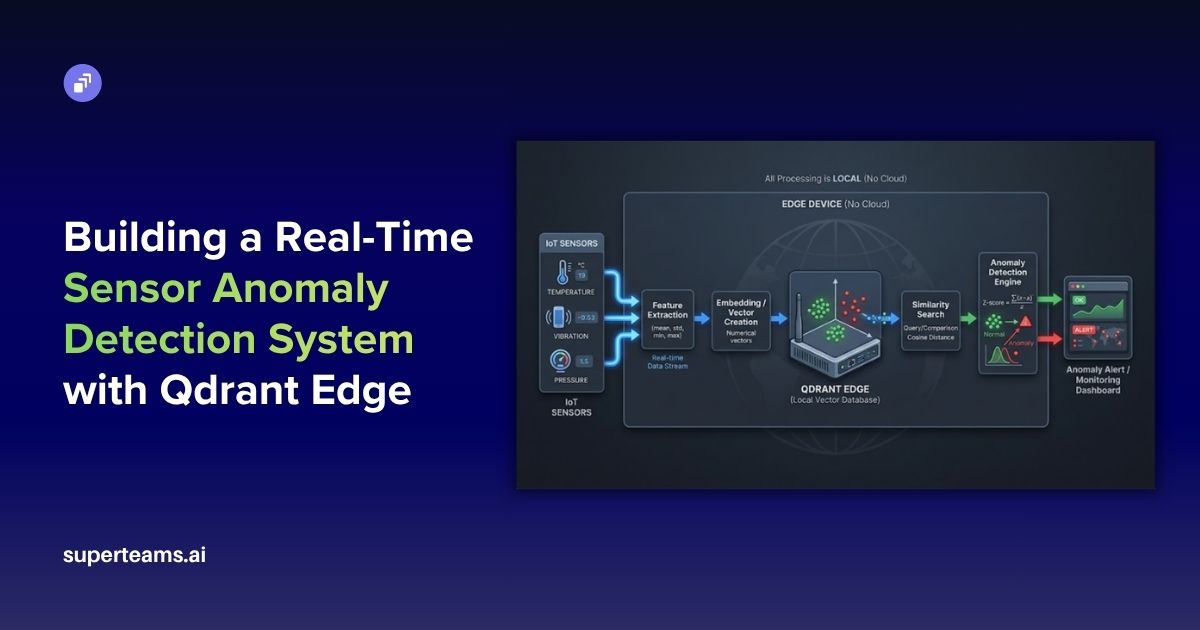
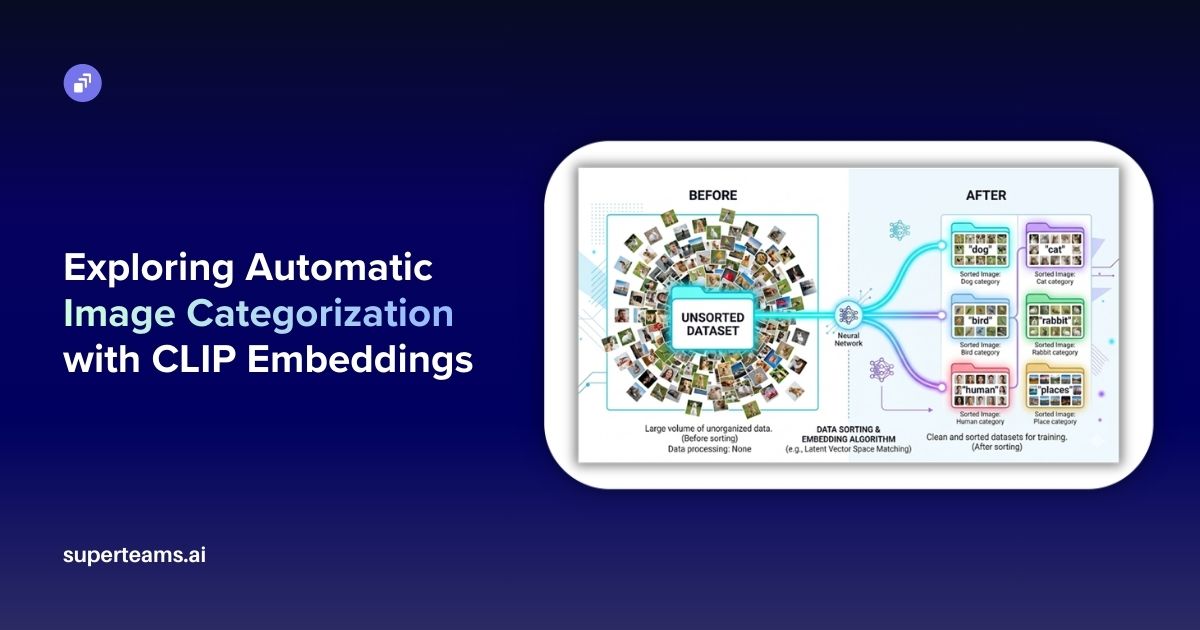
Large Language Model (LLM)
Browse Knowledge Base >A Large Language Model (LLM) is a type of artificial intelligence model designed to understand, generate, and manipulate human language at scale. It is built using deep learning techniques, specifically a variant of neural networks called transformers, which allow it to process and analyze vast amounts of text data. LLMs are trained on diverse datasets comprising billions of words from the internet, books, articles, and other text sources. During training, the model learns patterns, structures, and nuances of language, enabling it to perform tasks such as text generation, translation, summarization, and question answering with high accuracy. The "large" in its name refers to the massive size of the neural network, often containing hundreds of billions of parameters, which are the learnable weights of the model that are adjusted during the training process to minimize prediction errors.
Large Language Models (LLMs) are capable of performing a wide range of natural language processing tasks, including text generation, translation, summarization, question answering, sentiment analysis, and text classification. LLMs can generate text that is fluent, coherent, and contextually relevant, and they can understand the nuances of human language and respond to queries in a way that is appropriate and informative. LLMs can also be fine-tuned for specific use cases and applications, such as chatbots, content generation, and language understanding. However, LLMs have some limitations, including limited logical reasoning abilities, sensitivity to prompts, and limitations in incorporating real-time or dynamic information.
The development of Large Language Models (LLMs) has been a progressive journey over the last two decades, and driven by advancements in computational power, algorithmic techniques, and data availability.
- Early Days (Before 2010): Initial language models were relatively small and based on simpler statistical methods, such as n-gram models, which predict the next word in a sequence based on the previous (n-1) words. These models were limited by their inability to capture long-range dependencies and complex language structures.
