
Retrieval-Augmented Generation (RAG) is a game-changing approach that supercharges the abilities of large language models (LLMs). By pulling in data from external sources and weaving it directly into prompts, RAG systems give you responses that are sharper, more up-to-date, and packed with relevant context.
In its essence, RAG works on a simple but powerful principle: it finds information relevant to your query from a vector database and feeds it to an LLM to generate an answer. But if your basic RAG setup isn’t quite hitting the mark, don’t worry! There are advanced techniques you can use to enhance the accuracy and efficiency of your RAG system.
In this guide, we’ll explore these advanced RAG techniques, giving you a toolkit to mix and match methods that best suit your needs.
Why Use Advanced RAG Techniques
The following diagram illustrates how a RAG pipeline works.
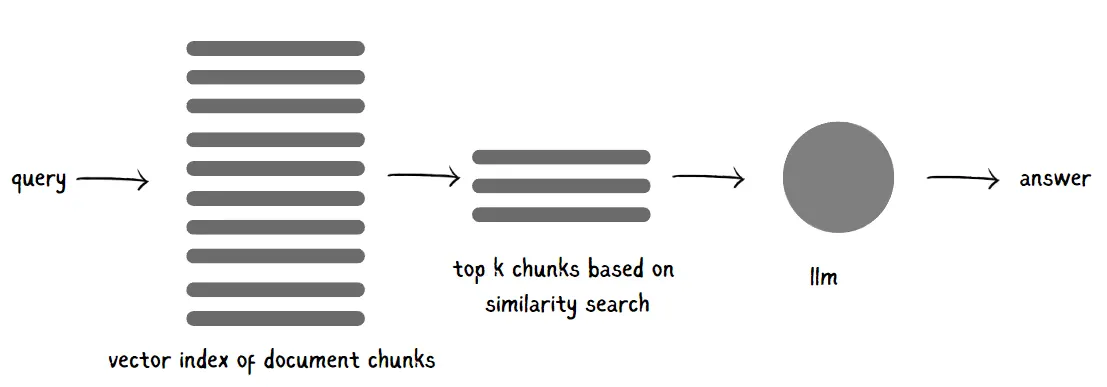
However, as Scott Barnett et. al highlighted in their paper “Seven Failure Points When Engineering a Retrieval Augmented Generation System,” even a powerful RAG system can hit a few snags along the way. Let’s look at some common stumbling blocks—and how you might sidestep them to keep your RAG system running smoothly.
Inaccurate or Incomplete Retrieval
- Missing Content: Sometimes, the system might miss key documents entirely, leaving you with answers that feel incomplete.
- Missed Top-Ranked Documents: Important documents might be buried too far down in the results, so they don’t make it into your context—meaning you miss out on valuable insights.
- Low Recall and Precision: When the retrieval mechanism isn’t tuned just right, it might grab too many irrelevant documents or miss the mark on the best ones, hurting both recall and precision.
- Information Redundancy: Ever feel like your RAG-generated responses are a bit repetitive? That’s likely because the system pulled in multiple contexts saying the same thing, clogging up your final output.
Contextual Issues
- Not in Context: Even if your system retrieves relevant documents, they might not make it into the context for generation—especially if the system gets a little too ambitious with the number of documents it pulls.
- Noise in Context: When irrelevant info slips in, it can distract the language model, leading to off-the-mark answers.
- Low Information Density: Pulling in too much unstructured or fluff data dilutes the valuable details you need.
- Inconsistent Chunking: Using a one-size-fits-all approach to chunking can backfire, with some document types needing customized chunking to keep the meaning intact.
- Incomplete Responses: Even when the right information is available, the generated answer may still miss key details due to an incomplete context.
In RAG, the accuracy of the data you pull is make-or-break. Researchers found that a RAG system’s accuracy could drop by up to 67% when related—but off-target—documents are included. So, fine-tuning what you retrieve is critical for getting the most precise, useful responses every time.
Here comes the critical question: How do you improve the context and precision of a RAG system?
Advanced RAG Techniques for Improving Context
Here, we’ll dive into some advanced techniques you can use to level up the quality of retrieved information—your context—when generating responses. These methods go beyond basic setups, helping you get cleaner, sharper data into your RAG system. Let’s jump right in!
#1. Using LLMs to Process, Clean, and Label the Data
If your RAG application processes PDF or HTML documents, you’ve probably run into the mess that can follow when a parser strips out formatting like CSS or HTML tags. The resulting text is often disorganized, with noise that can muddy your results. To fix this, consider using an LLM to clean and structure the data.
This technique not only removes the clutter but also boosts the information density of your context data, filtering out irrelevant bits and leaving you with a more precise foundation for your RAG application. Cleaner data means sharper, more accurate responses.
