
Large Language Models (LLMs) have revolutionized the field of natural language processing (NLP) with their ability to generate human-like text and understand complex language patterns. However, these models are often trained on vast amounts of general-purpose data, which can lead to biases, inconsistencies, and a lack of domain-specific knowledge. To address these limitations and to unlock the full potential of LLMs, two key techniques are employed: fine-tuning and grounding.
Fine-tuning involves further training an LLM on a specific domain or task, allowing it to adapt its knowledge and language generation capabilities to the target area and tailoring these advanced algorithms to specific tasks or domains. This process enhances the model’s performance on specialized tasks and significantly broadens its applicability across various fields. This means we can take advantage of the NLP capacity of pre-trained LLMs and further train them to perform our specific tasks.
Grounding: While LLMs come with a vast amount of knowledge already, this knowledge is limited and not tailored to specific use cases. To obtain accurate and relevant output, we must provide LLMs with the necessary information. In other words, we need to “ground” the models in the context of our specific use case. This involves incorporating external knowledge sources, such as databases or knowledge graphs, into the LLM’s reasoning process, enabling it to access and leverage factual information beyond its initial training data. It is crucial for ensuring the quality, accuracy, and relevance of the generated output.
What Is Fine-Tuning?
Fine-tuning is the process of taking any pre-trained model and further training it on a specific dataset or task. This is not just specific to LLMs; fine-tuning existed way before LLMs existed, but today we’ll specifically talk about what fine-tuning means in the LLM realm.
Most LLM models today have a very good global performance but fail in specific task-oriented problems. Like asking ChatGPT to solve a complex Math problem. The fine-tuning process offers considerable advantages, including lowered computation expenses and the ability to leverage cutting-edge models without the necessity of building one from the ground up. It is like picking up a general-purpose LLM (Open-source/GPT) and training it on a task-specific dataset of Math questions and answers, and teaching that model to learn and even solve Math problems (MathGPT).
This additional training phase allows the model to specialize in the target domain, learning the relevant vocabulary, writing styles, and domain-specific patterns. This can be particularly beneficial for tasks such as text summarization, question answering, and language generation in specialized fields like legal, medical, or scientific domains. Like taking a basic question-answering model and fine-tuning it on legal documents, legal QnA, and knowledge statutes, and making the model better in answering legal queries (LegalGPT).
During fine-tuning, the pre-trained LLM’s weights are adjusted to better capture the nuances and intricacies of the target domain. Like in our LegalGPT case, the pre-trained model which is picked up is fine-tuned and its weights are updated during the training phase, to make the model learn those intricacies. There are specialized steps involved in this whole process, which I will discuss further.
What Is RAG (Retrieval Augmented Generation)?
Retrieval Augmented Generation (RAG) is the primary technique for grounding and the one I will discuss in detail. It is a process for retrieving information relevant to a task that we want the LLM to perform, by providing a prompt to the language model and relying on the model to use this specific information when responding. It combines the power of LLMs with external knowledge sources, such as vector databases or knowledge graphs.
The retrieval component typically uses information retrieval techniques, such as keyword matching or semantic similarity, to identify and retrieve the most relevant pieces of information from the knowledge source based on the input text or query. This retrieved information is then provided to the LLM, which can incorporate it into its language generation process, resulting in more accurate and informative outputs. LLMs have drawbacks due to their knowledge cutoff, leading to confident but inaccurate responses. Like you might remember ChatGPT giving out the response, “… knowledge is based on information available up until January 2022. If there have been any developments or changes since then, I may not be aware of them.”, so imagine if you can make the model up to date by providing up-to-date knowledge via RAG. Therefore, RAG systems aim to address this knowledge cutoff issue, among others, by incorporating factual information during response generation to prevent hallucination and retrieve accurate responses.
How Does Fine-Tuning Differ from RAG? Pros vs Cons
Fine-tuning and RAG are complementary techniques that address different aspects of an LLM’s performance.
-
Fine-tuning focuses on adapting the LLM’s language generation capabilities to a specific domain or task; for example, if we want to make the LLM answer in a specific way or learn the capabilities of answering in a specific language, we would fine-tune the LLM on that task-specific dataset.
-
While RAG augments the LLM with external knowledge sources to enhance its factual accuracy and information coverage. This makes the model more aware of recent updates; for example, for LegalGPT, we would want the model to answer from a specific text or specific case laws, so we would want to create a knowledge database for the model via RAG, which makes the model more factually accurate.
Advantages of Fine-Tuning
- Allows the LLM to learn domain-specific patterns, vocabulary, and writing styles, resulting in more natural and coherent language generation within the target domain.
- It leads to improved performance in various business domains. Fine-tuning allows businesses to control the data the model is exposed to, ensuring that the generated content doesn’t inadvertently leak sensitive information.
