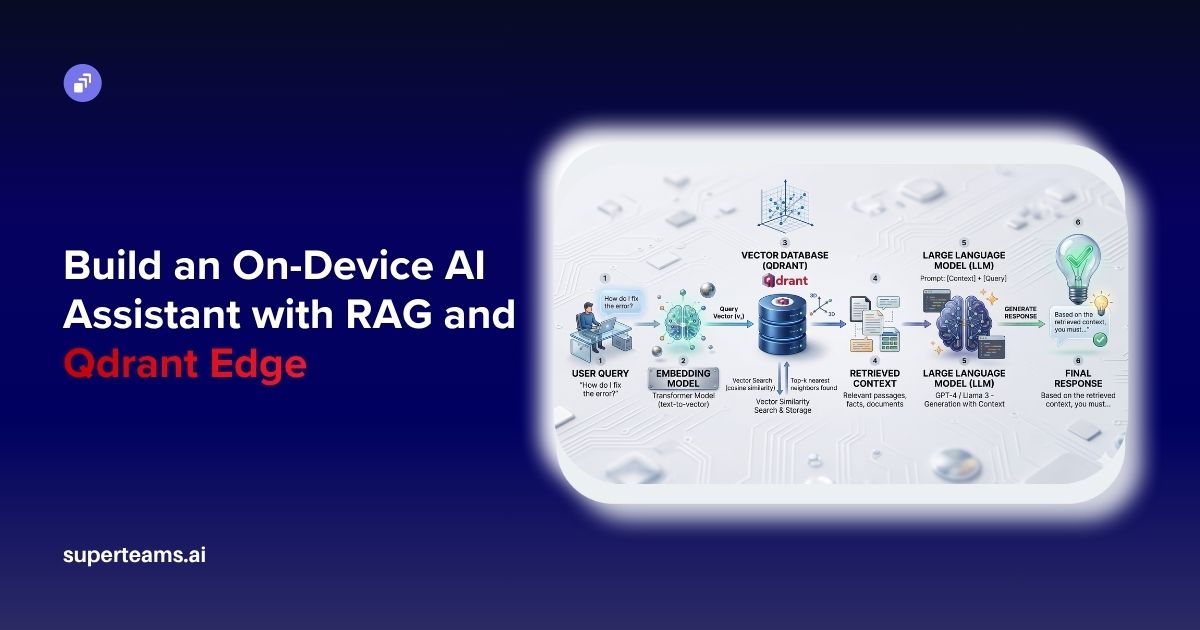
Using Yolo-World to Handle Zero-Shot Object Detection
Step-by-step guide showcasing how to build zero-shot object detection application with the help of Yolo-World

YOLO-World offers exciting possibilities for building applications that can detect objects in real time without prior training on specific categories. Here's an introduction to get you started:

