain about the correct action
TONE AND COMMUNICATION:
- Professional and empathetic
- Transparent about what you can and cannot do
- Never promise actions you cannot execute
This structured approach forces the agent to think through consequences, make its intentions transparent, and creates an opportunity for validation before any action is taken. You can implement this using JSON schemas with strict validation, or by using constrained decoding techniques that force the model to output only valid action plans.
Slice 3: The Engine (Agent Reasoning & Grounded Action)
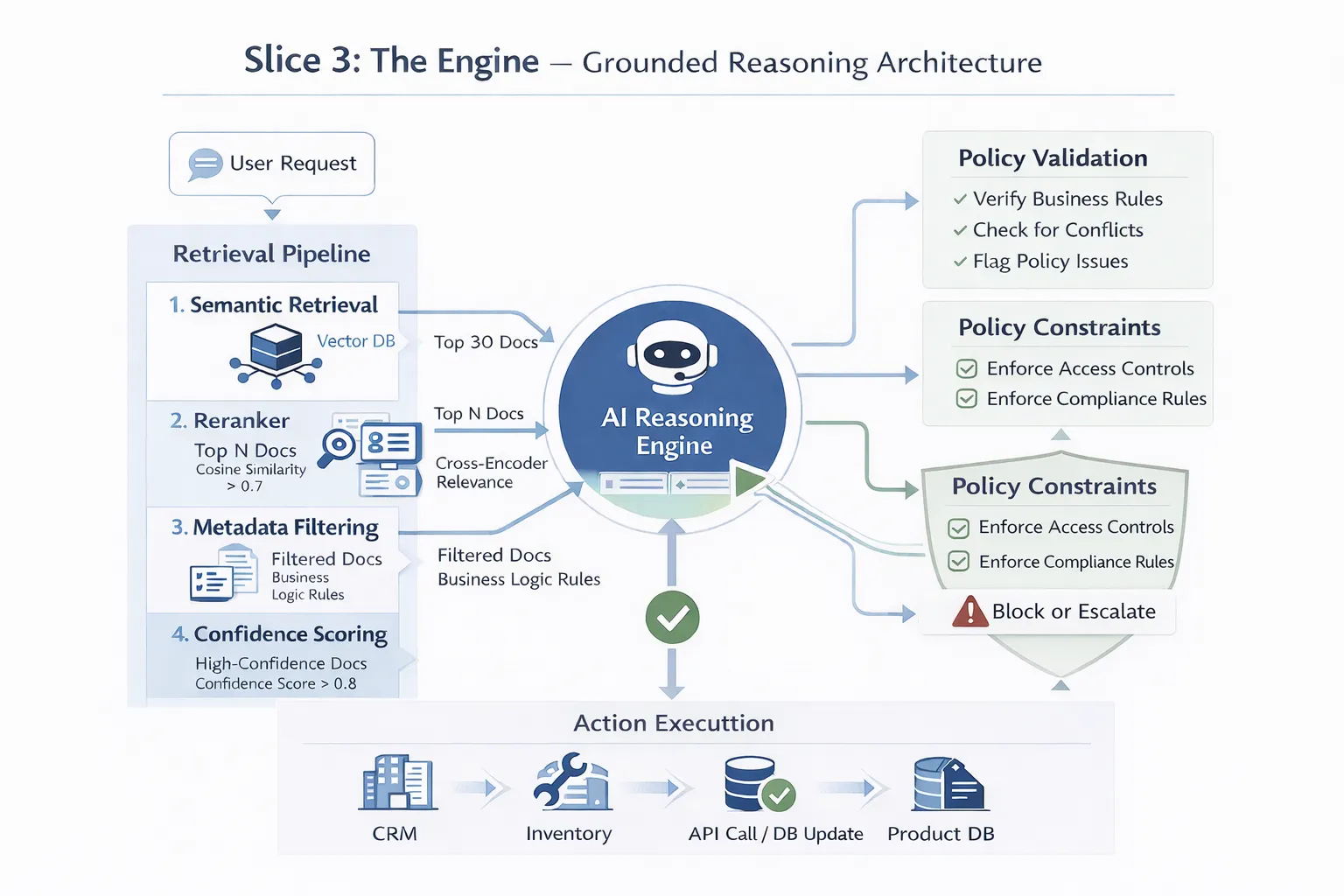
This is where the agent does its actual decision-making and action execution but even here, we build in safeguards that fundamentally change how the AI “acts.”