- Rise of Neural Networks (2010-2017): The introduction of Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks marked a significant leap forward. These models could remember information for longer periods, enabling better handling of sequences and context in text. Word2Vec (2013) and GloVe (2014) introduced efficient ways to represent words as vectors, capturing semantic similarities between them.
- Attention Mechanisms and Transformers (2017-Present): The introduction of the Transformer architecture in 2017 with the paper "Attention is All You Need" by Vaswani et al. revolutionized LLMs. Transformers use self-attention mechanisms to weigh the importance of different words in a sentence, significantly improving the model's ability to handle long-range dependencies.
- GPT Series (OpenAI): Starting with GPT (Generative Pre-trained Transformer) in 2018, OpenAI introduced a series of increasingly larger and more powerful LLMs. GPT-2 (2019) demonstrated the potential of LLMs in generating coherent and diverse text, while GPT-3 (2020), with its 175 billion parameters, showcased remarkable abilities in natural language understanding and generation, setting a new standard for LLM capabilities.
- BERT and Its Variants (Google): BERT (Bidirectional Encoder Representations from Transformers) introduced in 2018, and its subsequent variants like RoBERTa, further advanced the field by focusing on bidirectional context, leading to significant improvements in tasks like question answering and language inference.
- Specialization and Efficiency (2020-Present): With the increasing size of LLMs, research has also focused on making these models more efficient and specialized. Techniques like pruning, quantization, and knowledge distillation have been explored to reduce model size without significantly compromising performance. Efforts towards creating domain-specific LLMs have increased, aiming to enhance performance in areas such as legal analysis, medical diagnosis, and scientific research.
