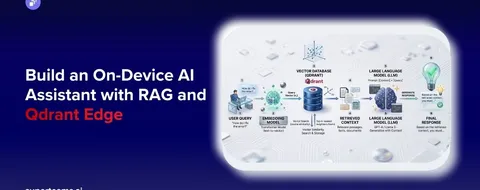
You’ve got users typing messy, half-remembered queries—“black running shoes breathable,” “refund policy image,” “how do I export orders?”—and they expect great results instantly. There isn’t one “best” search method for all of that. In this guide, you’ll learn when to reach for TF-IDF or BM25, when sparse vectors shine, and when a hybrid setup beats them all. We’ll build the intuition first, then show you how to wire it up in Qdrant, which handles dense and sparse vectors side-by-side without the plumbing headaches.
Deep Dive: Understanding the Algorithms
Let’s unpack each of these search algorithms, understanding their core principles, mathematical underpinnings, and typical applications.
1. TF-IDF: The Foundational Pillar
TF-IDF (Term Frequency-Inverse Document Frequency) is a measure of the importance of a word to a document in a collection or corpus, adjusted for the fact that some words appear more frequently in general. It models a document as a multiset of words, without considering word order, and refines the simple bag-of-words model by allowing the weight of words to depend on the rest of the corpus. This weighting factor has been widely used in information retrieval, text mining, and recommender systems.
TF-IDF is the product of two statistics: term frequency (TF) and inverse document frequency (IDF). A high TF-IDF weight is achieved by a high term frequency in the given document and a low document frequency of the term across the entire collection, effectively down-weighting common terms.

TF-IDF was commonly used in early open-domain QA systems and remains a central tool in scoring and ranking a document’s relevance given a user query. It’s widely used in text search and recommender systems, with a 2015 survey showing 83% of text-based recommender systems in digital libraries using it.
Preprocessing of Data
Here is how I have cleaned the Data and converted it to DataFrame
def clean_text(text: str) -> str:
"""Clean text by lowercasing, removing punctuation, and normalizing whitespace"""
if pd.isna(text):
return ""
text = text.lower()
text = re.sub(f'[{re.escape(string.punctuation)}]', ' ', text)
text = re.sub(r'\s+', ' ', text).strip()
return text
def load_and_preprocess_data(csv_path: str) -> pd.DataFrame:
"""Load and preprocess the e-commerce dataset"""
df = pd.read_csv(csv_path)
# Combine relevant text fields
text_columns = ['title', 'description', 'attributes']
available_columns = [col for col in text_columns if col in df.columns]
df['combined_text'] = df[available_columns].fillna('').apply(
lambda row: ' '.join(row.values.astype(str)), axis=1
)
# Clean the combined text
df['cleaned_text'] = df['combined_text'].apply(clean_text)
return df
How do we index it for TF-IDF?
def index_tfidf_collection(self, df: pd.DataFrame, collection_name: str = "tfidf_search"):
"""Index data using TF-IDF vectors"""
texts = df['cleaned_text'].tolist()
print("Generating TF-IDF vectors...")
tfidf_matrix, tfidf_vectorizer = self.vector_gen.generate_tfidf_vectors(texts)
print("Indexing TF-IDF vectors...")
points = []
for idx, row in tqdm(df.iterrows(), total=len(df)):
sparse_vector = self.vector_gen.tfidf_to_sparse_vector(
tfidf_matrix[idx], tfidf_vectorizer
)
point = models.PointStruct(
id=idx,
payload={
"id": row.get('id', idx),
"title": row.get('title', ''),
"description": row.get('description', ''),
"attributes": row.get('attributes', ''),
"original_text": row['combined_text']
},
vector={"tfidf": sparse_vector}
)
points.append(point)
self.client.upsert(collection_name=collection_name, points=points)
print(f"Indexed {len(points)} documents with TF-IDF")
How to use the Indexed Data:
def search_tfidf(self, query: str, collection_name: str = "tfidf_search",
limit: int = 10) -> List[Dict[str, Any]]:
"""Search using TF-IDF vectors"""
# Generate TF-IDF vector for query
query_vector = self.vector_gen.tfidf_vectorizer.transform([query])
sparse_vector = self.vector_gen.tfidf_to_sparse_vector(
query_vector[0], self.vector_gen.tfidf_vectorizer
)
search_result = self.client.search(
collection_name=collection_name,
query_vector=models.NamedSparseVector(
name="tfidf",
vector=sparse_vector
),
limit=limit,
with_payload=True
)
return self._format_search_results(search_result)2. BM25: TF-IDF’s Probabilistic Evolution
Okapi BM25 (Best Matching 25) is a ranking function used by search engines to estimate the relevance of documents to a given search query. It builds upon the probabilistic retrieval framework developed in the 1970s and 1980s. BM25 and its variants are TF-IDF-like retrieval functions.