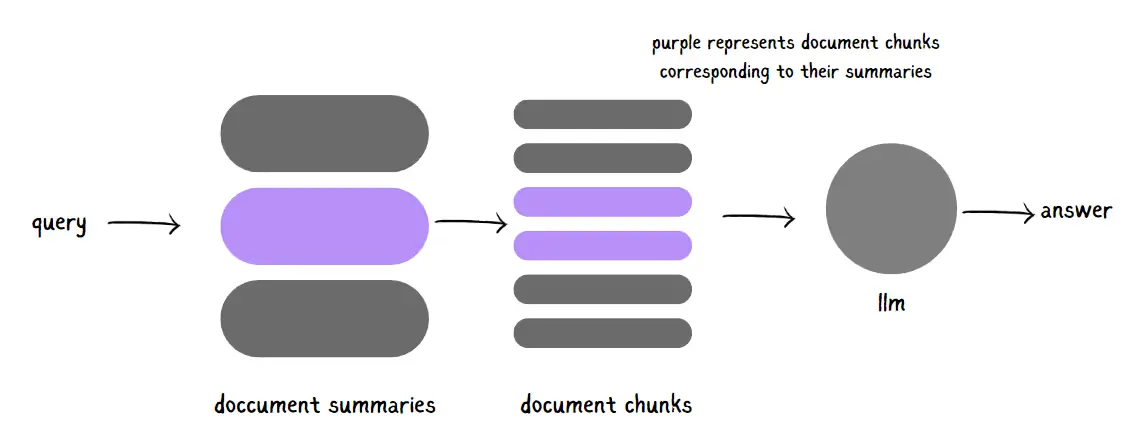
#2. Hierarchical Indexing
With Hierarchical Indexing, you’ll create two separate indices: one with document summaries and another with document chunks.
Here’s how it works: First, your system searches through the summaries, finding documents similar to the query. Once you’ve zeroed in on these, the search drills down into specific document chunks within this filtered set. This two-layer approach allows your RAG system to focus only on the most relevant parts of your documents, rather than the entire text, ensuring you retrieve more precise information for your response generation.
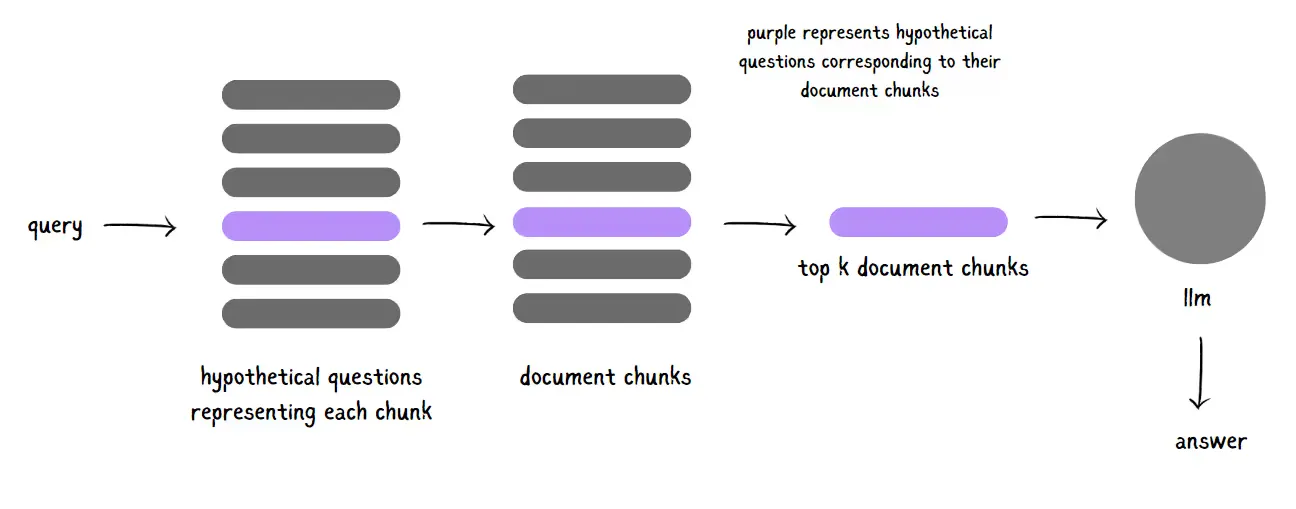
#3. Hypothetical Question Indexing
This technique puts an interesting twist on the retrieval process. You’ll have an LLM generate a hypothetical question for each document chunk, then embed those questions as vectors.
When a query comes in, it’s matched against these pre-embedded hypothetical questions. This way, your system pulls in document chunks based on a closer semantic similarity between the query and the hypothetical questions, leading to a more targeted, high-quality search.
#4. Optimizing Chunking Strategy
Transformer models have a fixed input length, which means you’ve got to be smart about chunking your data for best results. Sure, larger context windows can hold more info, but the trick is that a vector for a single sentence or paragraph will often give you a sharper semantic meaning than one that’s been averaged over pages.
Ideally, you want to chunk your data by meaningful sections—think full sentences or paragraphs—without breaking them up mid-sentence. Plenty of text splitter tools can help with this. Plus, different embedding models perform best with different chunk sizes. For instance, sentence transformers thrive on individual sentences, while models like text-embedding-ada-002 can handle larger chunks.
