
Overview
Let’s face it: those traditional BI tools and static dashboards just aren’t cutting it anymore. They’re like a rigid rulebook when you really need a conversation. You can’t ask a nuanced question, and they get totally lost when you try to mix and match different kinds of data.
This is where we’re going to build something smarter.
We’re creating an intelligent agent that uses LLM function calling to understand what you’re asking, just like a person would. But the real power comes from its hybrid approach. Our agent doesn’t just rely on one tool; it intelligently orchestrates a combination of two powerful engines (SQL + Meilisearch) to explore complex e-commerce data:
For the Deep Dives: SQL (using PostgreSQL)
This is the engine for all your detailed, analytical queries. When you ask a complex question like, “What was the average order value for our top-selling products in the last quarter?”, the agent knows to fire up a robust SQL query to get a precise, structured answer from your database.
For the Fast and Flexible: Meilisearch
This is where the magic happens for unstructured and semantic searches. If you’re looking for customer feedback and ask, “Show me reviews mentioning a ‘durable and stylish backpack,’ ” the agent will use Meilisearch to quickly scan thousands of reviews and pull the most relevant results.
By combining these two powerful tools, our agent overcomes the limitations of older systems. It can seamlessly handle everything from complex analytical queries to unstructured, natural language searches. It’s a flexible and powerful way to explore your data, turning your questions into actionable insights without the headache.
Section 1: Setting the Stage
1.1 Why Analytics Agents?
The demand for more intuitive and powerful data analysis tools is growing. Imagine asking your BI tool, “How many new users bought a Samsung phone in the last quarter?” A traditional dashboard might not have a pre-configured widget for this. It requires:
- Semantic understanding: Recognizing that “Samsung phone” is a brand and category combination.
- Structured analysis: Filtering transactions by date and joining them with user data.
This is where analytics agents shine. They provide:
- Natural Language Interface: Users can ask questions in plain English, not SQL Query.
- Hybrid Querying: Seamlessly combining the strengths of semantic search (Meilisearch) and SQL (Postgres).
- Real-time Exploration: Answering new questions on the fly, without needing a developer to build a new dashboard.
1.2 Architectural Overview
Here, for our agent’s architecture, we are using a multi-layered system designed for robustness and flexibility.
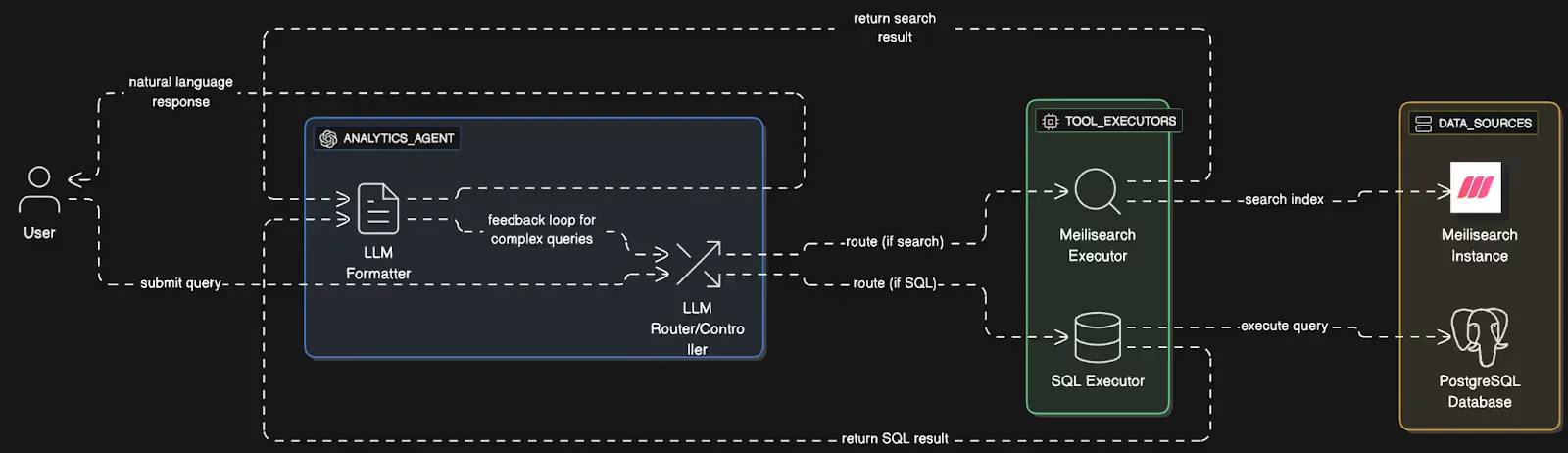
Section 2: Designing the E-commerce Dataset Schema
A well-defined schema is the foundation of our analytical capabilities. We will use a relational database for core transactional data and a search engine for fast, flexible lookups. You can see the dataset here:
def generate_users(num_users=200):
return users
def generate_products(num_products=100):
return products
def generate_transactions(users, products, num_transactions=1000):
return transactions
2.1 PostgreSQL Schema
PostgreSQL will store our primary, structured e-commerce data. This schema supports complex joins and aggregations.