BM25 is a bag-of-words retrieval function that ranks documents based on query terms appearing in them, without considering term proximity. It relies solely on word frequency and does not attempt to comprehend the meaning or contextual importance of words. It also requires computing corpus statistics in advance, which can be challenging for large datasets.

How to index it:
def index_bm25_collection(self, df: pd.DataFrame, collection_name: str = "bm25_search"):
"""Index data using BM25 vectors"""
texts = df['cleaned_text'].tolist()
print("Generating BM25 representation...")
bm25_corpus, tokenized_texts = self.vector_gen.generate_bm25_vectors(texts)
# We need TF-IDF vectorizer for vocabulary mapping
_, tfidf_vectorizer = self.vector_gen.generate_tfidf_vectors(texts)
print("Indexing BM25 vectors...")
points = []
for idx, row in tqdm(df.iterrows(), total=len(df)):
# For BM25, we store the tokenized text and compute scores at query time
# For indexing, we'll create a simple frequency-based sparse vector
tokens = tokenized_texts[idx]
vocab_dict = tfidf_vectorizer.vocabulary_
indices = []
values = []
# Create frequency-based sparse vector
token_counts = {}
for token in tokens:
if token in vocab_dict:
token_counts[token] = token_counts.get(token, 0) + 1
for token, count in token_counts.items():
indices.append(vocab_dict[token])
values.append(float(count))
sparse_vector = models.SparseVector(indices=indices, values=values)
point = models.PointStruct(
id=idx,
payload={
"id": row.get('id', idx),
"title": row.get('title', ''),
"description": row.get('description', ''),
"attributes": row.get('attributes', ''),
"original_text": row['combined_text'],
"tokens": tokens # Store tokens for BM25 query processing
},
vector={"bm25": sparse_vector}
)
points.append(point)
self.client.upsert(collection_name=collection_name, points=points)
print(f"Indexed {len(points)} documents with BM25")
How to use the indexes:
def search_bm25(self, query: str, collection_name: str = "bm25_search",
limit: int = 10) -> List[Dict[str, Any]]:
"""Search using BM25 vectors"""
# Clean and tokenize query
cleaned_query = self.vector_gen.tfidf_vectorizer.build_preprocessor()(query)
query_tokens = cleaned_query.split()
# Get all documents to compute BM25 scores
# Note: This is a simplified approach. In production, you'd want to optimize this.
all_points = self.client.scroll(
collection_name=collection_name,
limit=1000, # Adjust based on your dataset size
with_payload=True,
with_vectors=False
)[0]
# Compute BM25 scores for each document
bm25_scores = []
for point in all_points:
doc_tokens = point.payload.get('tokens', [])
score = self.vector_gen.bm25_corpus.get_scores(query_tokens)[point.id]
bm25_scores.append((point.id, score))
# Sort by score and get top results
bm25_scores.sort(key=lambda x: x[1], reverse=True)
top_ids = [point_id for point_id, score in bm25_scores[:limit]]
# Get full documents for top results
results = []
for point_id in top_ids:
point = self.client.retrieve(
collection_name=collection_name,
ids=[point_id],
with_payload=True
)[0]
results.append({
'id': point.id,
'score': bm25_scores[top_ids.index(point_id)][1],
'payload': point.payload
})
return results3. Sparse Vector Search: Neural Keyword Matching
SPLADE (Sparse Lexical and Expansion Model) is an example of how sparse vectors are created. It leverages a transformer architecture (like BERT) to generate sparse representations. SPLADE learns to expand a query or document to include other contextually relevant terms that might not be explicitly mentioned in the original text. For instance, “solar energy advantages” might expand to include “renewable,” “sustainable,” and “photovoltaic”. This “term expansion” is a key advantage over other sparse methods that only include exact words.