Tailor your chunk size to your embedding model, or vice versa! And remember, the type of document matters too. For legal documents, paragraph-level chunks might be best, while scientific papers often work well when chunked by sections or subsections.
#5. Choice of Embedding Model
Picking the right embedding model is key, and there’s data to back up your choice. The Massive Text Embedding Benchmark shows how different models perform across tasks like retrieval, classification, and summarization. Interestingly, for summarization tasks, the smaller text-embedding-3-small can outperform its bigger sibling—even though it has fewer dimensions. Bigger isn’t always better!
If you’re working in a specialized field, consider fine-tuning your embedding model. Without fine-tuning, your model might misinterpret user queries, especially if they include niche terms. Fine-tuning helps your RAG system understand your domain and deliver more accurate responses.
#6. Multimodal Context Integration
Why stick to just text when you can enrich your context with images, audio, and other unstructured data? By integrating different modes of information, you make your RAG responses that much richer and more nuanced.
For visual data, OpenAI’s CLIP model is a fantastic choice. It creates a joint embedding space for both text and images, allowing you to easily pair an image with its semantically similar text counterpart. Or try models with vision capabilities, like GPT-4 or LLaVA, which are brilliant at describing visual content. You can use these descriptions to add depth to your context.
Audio embeddings are another option if you’re handling sound data—imagine adding audio transcriptions to your retrieval context for a truly multimodal setup.
By blending these advanced techniques, you’ll be well on your way to a RAG system that delivers precise, contextually rich, and user-focused responses.
Advanced RAG Techniques for Enhancing Precision
Below, we outline several techniques you can apply at the retrieval stage of your RAG application to improve performance.
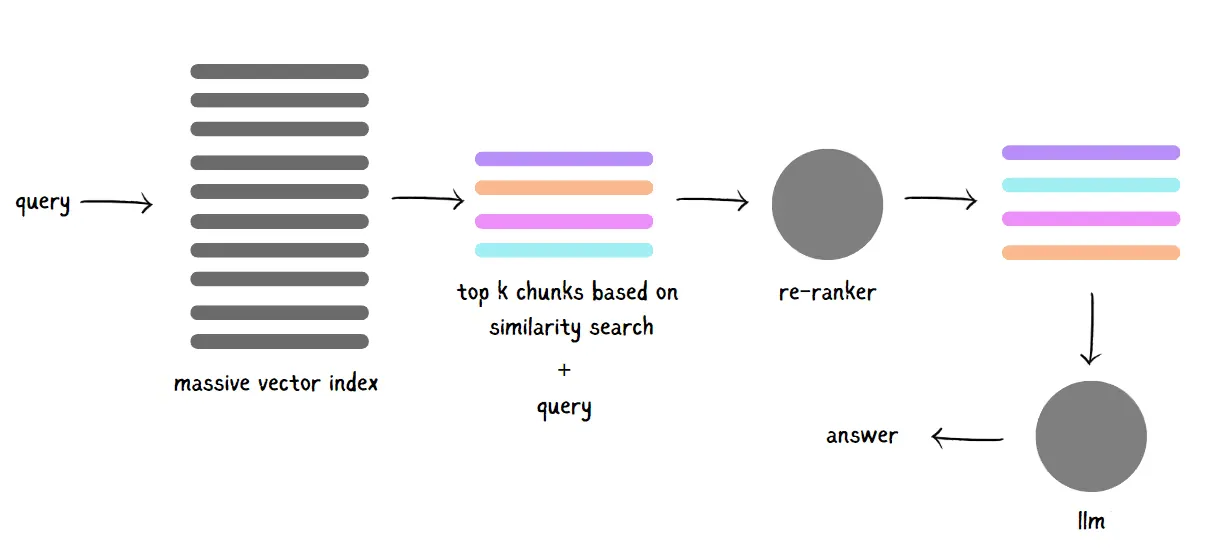
#1. Two-Stage Retrieval Using Rerankers
One powerful way to boost your RAG system’s performance is through two-stage retrieval with rerankers. Research by Cuconasu et al. found that positioning the most relevant documents closest to the query in the prompt can significantly improve RAG outcomes. Here’s where rerankers come in.
Rerankers are models that take a query and a document pair, then calculate a similarity score that helps reorder your retrieved documents. They’re especially effective because they use transformer models to directly score the similarity between the query and each document, avoiding the information loss that can happen with basic embeddings. The downside? Rerankers can be a bit slow.
So, what’s the solution? Use a hybrid approach! Start with a quick vector search to identify broadly relevant documents, then let a reranker take those top results and fine-tune the ordering. This way, you’re balancing speed and accuracy, getting a list of documents that’s both relevant and precisely ranked for your query.
#2. HyDE: Hypothetical Document Embeddings
In HyDE, the goal is to use hypothetical documents to get closer to the essence of a query, enhancing the retrieval process with some creative twists. Here’s how it works: for each query, HyDE uses an LLM to generate five “fake” documents that capture the core ideas or patterns of the query. These aren’t actual documents from your database but rather crafted texts designed to reflect the query’s key themes.