class User(Base):
__tablename__ = 'users'
user_id = Column(String, primary_key=True)
name = Column(String)
email = Column(String, unique=True)
location = Column(String)
registration_date = Column(Date)
class Product(Base):
__tablename__ = 'products'
product_id = Column(String, primary_key=True)
name = Column(String)
category = Column(String)
brand = Column(String)
price = Column(Numeric)
class Transaction(Base):
__tablename__ = 'transactions'
order_id = Column(String, primary_key=True)
user_id = Column(String, ForeignKey('users.user_id'))
product_id = Column(String, ForeignKey('products.product_id'))
amount = Column(Numeric)
timestamp = Column(DateTime)
status = Column(String)
2.2 Meilisearch Schema
Meilisearch will be used for fast, typo-tolerant searching of product names and user details. We will sync our products and users tables to Meilisearch.
Indexing Strategies:
-
products index:
- Searchable Attributes: Name, category, brand. This allows for fuzzy searches like find products named “iPhn” to correctly match “iPhone”.
- Filterable Attributes: Category, brand, price. This enables structured filtering within the search query (e.g., products with price < 500).
-
users index
- Searchable Attributes: Name, email
- Filterable Attributes: Location, registration_date
Section 3: Implementing Hybrid Query Logic
The LLM is the core of our system, and we must define its capabilities using a Function Calling API. We will create three core tools.
3.1 Function Calling Design
Each tool is defined with a schema that the LLM can understand, allowing it to generate the correct function calls with appropriate parameters. This example uses a JSON schema format compatible with services like OpenAI’s API.
tools = [
{
"type": "function",
"function": {
"name": "meilisearch_query",
"description": "Searches for products or users in Meilisearch. Use this for free-text search, fuzzy matching, or combined with filters on indexed attributes like category, brand, price for products, or location, registration_date, email for users. Index names are 'products' and 'users'.",
"parameters": {
"type": "object",
"properties": {
"index_name": {
"type": "string",
"description": "The name of the Meilisearch index to query. Must be 'products' or 'users'.",
"enum": ["products", "users"]
},
"query": {
"type": "string",
"description": "The free-text search query string. Optional.",
"default": ""
},
"filters": {
"type": "string",
"description": "A Meilisearch filter string for structured filtering (e.g., 'category = \"Electronics\" AND price < 500'). Attributes: products (category, brand, price), users (location, registration_date, email). Use `CONTAINS` or `STARTS WITH` for partial string matches (e.g., 'email CONTAINS \".com\"').",
"default": ""
}
},
"required": ["index_name"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_sql_query",
"description": "Executes a SQL query against the PostgreSQL database. Use this for analytical queries, aggregations, joins, or when precise numerical or date-based filtering/grouping is needed across multiple tables (products, users, transactions).",
"parameters": {
"type": "object",
"properties": {
"sql_query": {
"type": "string",
"description": "The full SQL query to execute, including SELECT, FROM, WHERE, GROUP BY, ORDER BY, etc."
}
},
"required": ["sql_query"]
}
}
},
{
"type": "function",
"function": {
"name": "generate_chart",
"description": "Generates a visual chart (e.g., bar chart, line chart) from provided tabular data. Use this when the user explicitly asks for a chart, graph, or visualization. Requires data, chart type, and columns for X and Y axes.",
"parameters": {
"type": "object",
"properties": {
"data": {
"type": "array",
"items": {"type": "object"},
"description": "The tabular data as a list of dictionaries (e.g., the 'data' field from an execute_sql_query output). Each dictionary is a row."
},
"chart_type": {
"type": "string",
"enum": ["bar", "line"],
"description": "The type of chart to generate ('bar' for categorical comparisons, 'line' for trends over time)."
},
"x_column": {
"type": "string",
"description": "The name of the column from the 'data' to use for the X-axis (e.g., 'month', 'category')."
},
"y_column": {
"type": "string",
"description": "The name of the column from the 'data' to use for the Y-axis (e.g., 'total_sales_amount', 'average_price')."
},
"title": {
"type": "string",
"description": "The title of the chart."
},
"x_label": {
"type": "string",
"description": "Optional label for the X-axis."
},
"y_label": {
"type": "string",
"description": "Optional label for the Y-axis."
},
"filename": {
"type": "string",
"description": "Optional filename for the saved chart image (e.g., 'sales_by_month.png'). If not provided, a unique name will be generated."