Their primary applications include text search, hybrid search, RAG (Retrieval-Augmented Generation), and many general machine learning tasks. Qdrant supports a separate index for Sparse Vectors, allowing each “Point” to have both dense and sparse vectors.
How to index:
def index_splade_collection(self, df: pd.DataFrame, collection_name: str = "splade_search"):
"""Index data using SPLADE vectors"""
texts = df['cleaned_text'].tolist()
print("Generating SPLADE vectors...")
splade_vectors = self.vector_gen.generate_splade_vectors(texts)
print("Indexing SPLADE vectors...")
points = []
for idx, row in tqdm(df.iterrows(), total=len(df)):
point = models.PointStruct(
id=idx,
payload={
"id": row.get('id', idx),
"title": row.get('title', ''),
"description": row.get('description', ''),
"attributes": row.get('attributes', ''),
"original_text": row['combined_text']
},
vector={"splade": splade_vectors[idx]}
)
points.append(point)
self.client.upsert(collection_name=collection_name, points=points)
print(f"Indexed {len(points)} documents with SPLADE")
How to use:
def search_splade(self, query: str, collection_name: str = "splade_search",
limit: int = 10) -> List[Dict[str, Any]]:
"""Search using SPLADE vectors"""
# Generate SPLADE vector for query
query_embeddings = list(self.vector_gen.sparse_model.embed([query]))
query_sparse_vector = models.SparseVector(
indices=query_embeddings[0].indices.tolist(),
values=query_embeddings[0].values.tolist()
)
search_result = self.client.search(
collection_name=collection_name,
query_vector=models.NamedSparseVector(
name="splade",
vector=query_sparse_vector
),
limit=limit,
with_payload=True
)
return self._format_search_results(search_result)4. Hybrid Search: The Best of Both Worlds
Hybrid search aims to leverage the benefits of both approaches: sparse vectors ensure that all results with required keywords are returned, while dense vectors cover the semantically similar results. This combined approach can be presented directly to the user or used as the first stage of a two-stage retrieval process. To combine the results from dense and sparse vectors, various fusion functions are used, based on their relative scores. Popular methods include: Reciprocal Rank Fusion (RRF), Relative Score Fusion (RSF), and Distribution-Based Score Fusion (DBSF).
Hybrid search is crucial for many use cases, especially those involving Large Language Models (LLMs), where deep understanding of queries and accurate information retrieval are essential. It forms the foundation for many applications like chatbots, semantic search, and anomaly detection.
How to index:
def index_hybrid_collection(self, df: pd.DataFrame, collection_name: str = "hybrid_search"):
"""Index data using both dense and SPLADE vectors for hybrid search"""
texts = df['cleaned_text'].tolist()
print("Generating dense and SPLADE vectors...")
dense_vectors = self.vector_gen.generate_dense_vectors(texts)
splade_vectors = self.vector_gen.generate_splade_vectors(texts)
print("Indexing hybrid vectors...")
points = []
for idx, row in tqdm(df.iterrows(), total=len(df)):
point = models.PointStruct(
id=idx,
payload={
"id": row.get('id', idx),
"title": row.get('title', ''),
"description": row.get('description', ''),
"attributes": row.get('attributes', ''),
"original_text": row['combined_text']
},
vector={
"dense": dense_vectors[idx].tolist(),
"splade": splade_vectors[idx]
}
)
points.append(point)
self.client.upsert(collection_name=collection_name, points=points)
print(f"Indexed {len(points)} documents with hybrid vectors")
def index_all_collections(self, df: pd.DataFrame):
"""Index all collections and save models"""
self.index_tfidf_collection(df)
self.index_bm25_collection(df)
self.index_splade_collection(df)
self.index_dense_collection(df)
self.index_hybrid_collection(df)
# Save models after indexing
print("Saving models...")