Once these hypothetical documents are created, they’re converted into embeddings. By averaging these embeddings into a single, unified vector, you end up with a focused representation of the query. This single embedding is then used to run a similarity search, helping you find the closest actual documents in your document database based on vector similarity.
The result? A more refined search that aligns closely with the query’s intent, allowing you to retrieve documents that feel truly relevant. For a deeper dive into this technique, check out this paper—it’s packed with insights on how to put this approach into action.
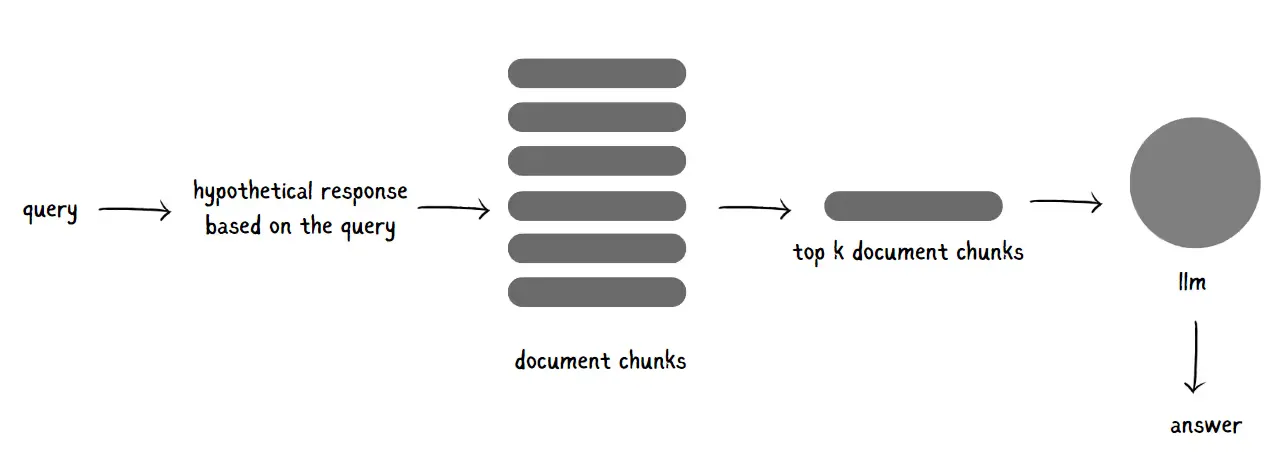
#3. Precise Retrieval Followed by Context Enrichment
To retrieve smaller, highly relevant chunks for better search quality—and then enrich those chunks with surrounding context—you’ve got a couple of smart options.
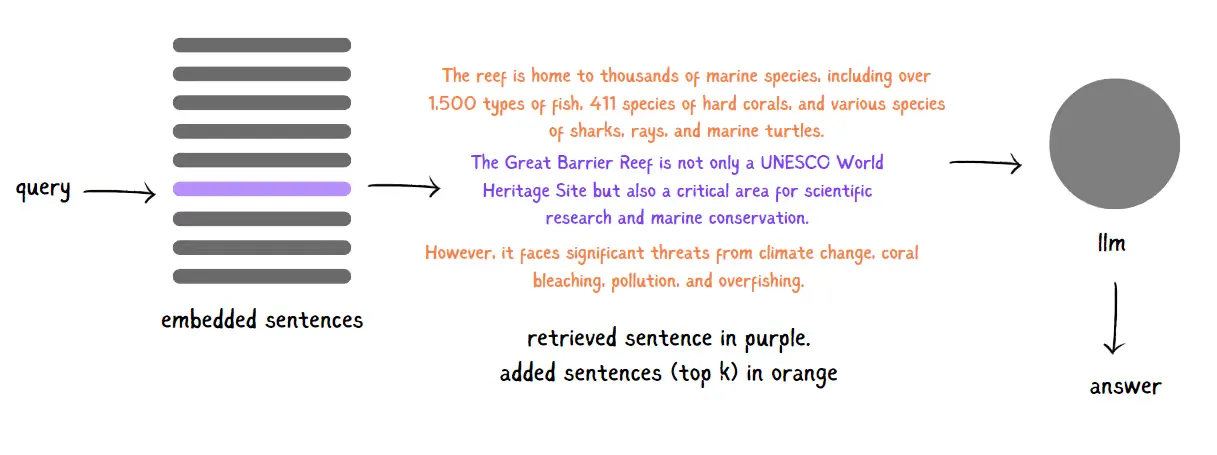
- Sentence Window Retrieval
Here, each sentence in a document gets its own embedding, allowing for incredibly precise, targeted searches. When a sentence matches your query closely, it’s retrieved along with a window of context—typically, k sentences before and after the retrieved sentence. This way, you get exactly the snippet you need, along with a bit of helpful context around it, making your retrieval sharper and more meaningful.