}
},
"required": ["data", "chart_type", "x_column", "y_column", "title"]
}
}
}
]
Section 4: Building the SQL Execution Layer
PostgreSQL Connection Setup
We’ll use SQLAlchemy, a robust SQL toolkit for Python, to handle database connections and protect against SQL injection.
def execute_sql_query(sql_query: str):
"""
Executes a given SQL query against the PostgreSQL database.
Includes validation to ensure only safe SELECT queries are executed.
Returns the results as a dictionary or an error message.
"""
# --- SQL Query Validation---
normalized_query = sql_query.strip().upper() # Normalize for case-insensitive checks
# 1. Check for allowed operations (must start with SELECT)
if not normalized_query.startswith("SELECT"):
error_msg = f"SQL Validation Error: Only SELECT queries are allowed. Detected: '{sql_query[:50]}...'"
logger.warning(error_msg)
return {"success": False, "message": error_msg, "data": None}
# 2. Prevent destructive DDL/DML operations
forbidden_keywords = [
"INSERT", "UPDATE", "DELETE", "DROP", "ALTER", "CREATE", "TRUNCATE",
"GRANT", "REVOKE", "RENAME", "ATTACH", "DETACH", "PRAGMA", "VACUUM",
";--", "--", "/*", "*/", # Basic comment/injection prevention
"UNION ALL SELECT", "UNION SELECT", # Common in SQL injection, though not destructive on their own
"OR 1=1", "OR '1'='1'" # Common injection patterns
]
for keyword in forbidden_keywords:
if keyword in normalized_query:
error_msg = f"SQL Validation Error: Forbidden keyword '{keyword}' detected in query. Only analytical SELECT queries are permitted."
logger.warning(error_msg)
return {"success": False, "message": error_msg, "data": None}
# --- End SQL Query Validation ---
db_url = os.getenv("DATABASE_URL")
try:
engine = create_engine(db_url)
logger.info(f"Executing SQL: {sql_query}")
with engine.connect() as connection:
result = connection.execute(text(sql_query))
connection.commit()
if result.returns_rows:
rows = []
for row in result:
row_dict = {}
for key, value in row._mapping.items():
row_dict[key] = value
rows.append(row_dict)
return {"success": True, "message": "SQL query executed successfully.", "data": rows}
else:
return {"success": True, "message": f"SQL command executed. Rows affected: {result.rowcount}", "data": None}
except Exception as e:
logger.error(f"Error executing SQL query: {e}")
return {"success": False, "message": f"Error executing SQL query: {e}", "data": None}Section 5: Integrating Meilisearch for Semantic Filtering
5.1 Setup and Sync
For real-time data, our Meilisearch instance needs to be kept in sync with our PostgreSQL tables. This can be achieved with an ETL job that runs periodically or, for more dynamic updates, using database triggers that push changes to Meilisearch.
5.2 Search Use Cases
- Fuzzy product name search: A user types find all “loptop”. The LLM calls meilisearch_query(index=‘products’, query=‘loptop’), and Meilisearch intelligently returns results for “Laptop”.
- Combined search and filter: meilisearch_query(index=‘products’, query=‘watch’, filters=‘brand = “Samsung”’) returns all “Samsung” branded watches.
def meilisearch_query(index_name: str, query: str = None, filters: str = None, limit: int = 10, offset: int = 0) -> str:
"""
Performs a search query against a specified Meilisearch index using the Meilisearch Python SDK.
Args:
index_name (str): The UID of the Meilisearch index to search (e.g., "products" or "users").
query (str, optional): The search query string.
filters (str, optional): A Meilisearch filter string.
limit (int, optional): The maximum number of results to return.
offset (int, optional): The number of results to skip.
Returns:
str: JSON string representing the search results or error message.
"""
if index_name not in ["products", "users"]:
error_msg = f"Invalid index_name. Must be 'products' or 'users'. Got: {index_name}"
logger.warning(error_msg)
return json.dumps({"error": error_msg})
try:
index = meili_client.index(index_name)
# All search options (except the main query string) go into this dictionary
search_options = {
"limit": limit,
"offset": offset
}
if filters:
search_options["filter"] = filters
logger.info(f"Performing Meilisearch query on index '{index_name}' with query='{query}', options={search_options}")
# Pass the query string as the first positional argument,
# and search_options as the second (unpacked) argument.
results = index.search(query, search_options)
return json.dumps({
"hits": results.get("hits", []),
"estimatedTotalHits": results.get("estimatedTotalHits", 0)
}, indent=2)
except meilisearch.errors.MeilisearchApiError as e:
logger.error(f"Meilisearch API error during query: {e}")
return json.dumps({
"error": "Meilisearch API error",
"code": e.code,
"message": e.message,
"type": e.type,
"link": e.link
})
except Exception as e:
logger.error(f"Unexpected error during Meilisearch query: {e}", exc_info=True)
return json.dumps({
"error": "Unexpected error",
"message": str(e),
"type": type(e).__name__,
"details": f"Occurred while searching index '{index_name}'"
})
Section 6: Query Routing and Combining Results
6.1 Deciding When to Use Which Backend
The LLM’s system prompt is the key to this decision. We instruct it to:
- Use meilisearch_query: For single-entity search, fuzzy matching, and basic filters.