self.vector_gen.save_models()
print("Models saved successfully")
How to use:
def search_hybrid(self, query: str, collection_name: str = "hybrid_search",
limit: int = 10) -> List[Dict[str, Any]]:
"""Search using hybrid approach (dense + SPLADE with manual fusion)"""
# Search with dense vectors
dense_results = self.client.search(
collection_name=collection_name,
query_vector=models.NamedVector(
name="dense",
vector=self.vector_gen.dense_model.encode([query])[0].tolist()
),
limit=limit * 2,
with_payload=True
)
# Search with SPLADE vectors
query_embeddings = list(self.vector_gen.sparse_model.embed([query]))
query_sparse_vector = models.SparseVector(
indices=query_embeddings[0].indices.tolist(),
values=query_embeddings[0].values.tolist()
)
sparse_results = self.client.search(
collection_name=collection_name,
query_vector=models.NamedSparseVector(
name="splade",
vector=query_sparse_vector
),
limit=limit * 2,
with_payload=True
)
# Manual fusion using Reciprocal Rank Fusion (RRF)
return self._reciprocal_rank_fusion(dense_results, sparse_results, limit)
Model Evaluation
TF-IDF
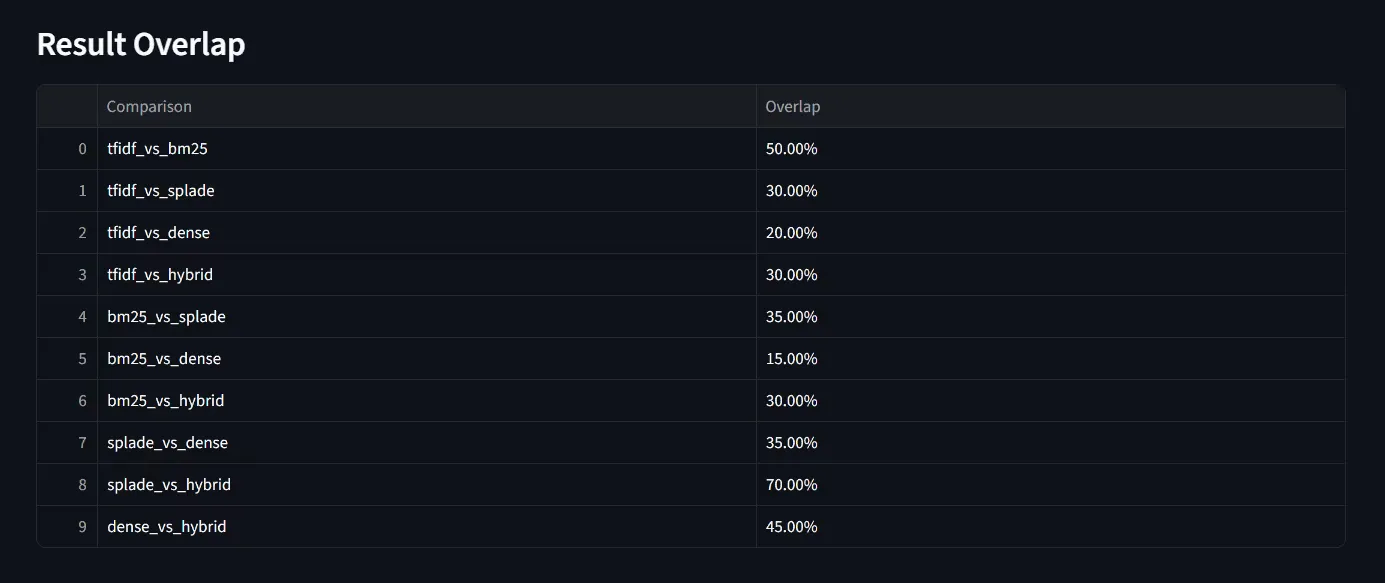
The evaluation shows clear differences in how each retrieval method handles the query “red men running shoes.” TF-IDF relies purely on keyword frequency and thus retrieves relevant shoes containing the exact terms, but it struggles with semantic nuance. While it returns several correct matches, it also introduces less relevant results where the category (e.g., outdoor vs. running) does not align perfectly. Its overlap with BM25 is about 50%, indicating partial consistency but weaker precision overall.