- For example: if you want to use LLMs for customer interactions, like chatbots, fine-tuning helps tailor responses to match your brand’s voice, tone, and guidelines. This ensures a consistent and branded UX.
- Finally, for tasks that heavily rely on domain-specific language patterns like writing styles or coding styles, fine-tuning may be more beneficial.
Cons
- Traditional fine-tuning embeds data into the model’s architecture, which prevents easy modification.
- Fine-tuning alone may not address the LLM’s lack of factual knowledge or its potential to generate inconsistent or biased outputs based on its initial training data.
Advantages of RAG
- It provides the LLM with access to external knowledge sources, enabling it to generate outputs that are more accurate, up-to-date, and factually grounded.
- It offers a cost-effective solution by leveraging an LLM and augmenting it with retrieval mechanisms; this can save businesses both time and money while still achieving excellent results.
- Helps with greater transparency and visibility. When RAG generates a response, it can also cite the sources it drew from, enhancing trust in users.
- Finally, for tasks that require a high degree of factual accuracy and knowledge coverage, RAG may be the preferred approach.
Cons
- RAG relies on the quality and coverage of the external knowledge source, and it may struggle with generating coherent and natural language responses if the retrieved information is not properly integrated into the LLM’s generation process.
- RAG’s effectiveness is constrained by the data it has in the knowledge base, potentially limiting its adaptability and accuracy.
RAG and fine-tuning are often perceived as competing methods. However, their combined use can lead to significantly enhanced performance.
Steps to Fine-Tune
Fine-tuning an LLM for a specific domain or task involves several steps to ensure effective adaptation and performance. Let’s look at a general outline of the process:
For this whole process, a Cloud Platform could be used: My personal fav is E2E as they give me the flexibility to switch between GPUs and provide comfortable pricing as well. Once you have taken and logged into the GPU Instance, you can run a docker container using the following command:
sudo docker run -it --rm -v your_dir:/workspace/pl -p 8888:8888 nvcr.io/nvidia/pytorch:24.02-py3Install and run jupyterlab on the GPU instance:
pip install jupyter jupyterlab
jupyter lab –allow-root –ip=0.0.0.0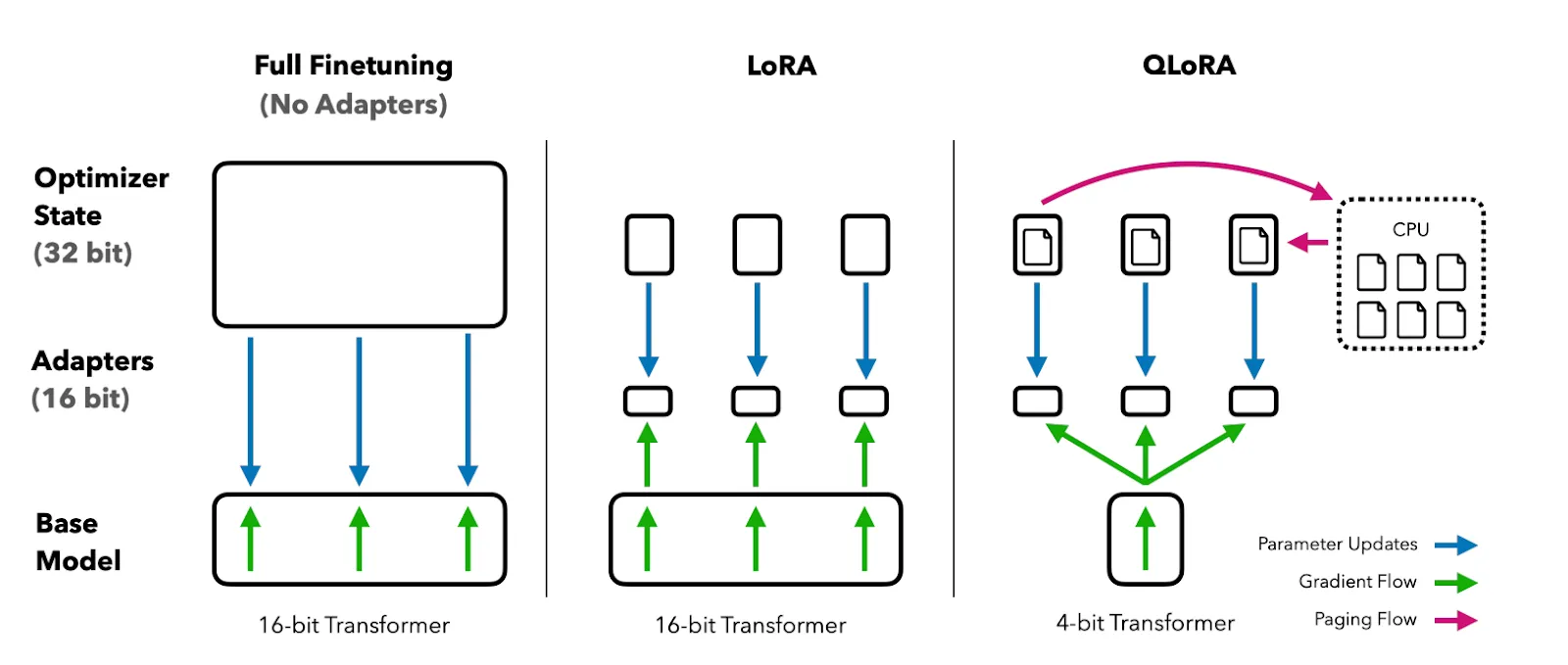
You can read the paper to understand QLoRA fine-tuning much better.