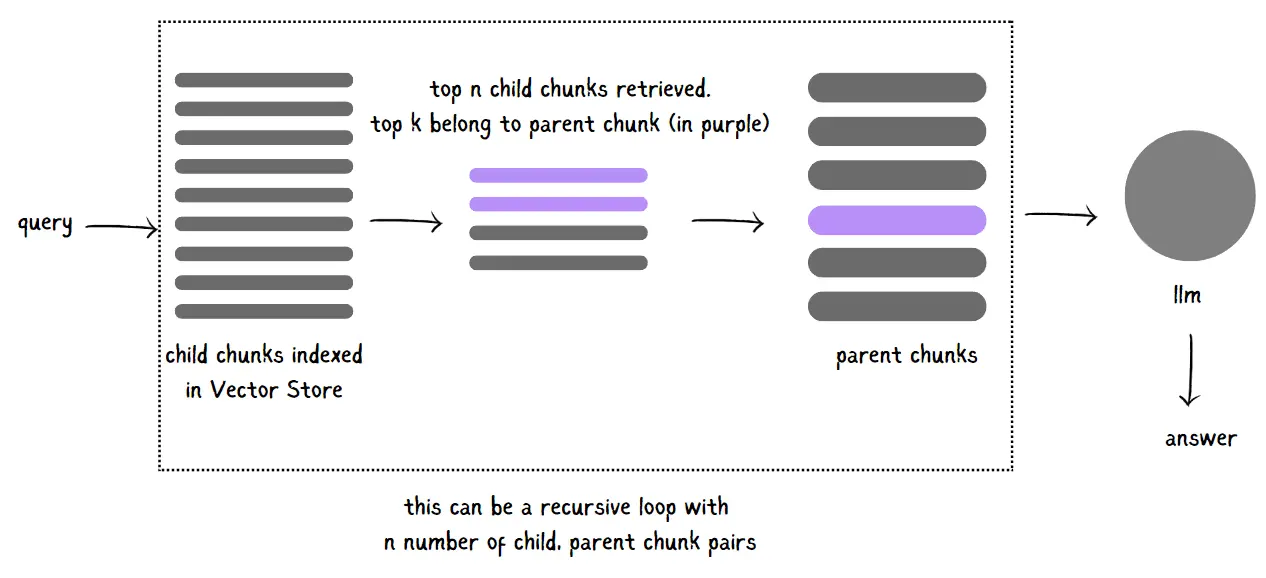
- Parent Document Retriever
In this method, documents are split into smaller “child” chunks, each referring back to a larger “parent” chunk. When you search, k child chunks are fetched. If n of these chunks come from the same parent, that parent chunk is what gets sent to the LLM.
This approach essentially lets your system auto-merge related chunks into a cohesive parent chunk, ensuring that you’re getting a richer, more complete view of the information without sacrificing retrieval precision.
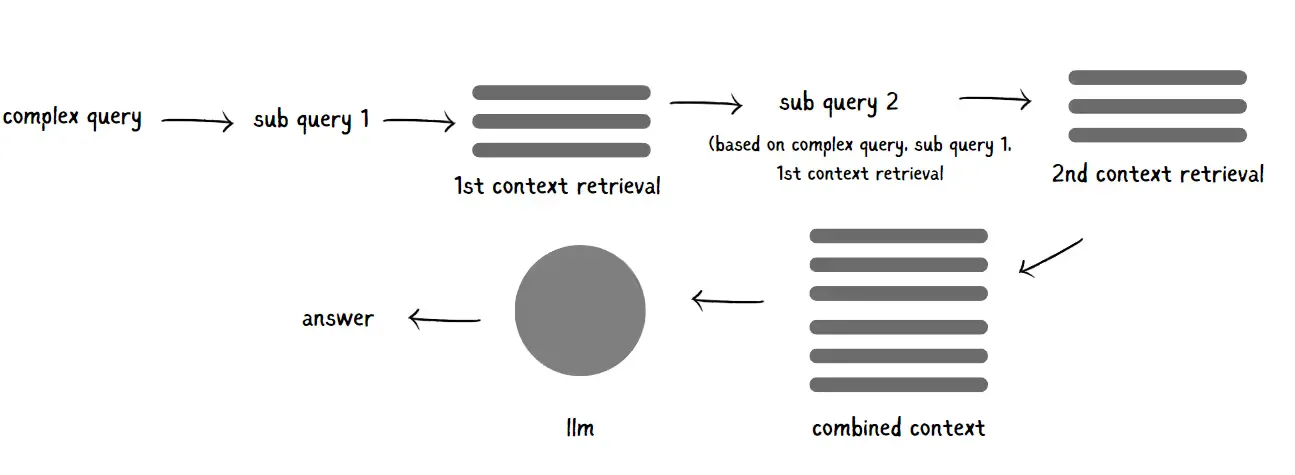
#4. Multi-Hop Question and Context Retrieval
In a multi-hop RAG pipeline, the original question is split into multiple, step-by-step queries, each one diving a bit deeper to uncover relevant information. At each hop, the language model creates a new query, retrieves context for it, and keeps building on what it’s learned. By the end, the model has gathered a rich, layered context that’s loaded with factual depth.