BM-25
BM25, on the other hand, improves upon TF-IDF by applying better term weighting and relevance scoring. This results in a stronger ranking of relevant red men’s running shoes and higher retrieval scores. It shows moderate overlap with SPLADE (35%) and Hybrid (30%), proving it captures keyword-focused matches well but lacks semantic depth.

SPLADE
SPLADE introduces sparse neural representations that go beyond surface-level terms, allowing it to capture intent more semantically. It identifies correct results like red men’s running shoes but sometimes admits mismatches (such as green or black shoes) due to broader semantic expansion. Interestingly, it aligns strongly with Hybrid (70% overlap), reflecting its semantic strength.

Hybrid
Finally, the Hybrid approach combines the advantages of lexical (BM25/TF-IDF) and neural (SPLADE) retrieval. It consistently retrieves highly relevant red men’s running shoes at the top ranks, balancing strict attribute matching with semantic generalization. With strong alignment to SPLADE and fair consistency with other models, Hybrid proves to be the most robust option for practical e-commerce search scenarios, where both keyword precision and semantic understanding are critical.
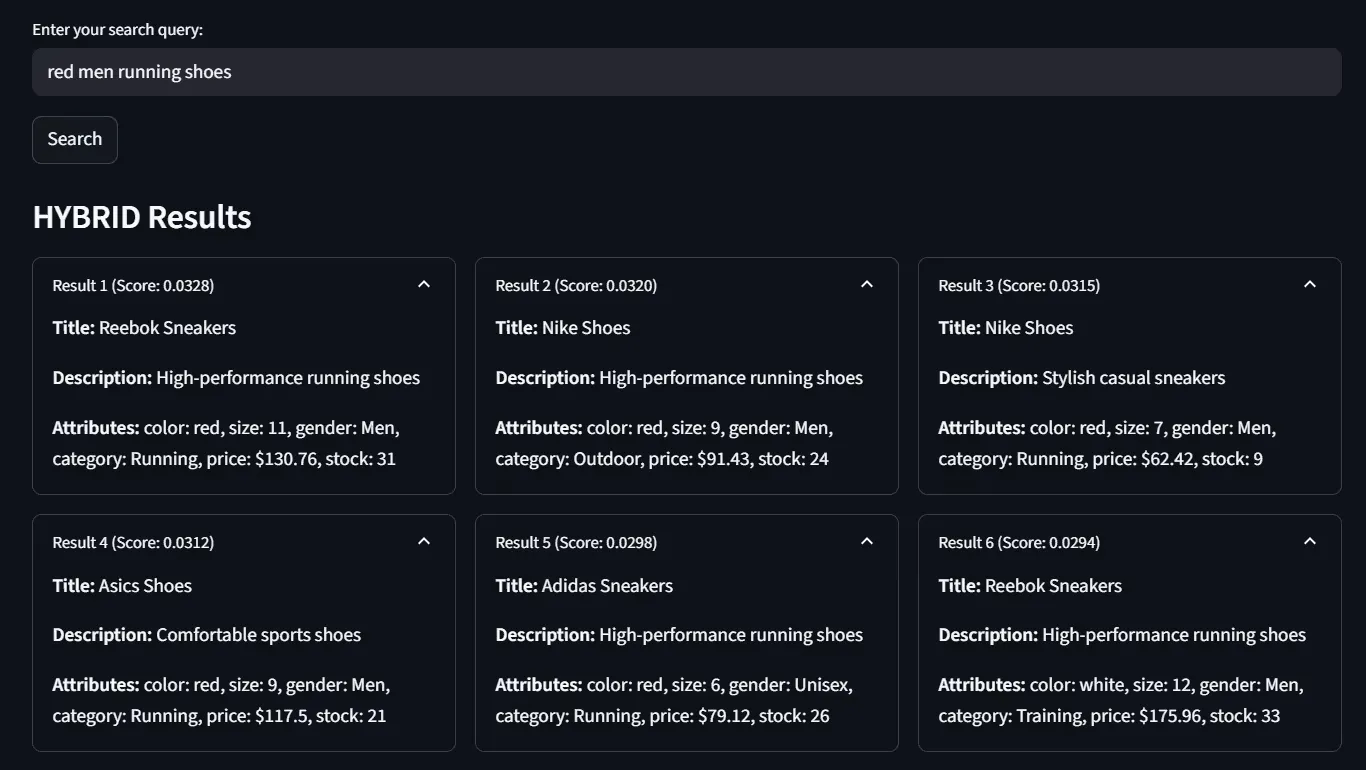
In summary, TF-IDF serves as a weak baseline, BM25 excels at lexical precision, SPLADE enhances semantic recall but risks off-target matches, while Hybrid achieves the best overall balance and is the most reliable choice.