- Use sql_query_executor: For any request involving aggregations (SUM, AVG), joins, time-series analysis, or complex numerical filtering.
- Use a combination: For queries that require an ID from a search result to perform a precise analytical query.
6.2 Join Strategy
A common and powerful pattern is to use Meilisearch to get an ID and then pass that ID to a SQL query.
Example Query: “What’s the total sales amount for all Apple products?”
Agent’s Execution:
- LLM Call 1: Recognizes the need to find Apple products first.
- Tool Call: meilisearch_query(index=‘products’, filters=‘brand = “Apple”’)
- Tool Output 1: Meilisearch returns a list of dictionaries, each containing a product_id.
- LLM Call 2: Extracts all product_ids from the Meilisearch output (e.g., [‘id1’, ‘id2’, …]) and constructs a SQL query.
- Tool Call: sql_query_executor
Final Response: The SQL tool returns the total sales amount, which the LLM then formats into a final answer.
Section 7: Handling Analytical Queries
The sql_query_executor tool is the backbone of our analytics capabilities. It enables the agent to handle complex data questions.
7.1 Aggregations and Time-Series Analysis
The LLM can translate a request like “Show me sales trends for MacBooks over the last 12 months” into a complex SQL query that groups by month.
7.2 Grouping and Cohort Analysis
The LLM can generate SQL queries for grouping data. For example, “Compare average order value between Bangalore and Mumbai” would translate to:
7.3 Visual and Natural Language Output
For simple results, the LLM can provide a natural language summary. For larger datasets, the agent uses the third tool (e.g., a chart generator) to produce a visualization from the tabular SQL data. For this we are going to use matplotlib to generate the charts.
Section 8: Improving LLM Accuracy and Guardrails
8.1 Query Validation
Before executing any SQL, the agent should perform a basic validation. The LLM can be instructed to never use DROP, DELETE, or UPDATE in its queries, effectively making the tool read-only.
8.2 Prompt Engineering
The system prompt is key to the agent’s performance. It should be meticulously engineered with examples and clear instructions on when to use each tool, what to expect as output, and how to chain them together.
8.3 Guardrails
To ensure safety and reliability, implement a layered guardrail system:
- Database-level: Use a read-only database user for the agent.
- Agent-level: Filter out malicious keywords (DROP TABLE, DELETE FROM) from the generated SQL before execution.
LLM-level: Provide clear, strict instructions in the system prompt to prevent dangerous queries.
Section 9: Example Interactions and Demos
Here are a few examples of how this agent would process user queries:
-
Query: “What is the total sales for iPhones?”
-
Agent: Calls meilisearch_query for “iPhone” to get product_ids. Uses those IDs in a sql_query_executor to get the SUM(amount) from transactions.
-
Response: “The total sales for all iPhones is ₹4,567,890.”
-
Query: “List all users who purchased a Samsung phone more than once in the last year.”
-
Agent: Calls meilisearch_query for brand = “Samsung” to get a list of product_ids. Uses those IDs in a sql_query_executor with a GROUP BY user_id HAVING COUNT(*) > 1 clause and a date filter.
-
Response: “Here are the users who bought a Samsung phone more than once in the last year: user_a, user_d, user_z”
Section 10: Deployment and Next Steps
10.1 Hosting and Infrastructure
A common setup for this architecture would be:
- Backend: A FastAPI application with Uvicorn.
- LLM: The OpenAI API provides a reliable and easy-to-use endpoint for function calling.
- Database: A managed PostgreSQL instance (Docker Setup)
- Search Engine: A hosted Meilisearch instance (Meilisearch Cloud) or Meilisearch SDK (a self-hosted Docker container)
10.2 Scaling Considerations
- Caching: Cache LLM calls for identical queries to reduce latency and cost.
- Asynchronous Execution: Use asyncio to handle multiple long-running SQL queries without blocking the server.
- Incremental Indexing: Configure Meilisearch to perform incremental indexing to keep the search data fresh with minimal performance impact.
GitHub
To see the full code click here
Conclusion
Building a hybrid analytics agent is a powerful step towards creating more intuitive and intelligent data tools. The combination of an LLM’s reasoning with specialized backends provides a robust and scalable solution for modern data challenges.
To learn more, speak to us.




-Feature-Image.CjBFdO7y_Z1bTNvg.webp)