What’s the magic here? This approach is especially powerful for tackling complex questions, where one quick search just won’t cut it. As the model steps through each query, it gains a more nuanced and well-rounded understanding of the original question, leading to responses that are not only more precise but also contextually aware. With multi-hop RAG, you get answers that really “get” the heart of what you’re asking.
Take a look at this DSPy tutorial to know more about multi-hop question answering.
#5. Hybrid Search: Combing Sparse and Dense Embeddings
A hybrid search takes the best of both worlds by blending sparse and dense embeddings to improve retrieval accuracy. Here’s the breakdown: sparse embeddings represent documents and queries with vectors that correspond to specific terms in the vocabulary, making them perfect for exact term matching. On the other hand, dense embeddings capture the deeper semantic meaning and context.
In a hybrid search, you leverage each method’s unique strengths. First, separate searches are performed using sparse and dense embeddings, then the final results are fused using ranking techniques like Reciprocal Rerank Fusion (RFF), giving you results that are both relevant and nuanced.
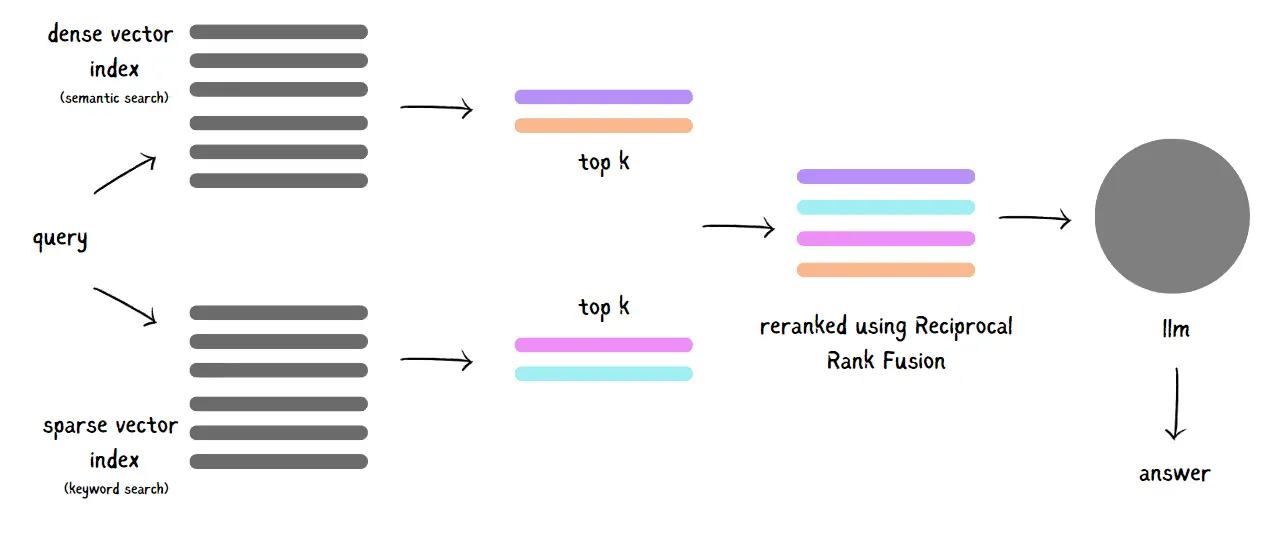
#6. Self-Querying Retrieval
With self-querying retrieval, the retriever takes things up a notch by effectively “asking itself” for a clearer, more structured version of the query. Say you start with a question like, “What are some sci-fi movies from the ’90s directed by Luc Besson about taxi drivers?” The retriever then uses the LLM to convert this natural language question into a structured query.