Result overlap:
Choosing Your Search Strategy: Conclusion
Search is not a one-size-fits-all problem. Each method—TF-IDF, BM25, SPLADE, and Hybrid—brings a different strength to the table. TF-IDF remains a simple, interpretable baseline that works well when exact keyword matching is enough. BM25 improves lexical precision, especially when ranking relevance among closely related terms. SPLADE pushes retrieval into the semantic space, expanding queries to capture intent and related concepts, which is invaluable when users phrase things loosely or use synonyms. Hybrid search strikes the best balance, blending the rigor of keyword matching with the flexibility of semantic expansion, making it especially well-suited for dynamic domains like e-commerce, customer support, and RAG-based applications.
In practice, the right choice depends on your use case: if speed and simplicity matter, TF-IDF and BM25 will serve well; if semantic understanding is key, SPLADE or Hybrid search is the way forward. Qdrant makes this experimentation seamless by supporting dense and sparse vectors side by side—letting you test, tune, and deploy the method that truly fits your users’ needs.
To learn more, speak to us.
Full Code Implementation
Run the full code and test the difference yourself!
- Clone the code repo from Github or download it locally:
git clone https://github.com/harshchan/Qdrant-search-methods.git
- Create a new virtual environment and install all the required packages in it:
python -m venv .venv && pip install -r requirements.txt
- Run the docker image in port 6333 and 6334 after pulling the latest image using command:
docker pull qdrant/qdrant:latest && docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant:latest
- Run the main file python main.py — mode pipeline to set-up:
- To see the results in the frontend run python main.py — mode streamlit
- To see the evaluation results/ type your own query in the terminal run python main.py — mode search
References
-
Qdrant Documentation: https://qdrant.tech/documentation/
-
Qdrant GitHub Repository: https://github.com/qdrant/qdrant
-
Formal, T., Lassance, C., Piwowarski, B., & Clinchant, S. (2021). SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval. arXiv preprint.
-
Formal, T., Lassance, C., Déjean, H., & Clinchant, S. (2024). SPLADE-v3: New baselines for SPLADE. arXiv preprint. arXiv
-
Nguyen, T., MacAvaney, S., & Yates, A. (2023). A Unified Framework for Learned Sparse Retrieval. LSR comparative framework. irlab.science.uva.nl
-
Lassance, C., Lupart, S., Déjean, H., Clinchant, S., & Tonellotto, N. (2023). A Static Pruning Study on Sparse Neural Retrievers. arXiv preprint. arXiv
-
Robertson, S., & Zaragoza, H. (2009). The Probabilistic Relevance Framework: BM25 and Beyond. Foundations and Trends in Information Retrieval. Wikipedia
-
Łukawski, K. (2024). Hybrid Search Revamped – Building with Qdrant’s Query API. Qdrant article. Qdrant
-
Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Cambridge University Press.

-Feature-Image.CjBFdO7y_Z1JlSjK.webp)