- Ethical and Societal Considerations: As LLMs have grown in capability and influence, there has been a rising focus on addressing ethical considerations, such as bias, fairness, privacy, and the environmental impact of training large models. Initiatives like AI ethics guidelines and responsible AI practices have become integral to the development and deployment of LLMs.
Large Language Models can be classified as proprietary and open source. The proprietary ones, like GPT models, are owned and controlled by specific organizations or companies. Access to these models, whether for direct use or through APIs, is often restricted, requiring licenses, subscriptions, or specific agreements that usually involve costs or usage limits. The intellectual property rights of proprietary LLMs remain with the organization that developed them. Users of these models are typically limited in how they can use, modify, or redistribute the model or its derivatives. Updates and improvements to proprietary models are managed solely by the owning organization. Users have no influence over the development cycle or the priorities for model enhancements.
On the other hand, Open-source models are freely available for anyone to use, modify, and distribute. They are often hosted on platforms like GitHub, making it easy for developers, researchers, and enthusiasts to access and contribute to the model. Under open-source licenses, users can freely adapt and integrate the models into their own projects, even commercial ones, provided they adhere to the license terms. These terms might include requirements like attribution or the obligation to share derivative works under the same open license. The development of open-source models is typically community-driven, with contributions from a diverse range of developers and researchers. This approach encourages innovation, transparency, and rapid iteration.
Some of the more well known closed source LLMs are:
- GPT-4: An advanced iteration in the Generative Pre-trained Transformer series, released in March 2023. It is known for its vast capabilities in complex reasoning, advanced coding, and proficiency in multiple academic exams, exhibiting near-human-level performance.
- PaLM 2: The latest version of the Pathways Language Model, excelling in advanced reasoning tasks such as mathematics and coding. PaLM 2 builds on its predecessor with a 540 billion parameter transformer model, showcasing significant advancements in language understanding and generation.
- Claude: Anthropic, a company focused on creating AI systems with safety and ethical considerations, developed Claude as a conversational AI model. Although specific details and capabilities are not widely publicized, Claude is well known for its ethical design principles.
- Cohere's Language Models: Cohere is a company specializing in natural language processing technology, offering a suite of language models for various applications, including text generation, classification, and extraction. Cohere focuses on making AI accessible to businesses, providing APIs that enable easy integration of their models into applications. The details about the exact size and version of their latest models are proprietary, but Cohere is recognized for its emphasis on ease of use, scalability, and ethical AI.
Following are some of the more well-known Open Source LLMs:
- Vicuna-13B: Vicuna-13B is an open source language model developed by EleutherAI. It is based on the GPT-3 architecture and is trained on 13 billion parameters. Vicuna-13B is known for its strong performance in natural language generation tasks and has been used in various applications, including chatbots, content generation, and language understanding.
- GPT-J: GPT-J is an open source language model developed by EleutherAI. It is based on the GPT-3 architecture and is trained on 178 billion parameters. GPT-J is known for its ability to perform well on a wide range of natural language processing tasks, including text generation, translation, summarization, and more.
- LLaMA 2 Series: LLaMA 2 is an open source language model developed by the University of Washington and Allen Institute for AI. It is designed for multi-task learning and can be fine-tuned for specific natural language processing tasks. LLaMA 2 is known for its versatility and ability to handle various language understanding and generation tasks.
- BLOOM: BLOOM is an open source language model developed by Hugging Face. It is based on the GPT-3 architecture and is trained on a large number of parameters. BLOOM is known for its strong performance in text generation and has been used in applications such as chatbots, content creation, and language understanding.
- MPT-7B: MPT-7B is an open source language model developed by EleutherAI. It is based on the GPT-3 architecture and is trained on 7 billion parameters. MPT-7B is known for its ability to perform well on a variety of natural language processing tasks, including text generation, question answering, and more.
- Mistral Series: Mistral 7B is an open source language model developed by the University of Washington and Allen Institute for AI. It is based on the GPT-3 architecture and is trained on 7 billion parameters. Mistral 7B is known for its strong performance in natural language understanding and generation tasks, and it can be fine-tuned for specific applications and use cases.