For instance, it might pull out filters from the question to narrow down results by genre, year, and director, then run a search based on these attributes, ensuring you get results that hit the mark. The final structured query would look something like this:
StructuredQuery(query='taxi driver', filter=Operation(operator=<Operator.AND: 'and'>, arguments=[Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='genre', value='science fiction'), Operation(operator=<Operator.AND: 'and'>, arguments=[Comparison(comparator=<Comparator.GTE: 'gte'>, attribute='year', value=1990), Comparison(comparator=<Comparator.LT: 'lt'>, attribute='year', value=2000)]), Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='director', value='Luc Besson')]), limit=None)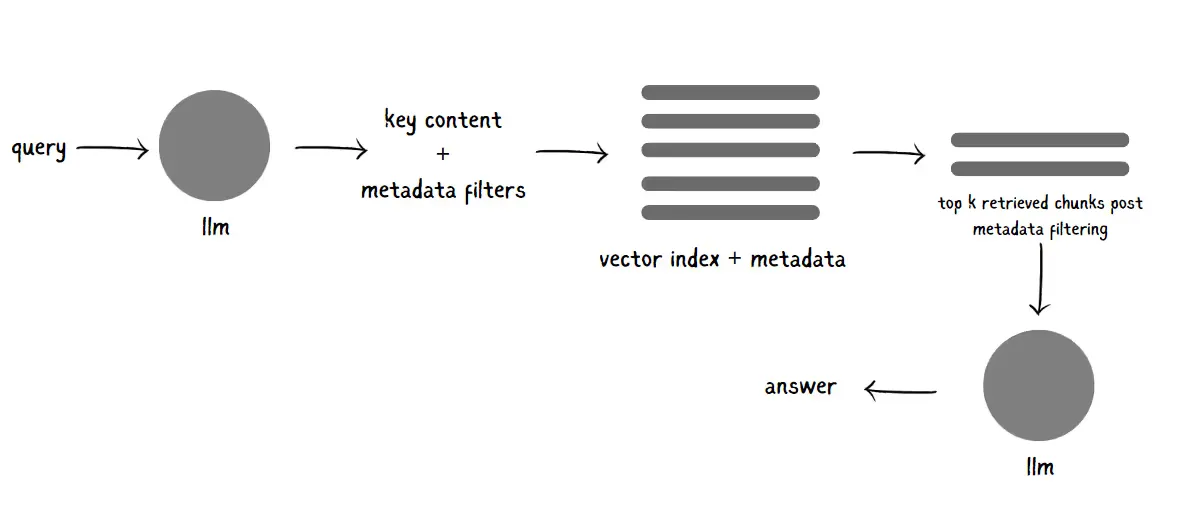
With self-querying, the search goes from general to laser-focused, pulling out the most relevant information every time.
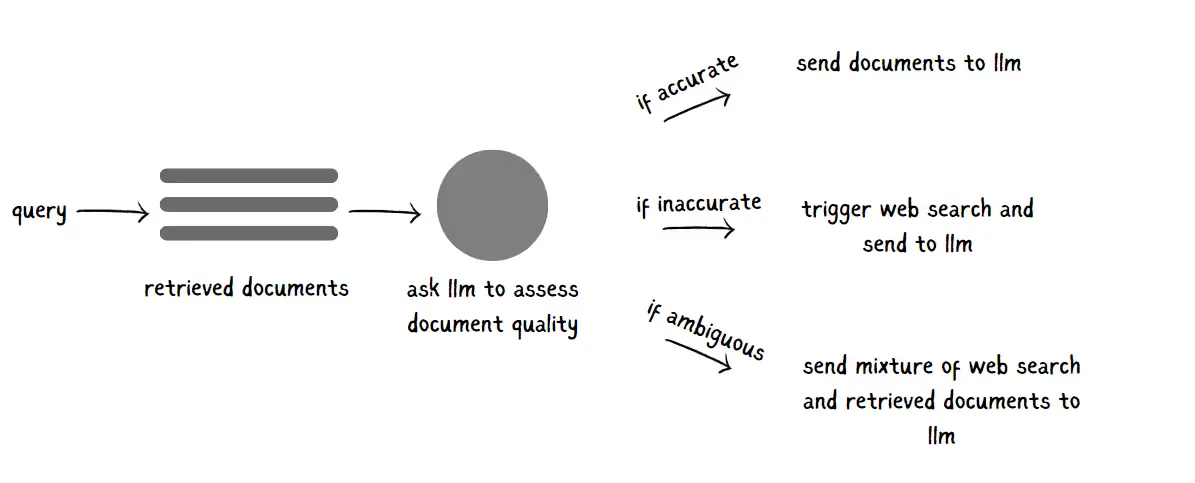
#7. Corrective RAG (CRAG)
Enter Corrective RAG (CRAG), a fresh approach introduced by Shi-Qi Yan et al. that doesn’t just rely on a vector database for context—it taps into real-time external data, like web searches, to enhance context quality. Here’s how it works: CRAG includes a lightweight evaluator that assigns confidence scores to retrieved documents, filtering out any less-reliable info.
CRAG goes even further with a decompose-then-recompose algorithm that extracts only the key details from retrieved documents, leaving irrelevant info behind. By drawing on external data sources and using precise filtering, CRAG gives your RAG model a clearer, more trustworthy context, leading to responses that are spot-on and up-to-date.
#8. Agentic RAG
In Agentic RAG, the core idea is to give an LLM some serious capabilities by equipping it with a range of tools and a clear task to tackle. Imagine the LLM not just passively generating responses but actively reasoning, deciding, and using the right tools to get the job done. These tools can include everything from code functions and external APIs to web searches, document summarizers, or even other agents.
Take the ReAct agent (Reason + Act) as an example. Here, the entire process unfolds in a series of steps. The LLM doesn’t just give an answer right away—it “thinks” through each step, deciding whether it needs to pull in extra information from one of its tools or if it’s ready to deliver a final answer. By reasoning through each action, it’s able to gather richer, more relevant information and generate responses that are highly accurate and targeted.
With Agentic RAG, your LLM goes from a static response generator to a dynamic, task-focused agent that can reason, act, and respond with greater depth.