Data Preparation: Gathering a high-quality dataset relevant to the target domain or task is important. This dataset should be representative of the language patterns, vocabulary, and writing styles you want the LLM to learn. For example: For our use case of training an LLM model on Indian laws, articles, and judicial laws, we would be using an open-source dataset: https://huggingface.co/datasets/nisaar/Articles_Constitution_3300_Instruction_Set
Data Cleaning and Preprocessing: Clean and preprocess the dataset to remove any noise, inconsistencies, or irrelevant information. This may involve text normalization, tokenization, and handling special characters or domain-specific formatting. For example: in our case, the dataset we are using is already formatted in an instruction format like:
Instruction: The given instruction: Analyze and explain the legal reasoning behind the judgment in the given case.
Input: The legal case: Central Inland Water Transport Corporation Ltd. vs Brojo Nath Ganguly & Anr., 1986 AIR 1571, 1986 SCR (2) 278
Output: The response: Supreme Court, in this case, applied a broad interpretation of the term ‘State’ under Article 12 of the Constitution …
Prompt: The context for the instruction, input, and output.
Vocabulary Cleanup: Analyze the dataset to identify domain-specific terms, acronyms, and jargon that may not be present in the LLM’s initial vocabulary. Create a custom vocabulary or update the existing one to include these domain-specific terms. In our case, there won’t be any vocabulary added in the model as all the words present in the dataset are in the English language and the model we would be picking up is pre-trained on the English vocab. If you think you are adding a new word or training for a different language like training on an Indic language, then in that case you would have to do this step.
Model Selection and Initialization: Choose an appropriate pre-trained LLM as the starting point for fine-tuning. This choice may depend on the model’s size, architecture, and initial training data. In our case we would be picking up a pre-trained Llama2 model with the model size of 7 Billion: https://huggingface.co/TinyPixel/Llama-2-7B-bf16-sharded
Fine-Tuning Setup: Set up the fine-tuning process by defining the appropriate hyperparameters, such as learning rate, batch size, and number of epochs. Additionally, determine the appropriate loss function and optimization algorithm based on the target task (e.g., language modeling, sequence classification, or question answering). In our specific case, we would be using the SFTTrainer from TRL library that gives a wrapper around transformers trainer to easily fine-tune models on instruction-based datasets using PEFT adapters.
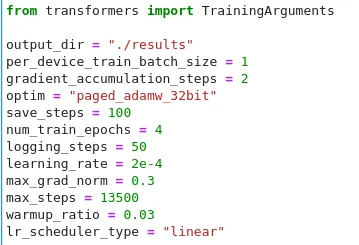
Fine-Tuning Training: Train the LLM on the domain-specific dataset using the fine-tuning setup. During this process, the model’s weights are adjusted to capture the patterns and nuances of the target domain or task. In our case, we would be fine-tuning the Llama2-7B model on the instruction dataset that we have on Indian Laws and case laws.
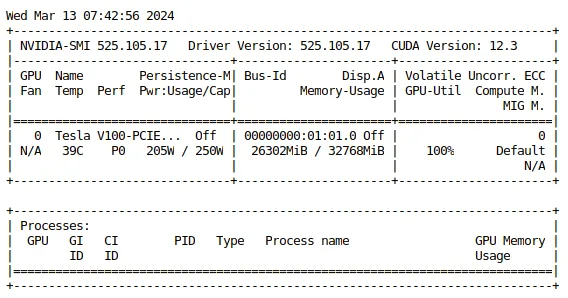
As the training starts, you should be able to see GPU memory to fill up with the model and you’d also be able to see GPU Utilization to go up to 100% if everything is good. You can open up a terminal in the E2E GPU instance nvidia-smi command to see the usage.
