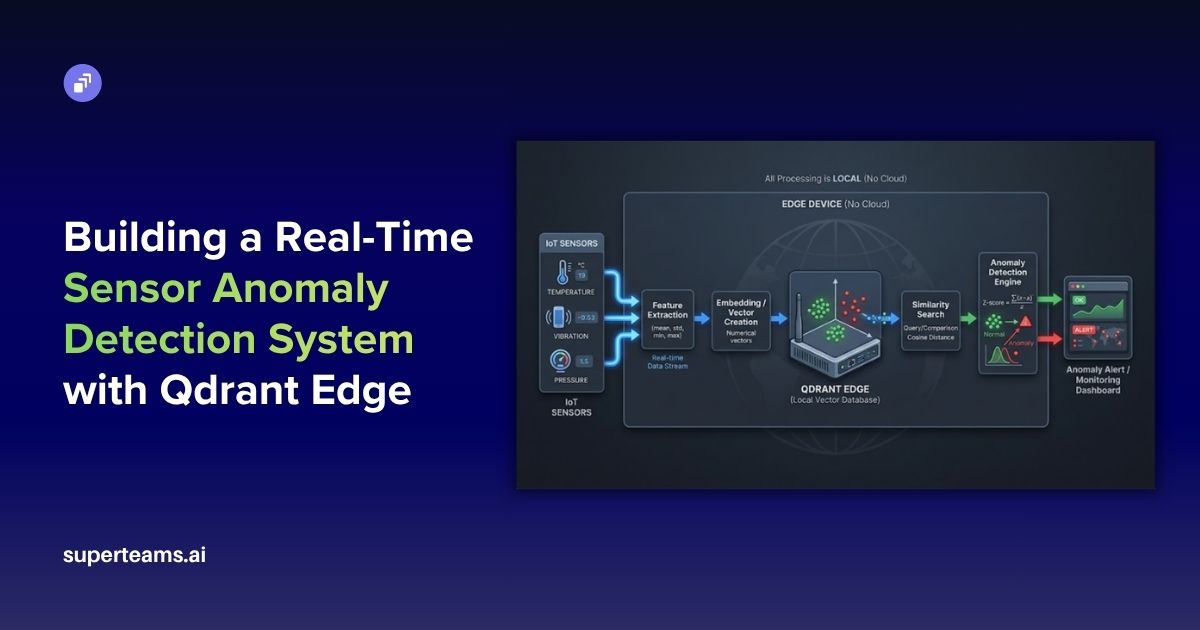
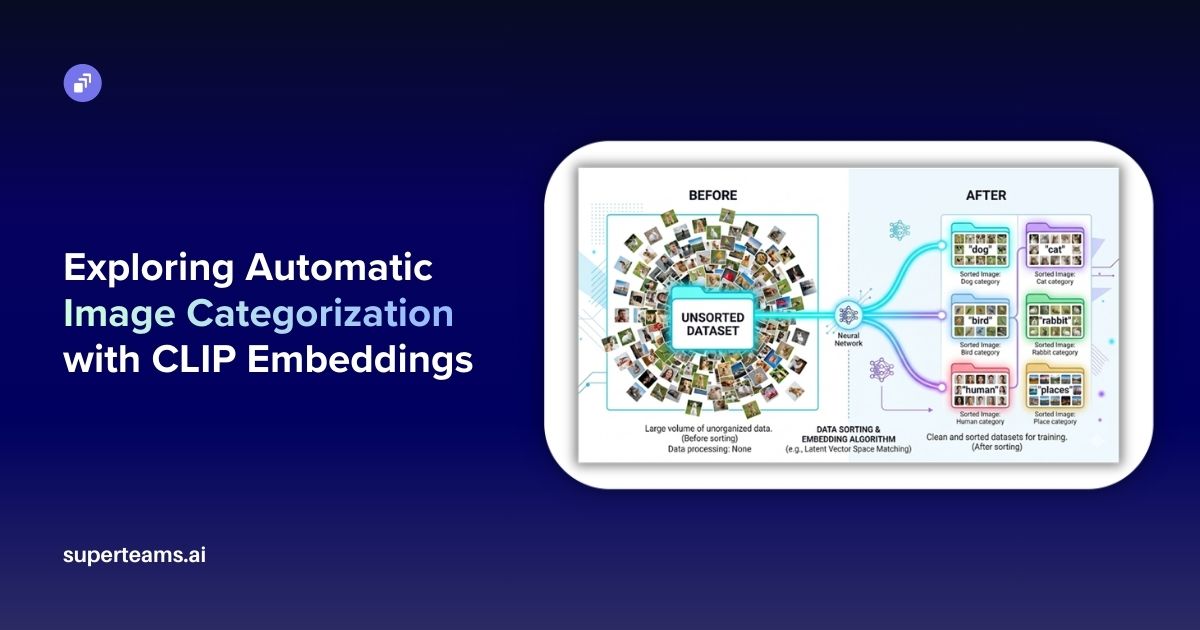
Transformer Architecture
Browse Knowledge Base >The Transformer model is a groundbreaking architecture in deep learning that utilizes a self-attention mechanism to process sequential input data, such as text or images, in a parallel manner. Unlike traditional models that relied on recurrent or convolutional layers, the Transformer is entirely based on attention mechanisms, which enable it to focus on different parts of the input data to perform tasks more efficiently. Initially proposed for sequence-to-sequence learning tasks like translation, its application has broadened to include a wide range of areas in natural language processing (NLP), computer vision, and beyond.