RAG (Retrieval-Augmented Generation)
RAG for Agents represents a paradigm shift from agents that operate on general knowledge to agents that ground their decisions in verified, real-time information. When an agent needs to decide whether to approve a refund, it doesn’t rely on what the model “remembers” about refund policies. Instead, it:
1. Retrieves the current refund policy document from the knowledge base
2. Retrieves the specific order details from the database
3. Retrieves the customer’s history and account status
4. Grounds its decision in these specific, retrieved facts
5. Generates its action plan based solely on verified information
The key is in how retrieval is scored and ranked. Not all retrieved documents are equally relevant, and poor retrieval can be worse than no retrieval at all.
Here’s how to implement a multi-stage retrieval pipeline:
Stage 1 - Semantic Retrieval:
Use embedding similarity to retrieve the top 20-30 candidate documents from your vector database. Set a minimum similarity threshold (e.g., cosine similarity > 0.7) to filter out obviously irrelevant results.
Stage 2 - Reranking:
Use a cross-encoder model (like Cohere’s rerank API or a fine-tuned BERT model) to rerank these candidates based on actual relevance to the query. This catches nuanced relevance that embedding similarity might miss.
Stage 3 - Metadata Filtering:
Apply business logic filters:
- Prioritize documents marked as “current_policy: true”
- Exclude documents older than X months (unless historical context is needed)
- Weight internal documentation higher than general knowledge
- Consider document authority scores (e.g., documents from legal/compliance rated higher for policy questions)
Stage 4 - Confidence Scoring:
For each retrieved chunk, calculate a confidence score based on:
- Retrieval similarity score
- Reranker score
- Document metadata quality
- Temporal relevance
Only provide chunks to the agent that exceed your confidence threshold. If no chunks meet the threshold, the agent should escalate rather than guess.
Advanced Reasoning Models with Chain-of-Thought Action Planning
They add another layer by making the agent explicitly reason through multi-step workflows before executing them. Models with extended thinking modes perform internal deliberation: breaking down complex requests, checking logical consistency, anticipating edge cases, and validating action sequences before execution.
For instance, if a customer requests, “I need to change my shipping address and get this delivered by Friday,” a standard agent updates the address and confirms the order. A reasoning-enabled agent works through the dependencies first:
“The customer wants a new shipping address and a Friday delivery. Let me check: the order is already in fulfillment and has been assigned to a carrier. Address changes at this stage require carrier coordination, which adds 24–48 hours. Today is Wednesday. Friday delivery is no longer achievable if I reroute — I’d be creating a false expectation. Better approach: update the address, but proactively inform the customer that Friday delivery is no longer guaranteed and offer to expedite at the next available window.”
This internal deliberation catches sequences of actions that individually seem fine but collectively create problems.
Slice 4: The Safety Net (Guardrails, Monitoring & Rollback)
The final slice assumes everything before it might still fail—and prepares accordingly. For autonomous agents, this layer is especially critical because it’s your last line of defense before real-world consequences.
Hard Guardrails and Action Limiting
These are real-time safety mechanisms that operate independently of the agent’s decision process. These guardrails include:
- Transaction Limits: Agents can’t process refunds over $X, create orders over $Y, or delete more than Z records without human approval.
- Rate Limiting: Agents can only execute N actions per minute, preventing runaway loops.
- Scope Restrictions: Agents can only access specific databases, call specific APIs, and modify specific record types.
- Temporal Constraints: Certain actions (like data deletion) can only be executed during specific time windows or with time delays.
- Approval Chains: High-impact actions are automatically flagged for human review before execution.
These guardrails use a combination of rule-based logic, separate validation services, and policy engines. They’re fast, deterministic, and catch many dangerous actions that slip past the agent’s reasoning process. When triggered, they either block the action entirely, downgrade it to a safer version, or route it to human oversight.