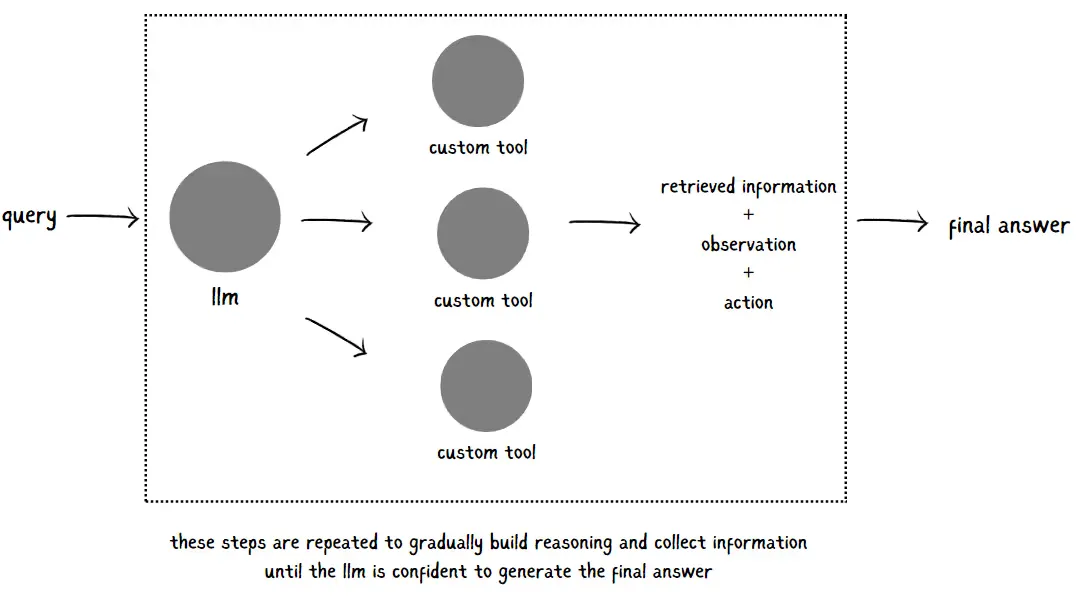
This modular setup lets the LLM flexibly interact with a range of tools, boosting its ability to tackle even the trickiest queries. By drawing on the right resources when needed, the LLM can generate responses that are not only more accurate but also packed with relevant context. It’s like giving the model a toolkit it can dip into on-the-fly, transforming it into a problem-solver that delivers smarter, sharper answers.
#9. Response Synthesizer
The most straightforward way to get a response in a RAG system is to simply gather all the context that meets a certain relevance threshold, tack it onto the query, and send it off to the LLM in one go. But if you’re after even more precise and insightful answers, there are some next-level methods to explore.
For instance, you can refine the answer iteratively by feeding the context to the LLM in smaller, manageable chunks, letting it build up a detailed response piece by piece. Another approach is to summarize the retrieved context to fit snugly within the prompt’s limits, ensuring you don’t lose the key details.
You could also try generating multiple answers from different chunks of context, then combining or summarizing them into a final response. These methods add layers of depth and precision, giving you answers that are not only accurate but rich with context.
#10. Prompt Optimizer
Right now, Prompt Optimizer is a unique feature of DSPy, and it’s like having a prompt-engineering ace on autopilot. This algorithm automatically adjusts the prompt (and even the model’s weights) to hit a specific target—like maximizing accuracy. For instance, in a multi-hop retrieval setup, you can set it to ensure each generated question stays on track, free from rambling or repetition.
Auto prompt optimization takes the guesswork out of prompt engineering, giving you a systematic, data-driven approach that consistently outperforms hand-crafted prompts. Think of it as a way to let the machine do the heavy lifting in finding the optimal prompt configuration, saving you time and delivering sharper results.
#11. Fine-Tuning
Fine-tuning is like giving your model a personalized upgrade, tailoring it to better handle specific tasks. It involves taking a pre-trained model and tweaking its weights with a smaller, targeted dataset. In a RAG setup, fine-tuning can make a difference at three key stages:
- Embedding Encoder Models: Fine-tuning here enhances how accurately your system retrieves relevant context, making sure each query pulls in the best possible information.
- Reranker Fine-Tuning: By fine-tuning the cross-encoder model (which reranks the top k chunks for each query), you can improve the quality of document ranking, making sure the most relevant info rises to the top.
- LLM Fine-Tuning: This one’s all about the end result. Fine-tuning the LLM itself ensures that your final responses are more on-point, with added depth and clarity suited to your domain.
With these tools in place, you’re not just building a RAG system—you’re crafting one that’s optimized for performance, precision, and relevance.
Conclusion
In conclusion, building an effective RAG system requires more than just a basic setup—it’s about leveraging advanced techniques that make each component work smarter and deliver richer, more accurate responses. To learn more about how you can use advanced RAG techniques in your business, write to us at [email protected].




-Feature-Image.CjBFdO7y_Z1bTNvg.webp)