Introduction
In recent years, the development of large language models has revolutionized natural language processing (NLP) applications. These models, trained on vast datasets like the Alpaca dataset, exhibit remarkable proficiency in various tasks, from text generation to comprehension. However, as the demand for more nuanced and specialized language understanding grows, it becomes evident that relying solely on generic datasets might not suffice.
Unlike conventional datasets, GPTeacher is designed with a focus on generating diverse and comprehensive prompts for training language models. By harnessing the collective intelligence of human teachers, GPTeacher ensures a rich and varied training corpus, essential for fine-tuning LLMs for specific use cases such as roleplay, code generation, and instruction.
In this blog, we will give you a walkthrough of how to use the GPTeacher dataset to finetune LLM models.
Let’s Start Coding
Let’s start by installing the required libraries.
pip install -q -U trl transformers accelerate
pip install -q datasets bitsandbytes einops wandb
pip install -q git+https://github.com/huggingface/peft.gitLet’s start by importing the dataset. We will be using the Teknium GPTeacher dataset for this blog. This dataset is available on Hugging Face (Link), and we use the load_dataset functionality directly for this.
from datasets import load_dataset
dataset_name = 'teknium/GPTeacher-General-Instruct'
dataset = load_dataset(dataset_name)Now, let’s write the function to combine the fields in the dataset into a single text field with the tags. This will be the required format to feed the prompts to Llama2.
# Function to combine the fields into a single text field with tags
def combine_fields_with_tags(example):
combined_text = f"[Instruction] {example['instruction']}
[Input] {example['input']}
[Response] {example['response']}"
return {'text': combined_text}
# Map the function to the dataset to create the new text field with tags
dataset = dataset.map(combine_fields_with_tags)Now let’s load the Llama 2 model. We will be using the shared version available on Hugging Face for this blog. We have used 4 bit quantization for reduced memory usage, faster inference speed, lower bandwidth requirements, improved scalability, and enhanced energy efficiency.
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
AutoTokenizer
)
model_name = "TinyPixel/Llama-2-7B-bf16-sharded"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
trust_remote_code=True
)
model.config.use_cache = FalseThen we load the tokenizer. We have used the Autotokenizer library here to load the tokenizer corresponding to the model name.
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_tokenWe will be utilizing PEFT (Parameter Efficient Fine-Tuning), specifically using a LoRA configuration for our fine-tuning process.
from peft import LoraConfig, get_peft_model
lora_alpha = 16
lora_dropout = 0.1
lora_r = 64
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM"
)Now let’s define the training parameters. Transformers provided a TrainingArguments functionality to define and set the training configurations.
from transformers import TrainingArguments
output_dir = "./results"
per_device_train_batch_size = 4
gradient_accumulation_steps = 4
optim = "paged_adamw_32bit"
save_steps = 100
logging_steps = 10
learning_rate = 2e-4
max_grad_norm = 0.3
max_steps = 100
warmup_ratio = 0.03
lr_scheduler_type = "constant"
training_arguments = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
fp16=True,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=True,
lr_scheduler_type=lr_scheduler_type,
)Then we simply pass everything to the trainer. We will also pre-process the model by upcasting the layer norms in float 32 for more stable training.
from trl import SFTTrainer
max_seq_length = 512
trainer = SFTTrainer(
model=model,
train_dataset=dataset['train'],
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
)
for name, module in trainer.model.named_modules():
if "norm" in name:
module = module.to(torch.float32)During training, the model should converge nicely as follows:
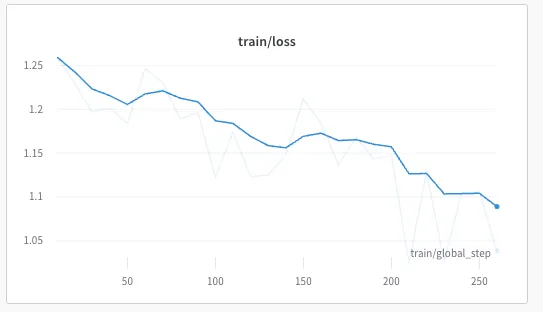
The `SFTTrainer` also takes care of properly saving only the adapters during training instead of saving the entire model.
model_to_save = trainer.model
# Take care of distributed/parallel training
if hasattr(trainer.model, 'module'):
model_to_save = trainer.model.module
model_to_save.save_pretrained("outputs")
lora_config = LoraConfig.from_pretrained('outputs')
model = get_peft_model(model, lora_config)Now, let’s proceed to test our model for inference.
text = "YOUR_TEXT"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Finally, we can push the trained model to Hugging face.
from huggingface_hub import login
login()
model.push_to_hub("llama2-q-lora-finetuned-french")-Feature-Image.CjBFdO7y_Z1JlSjK.webp)