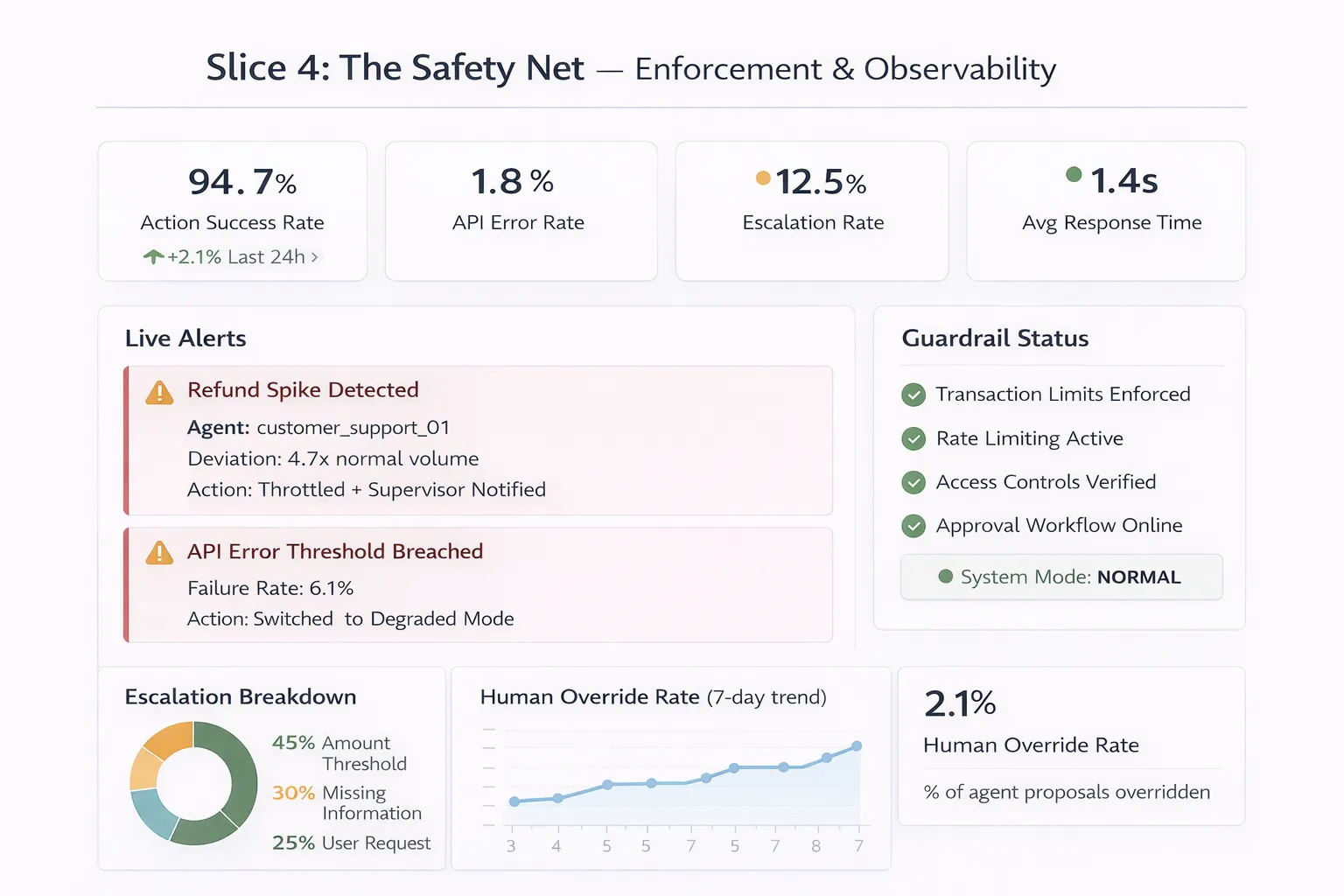
Real-Time Output Monitoring and Anomaly Detection
This operates in parallel with agent execution. Here’s what effective monitoring dashboards actually track:
From Theory to Practice: Real-World Results
In practice, we have seen this architecture produce measurable results: error rates fall, rollback incidents decline, support tickets related to agent mistakes decrease, and clients gain the confidence to give agents real operational responsibility, not just low-stakes tasks.
More importantly, it produces a different kind of organizational relationship with AI systems. The question stops being “how do we prevent the agent from making any mistakes?”, which is unanswerable, and becomes “how do we make sure mistakes are caught before they matter?” That question has an answer.
The Swiss Cheese Model works for AI Agents because it acknowledges a fundamental truth: no single defense is perfect. But when you stack imperfect defenses strategically, reliability emerges from redundancy.
Building a Swiss Cheese architecture requires experience across data infrastructure, prompt engineering, retrieval systems, and production monitoring. That’s exactly where Superteams comes in. Our teams have deployed agentic systems across real estate, finance, logistics, and customer operations, and we bring that hard-won experience directly to your build. Whether you’re starting from scratch or hardening an existing agent, we bring across specialist teams that can design and implement all four layers: from knowledge base architecture and tool schema design, to reasoning model selection, guardrail configuration, and live monitoring dashboards. If you want to build production-grade systems you can trust with real operational responsibility, talk to us.