YOLO-World prioritizes efficiency over other state-of-the-art models, achieving real-time performance through its convolutional neural network (CNN)-based YOLO architecture, while other models leverage the powerful but computationally expensive Transformer architecture.
Step-by-Step Process to Set Up Yolo-World
Setting Up YOLO-World for Zero-Shot Object Detection in Google Colab
This section details the process of setting up YOLO-World for object detection using Google Colab and the official YOLO-World GitHub repository.
Accessing the YOLO-World Repository:
- Visit the YOLO-World GitHub repository: https://github.com/AILab-CVC/YOLO-World
- Download the code or clone the repository using:
!git clone https://github.com/WongKinYiu/yolov7
Initializing Google Colab:
- Go to https://research.google.com/colaboratory/.
- Click on “File" → "New Notebook" to create a new notebook.
Implementation with Yolo-World
To make it easier for us to manage datasets, images, and models, we have created a HOME constant.
import os
HOME = os.getcwd()
print(HOME)Install Required Packages
We utilize two Python packages in this guide: inference, which handles the execution of zero-shot object detection using YOLO-World, and supervisions, which takes care of post-processing the results and visualizing the detected objects.
!pip install -q inference-gpu[yolo-world]==0.9.12rc1
!pip install -q supervision==0.19.0rc3
!pip install gradioImports
import cv2
import supervision as sv
from tqdm import tqdm
import gradio as gr
import torch
from inference.models.yolo_world.yolo_world import YOLOWorldDownload Sample Data
If you want to run using your file as input, simply upload the image to Google Colab and replace SOURCE_IMAGE_PATH with the path to your file.
!wget -P {HOME} -q https://media.roboflow.com/notebooks/examples/dog.jpeg
SOURCE_IMAGE_PATH = f"{HOME}/dog.jpeg"Run Object Detection
YOLO-World offers a range of pre-trained object detection models, giving you flexibility based on your project's requirements. The interface allows you to experiment with these models. Each comes in a different size: small (S), medium (M), and large (L). The small model (YOLO-World/S) is ideal for situations with limited computing power but might have slightly lower accuracy. The medium model (YOLO-World/M) strikes a balance between speed and precision. If your top priority is accuracy and you have the computational resources available, the large model (YOLO-World/L) is the way to go. Selecting your preferred model is easy – just use the model_id argument when running the code.
model = YOLOWorld(model_id="yolo_world/l")YOLO-World empowers you to detect objects without prior training. Simply define a prompt as a list of the classes (things) you're searching for.
classes = ["person", "backpack", "dog", "eye", "nose", "ear", "tongue"]
model.set_classes(classes)After performing detection on the sample image, convert the results into an sv.Detections object.
image = cv2.imread(SOURCE_IMAGE_PATH)
results = model.infer(image)
detections = sv.Detections.from_inference(results)The obtained results can be easily visualized using sv.BoundingBoxAnnotator and sv.LabelAnnotator. You can adjust parameters like line thickness, text scale, and color for lines and text, allowing for a highly customizable visualization experience.
BOUNDING_BOX_ANNOTATOR = sv.BoundingBoxAnnotator(thickness=2)
LABEL_ANNOTATOR = sv.LabelAnnotator(text_thickness=2, text_scale=1,text_color=sv.Color.BLACK)
annotated_image = image.copy()
annotated_image = BOUNDING_BOX_ANNOTATOR.annotate(annotated_image, detections)
annotated_image = LABEL_ANNOTATOR.annotate(annotated_image, detections)
sv.plot_image(annotated_image, (10, 10))
Lowering the Confidence Threshold for Enhanced Detection
The default confidence threshold in this model is set at 0.5. This means the model only detects objects it's fairly certain about (confidence score above 0.5). However, one might miss some valid detections, especially for less common objects.
To potentially detect a wider range of objects, one can experiment with lowering the confidence threshold. This increases the number of detections but also introduces a higher chance of including inaccurate results (false positives). Finding the optimal threshold depends on your specific needs. If it's crucial to avoid false positives, you should go for a higher threshold. If you're willing to accept some false positives to capture more objects of interest, a lower threshold might work.
image = cv2.imread(SOURCE_IMAGE_PATH)
results = model.infer(image, confidence=0.003)
detections = sv.Detections.from_inference(results)By default, sv.LabelAnnotator displays only the names of the objects. To also view the confidence levels associated with each detection, we must define custom labels and pass them to sv.LabelAnnotator.
labels = [
f"{classes[class_id]} {confidence:0.3f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
annotated_image = image.copy()
annotated_image = BOUNDING_BOX_ANNOTATOR.annotate(annotated_image, detections)
annotated_image = LABEL_ANNOTATOR.annotate(annotated_image, detections, labels=labels)
sv.plot_image(annotated_image, (10, 10))
Using Non-Max Suppression (NMS) to Eliminate Duplicate Detections
To eliminate duplicates, we will use Non-Max Suppression (NMS). NMS evaluates the extent to which detections overlap using the Intersection over Union metric and, upon exceeding a defined threshold, treats them as duplicates. Duplicates are then discarded, starting with those of the lowest confidence. The value should be within the range [0, 1]. The smaller the value, the more restrictive the NMS.
image = cv2.imread(SOURCE_IMAGE_PATH)
results = model.infer(image, confidence=0.003)
detections = sv.Detections.from_inference(results).with_nms(threshold=0.1)
labels = [
f"{classes[class_id]} {confidence:0.3f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
annotated_image = image.copy()
annotated_image = BOUNDING_BOX_ANNOTATOR.annotate(annotated_image, detections)
annotated_image = LABEL_ANNOTATOR.annotate(annotated_image, detections, labels=labels)
sv.plot_image(annotated_image, (10, 10))
This can also be done with videos, which we will demonstrate in the next blog post.
Using Gradio, we can visualize this model with a user interface (UI).
Setting Up Gradio
To complement the theoretical understanding of the code, now we will set up the interactive Gradio interface.

Interactive Visualization with Gradio
Gradio is a powerful library that can help create an interactive user interface (UI) specifically designed for visualizing the capabilities of the presented model. The UI allows users to directly interact with the model, allowing you to observe its output and gain valuable insights in an intuitive and user-friendly manner.
Defining a Function to Create the Model and Set Classes
def init_model():
model = YOLOWorld(model_id="yolo_world/l")
classes = ["person", "backpack", "dog", "eye", "nose", "ear", "tongue"]
model.set_classes(classes)
return modelEfficiency is important in the context of object detection using YOLO-World and Gradio. Here, we will discuss how to define a function to create the model and set its classes only once.
Function for Object Detection and Visualization
We dive into the core functionality of the code: the detect_objects function. It plays a crucial role in letting users interact with the model and visualize its output. Here, we'll examine the inner workings of this function, exploring how it achieves the following:
def detect_objects(image):
model = init_model() # Load the model if not already initialized
results = model.infer(image, confidence=0.003)
detections = sv.Detections.from_inference(results).with_nms(threshold=0.1)
labels = [
f"{classes[class_id]} {confidence:0.3f}"
for class_id, confidence in zip(detections.class_id, detections.confidence)
]
annotated_image = image.copy()
annotated_image = sv.BoundingBoxAnnotator(thickness=2).annotate(annotated_image, detections)
annotated_image = sv.LabelAnnotator(text_thickness=2, text_scale=1, text_color=sv.Color.BLACK).annotate(annotated_image, detections, labels=labels)
return annotated_image # Return the annotated image for Gradio outputCreating the Gradio Interface
This section focuses on the heart of user interaction - the Gradio interface. We'll explore:
interface = gr.Interface(
fn=detect_objects,
inputs="image",
outputs="image",
title="YOLO-World Zero-Shot Object Detection",
description="Upload an image and see detected objects with bounding boxes and labels.",
)
# Launch the Gradio interface
interface.launch(share=True)Running on a Public URL

The Final Application


Conclusion
This blog demonstrates the creation of an interactive interface using Gradio. Users can upload images, and the interface displays detected objects with bounding boxes and labels, providing visual insights into the model's predictions.
At Superteams.ai, we offer fully-managed fractional AI teams to solve business problems in a variety of domains. Leverage the power of AI today by reaching out to us at info@superteams.ai.
Authors

Want to Scale Your Business with AI Deployed on your Cloud?