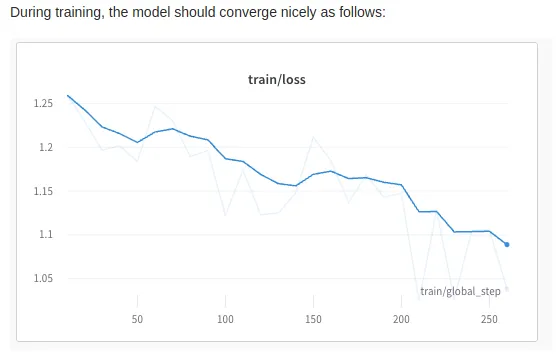
Evaluation and Iteration: Evaluate the fine-tuned model’s performance on a held-out test set or relevant benchmarks. If the performance is not satisfactory, iterate on the fine-tuning process by adjusting hyperparameters, modifying the dataset, or exploring different model architectures or initialization strategies. In our case, we do have a held-out test set, which we can use to test the performance of the model; as the loss is converging and giving us good numbers, we can say that the hyperparameters that we selected were good, but you should feel free to play around with different aspects of the model. This would help you understand changing what parameter has what effect on the model’s performance.
Saving the fine-tuned model in desk: model.save_pretrained(“trained-model”)
Deployment and Monitoring: Once the fine-tuned model meets the desired performance criteria, deploying is the obvious next step, where the model can be consumed via an API into a service or an end-user application. Continuous monitoring is also a very important part and helps us to keep the model’s performance in check; in our case, our fine-tuned LawyerGPT is trained on Indian case laws and is now well-equipped to answer questions around the Indian judiciary landscape.
For deployment, a cloud platform like E2E can be leveraged.
Building RAG on the Fine-Tuned Model
While fine-tuning focuses on adapting the LLM’s language generation capabilities to a specific domain, RAG enhances the LLM’s factual knowledge and information coverage by incorporating external knowledge sources. Building RAG on top of a fine-tuned model can provide the best of both worlds, combining domain-specific language generation with accurate and up-to-date factual information. For example: in our case of LawyerGPT providing the model with case law, statues, and other related additional documents would help the model expand its knowledge base and help us to cover a lot more factual knowledge and things that were not covered in the dataset.
Let’s talk about a general outline of the steps involved in building RAG on any kind of LLM:
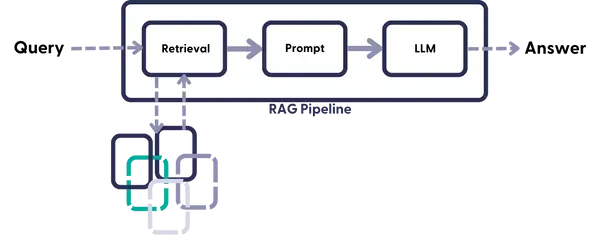
Pick an LLM: You can directly pick a vanilla LLM or follow the steps to fine-tune the LLM on the target domain or task, ensuring that it has learned the relevant language patterns and vocabulary.
Prepare the Knowledge Source: Identify and prepare the external knowledge source(s) that will be used to augment the LLM’s generation process. This could be a structured database, a knowledge graph, or a collection of relevant documents or web pages. For example: in our case of LawyerGPT, collet pdfs of case laws and other relevant docs from judicial websites, let’s say you want better and factually correct results for cases related to ‘money laundering’, so getting relevant docs from Ecourts and creating a vector database out of it would be necessary.
Chunking Documents: As the document in its original state is too long to fit into the LLM’s context window, we need to chunk it into smaller pieces. For this simple example, you can use the CharacterTextSplitter with a chunk_size of about 500 and a chunk_overlap of 50 to preserve text continuity between the chunks.
Embed and Store Chunks: To enable semantic search across the text chunks, we need to generate the vector embeddings for each chunk and then store them together with their embeddings. To generate the vector embeddings, we can use the OpenAI embedding model and, to store them, we can use the Weaviate/Pinecone vector database.
Augment and Generate: The final step is to query from the vector database created and get a response from the LLM. Llama Index/Langchain provides a query engine for querying and putting it together with the LLM for a chat-like conversation.
By combining fine-tuning and RAG, the resulting model can generate domain-specific, natural language outputs while leveraging external knowledge sources to enhance factual accuracy and information coverage. This approach can be particularly beneficial in our use case of LawyerGPT as both domain-specific language patterns and up-to-date factual information are crucial in such use cases.
Conclusion
Large Language Models (LLMs) have revolutionized the field of NLP, but their full potential can only be unlocked through techniques like fine-tuning and grounding. These techniques not only enhance the performance of LLMs but also help mitigate potential biases and inconsistencies, ensuring that the generated outputs are reliable, accurate, and tailored to the specific needs of the target domain or task.




-Feature-Image.CjBFdO7y_Z1bTNvg.webp)