The Transformer model was introduced by Vaswani et al. in the seminal paper "Attention Is All You Need" in 2017. This work marked a departure from previous sequence learning models by proposing an architecture that entirely relies on attention mechanisms, eliminating the need for recurrence and convolutions in the model. The introduction of the Transformer has led to significant advancements in machine learning, setting new standards for model performance across various tasks.
How it works
At its core, the Transformer architecture comprises two main components: an encoder and a decoder, each consisting of multiple layers.
The encoder maps an input sequence to a sequence of continuous representations, which the decoder then uses to generate an output sequence. Within both encoder and decoder, the Transformer employs multi-head self-attention mechanisms and position-wise fully connected networks. The self-attention mechanism allows the model to weigh the importance of different words within the input data, facilitating the understanding of contextual relationships between words or features. Positional encoding is added to the input embeddings to retain the order of the sequence, as the model itself does not inherently process sequential data in order.
Transformers have revolutionized several fields, most notably in NLP for tasks such as language translation, text summarization, and sentiment analysis. They are also foundational to the development of large language models like BERT, GPT-3, and OpenAI's ChatGPT. Transformer-based models have shown remarkable performance in generating human-like text, understanding context, and even coding. Beyond NLP, Transformers have been adapted for applications in computer vision, such as image recognition and generation, and in other domains like speech recognition and reinforcement learning.
Open Source LLMs Based on Transformer Architecture
Transformer architecture has been extensively used in a range of Generative AI models. For instance, here's a list of open-source Large Language Models (LLMs) that utilize Transformer architecture:
- BLOOM: An open-access AI model known for its causal modeling approach, making it significant for its capacity to capture reasoning abilities.
- BERT (Bidirectional Encoder Representations from Transformers): Developed by Google, this model has excelled in various NLP tasks since its introduction.
- OPT (Open Pre-trained Transformer): Released by Meta AI, OPT models range from smaller variants to the large OPT-175B, demonstrating performance comparable to other leading LLMs.
- Llama 2: Meta's response to OpenAI's GPT and Google's AI models, Llama 2 is available for research and commercial purposes, making it a versatile tool in the AI space.
- Megatron-LM: A powerful Transformer developed by NVIDIA, designed for efficient, model-parallel training of large Transformer-based models like GPT and BERT.
- Stable Beluga: Built on the LLaMA models, these LLMs are designed for solving complex problems, especially in specialized fields such as law and mathematics.
- MPT (MosaicML's Pre-trained Transformers): A series of Transformer-based LLMs designed for flexibility and efficiency in various NLP tasks.
- Cerebras-GPT: Focuses on compute-efficient training for LLMs of any size using the open Pile dataset. It aims at advancing the development of large language models with its open-source findings.
- Falcon 180B: An LLM being trained on 180 billion parameters, demonstrating capabilities that rival other leading models in NLP tasks.
- XGen-7B: A project by Salesforce aimed at delivering concise and informative answers, showcasing the growing interest in LLM development across different sectors
More Resources
- "Attention Is All You Need" paper
- The Illustrated Transformer
- The Annotated Transformer
- Transformer: A Universal Architecture