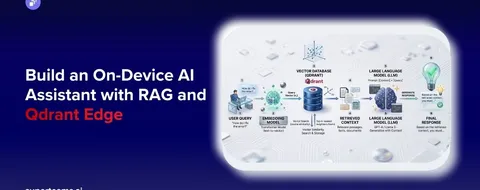
Do You Need a RAG Pipeline for Your Internal Company Docs?
A Retrieval Augmented Generation (RAG) pipeline can be a valuable tool for companies looking to improve access and utilization of their internal business documents. Many companies struggle with information silos, where valuable knowledge gets trapped within specific departments or documents. A RAG pipeline acts like a powerful search engine for internal documents. Employees can ask questions in natural language, and the RAG pipeline retrieves relevant passages from contracts, employee handbooks, or knowledge bases.
RAG pipelines can go beyond simple retrieval. They can also use the retrieved information to generate summaries or answer specific questions. This allows employees to grasp complex topics in internal documents more easily, leading to better-informed decisions.
New hires often spend significant time searching for company policies, procedures, or benefits information. A RAG pipeline can act as a virtual assistant for new employees, providing them with quick access to relevant information and streamlining the onboarding process.
Internal documents often contain valuable knowledge about products, services, or troubleshooting procedures. A RAG pipeline can be integrated with customer support systems, allowing agents to find answers to customer queries quickly and efficiently from internal resources.
Depending on the industry, companies might need to navigate complex legal and regulatory frameworks. RAG pipelines can be trained on industry-specific documents and regulations. Employees can then use the pipeline to get tailored summaries or insights relevant to their specific situation.
Now if you’re convinced you need a RAG pipeline, we’ll show you the steps for it.
How to Go about Building a RAG Pipeline?
Below are the steps involved in designing a RAG workflow:
1. Data Preparation: Split your documents into smaller chunks so that only relevant information is fed into the Large Language Model. This can be achieved easily by using one of many text splitting modules offered by popular frameworks like LangChain, LlamaIndex, etc.
2. Document Indexing: Now these chunks of data need to be converted into high-dimensional embeddings and then upserted into a vector database. There are many AI models that convert textual data into their semantic embeddings. Similarly, there are many open-source vector databases in the market. Some of the popular ones are FAISS, Pinecone, Weaviate and Qdrant.
3. Generation Model: Choose a pre-trained large language model for text-generation. Popular choices are Llama2, Mistral 7B.
4. Context Retrieval and Answer generation: The relevant context is retrieved from the vector database by performing a similarity search on the user input query. Then this context is fed to the LLM along with the user query for generating an answer.
5. Deployment: Deploy your RAG pipeline in a production environment, ensuring scalability, reliability, and efficiency.
Python Code for RAG with Mistral 7B, Weaviate, and Gradio UI
Below is an end-to-end production-ready code for a RAG pipeline that uses Mistral 7B as the large language model, and Weaviate as the vector database. The entire pipeline is wrapped around a Gradio UI for user interactivity.
First create a vector cluster on Weaviate and retain the url of your cluster. Then, in a file called app.py, paste the following code:
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
BitsAndBytesConfig,
pipeline
)
import torch
import os
from langchain.llms import HuggingFacePipeline
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Weaviate
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_core.prompts import ChatPromptTemplate, PromptTemplate, format_document
from langchain_core.runnables import RunnableLambda, RunnablePassthrough, RunnableParallel
from langchain_core.output_parsers import StrOutputParser
from langchain.memory import ConversationBufferMemory
from langchain_core.messages import AIMessage, HumanMessage, get_buffer_string
from operator import itemgetter
import gradio as gr
import weaviate
def load_llm():
#Loading the Mistral Model
model_name='mistralai/Mistral-7B-Instruct-v0.2'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
)
# Building a LLM text-generation pipeline
text_generation_pipeline = pipeline(
model=model,
tokenizer=tokenizer,
task="text-generation",
temperature=0.2,
repetition_penalty=1.1,
return_full_text=True,
max_new_tokens=1024,
device_map = 'auto',
)
return text_generation_pipeline
def embeddings_model():
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2"
)
return embeddings
def initialize_vectorstore():
vectorstore = Weaviate.from_documents( [], embedding=hf_embeddings,
weaviate_url = 'https://superteams-810p8edk.weaviate.network',by_text= False
)
return vectorstore
def text_splitter():
# Simulate some document processing delay
text_splitter = RecursiveCharacterTextSplitter( chunk_size=512,
chunk_overlap=20,
length_function=len,
is_separator_regex=False,
)
return text_splitter
def add_pdfs_to_vectorstore(files):
saved_files_count = 0
for file_path in files:
file_name = os.path.basename(file_path) # Extract the filename from the full path
if file_name.lower().endswith('.pdf'): # Check if the file is a PDF
saved_files_count += 1
loader_temp = PyPDFLoader(file_path)
docs_temp = loader_temp.load_and_split(text_splitter=textsplitter)
for doc in docs_temp:
# Replace all occurrences of '\n' with a space ' '
doc.page_content = doc.page_content.replace('\n', ' ')
vectorstore.add_documents(docs_temp)
else:
print(f"Skipping non-PDF file: {file_name}")
return f"Added {saved_files_count} PDF file(s) to vectorstore/"
def weaviate_client():
client = weaviate.Client(url= 'https://superteams-810p8edk.weaviate.network')
return client
def answer_query(message, chat_history):
context_docs = vectorstore.similarity_search(message, k= 3)
context = ' '.join(doc.page_content for doc in context_docs)
template = f"""Answer the question based only on the following context:
{context}
Question: {message}
"""
result = llm(template)
answer = result[0]["generated_text"].replace(template, '')
chat_history.append((message, answer))
return "", chat_history
def clear_vectordb(chatbot, msg):
client.schema.delete_all()
chatbot = ""
msg = ""
return chatbot, msg
llm = load_llm()
hf_embeddings = embeddings_model()
client = weaviate_client()
vectorstore = initialize_vectorstore()
textsplitter = text_splitter()
with gr.Blocks() as demo:
with gr.Row():
upload_files = gr.File(label="Upload pdf files only", file_count='multiple')
success_msg = gr.Text(value="")
chatbot = gr.Chatbot()
msg = gr.Textbox(label="Enter your query here")
clear = gr.Button("Clear VectorDB and Chat")
upload_files.upload(add_pdfs_to_vectorstore, upload_files, success_msg)
msg.submit(answer_query, [msg, chatbot], [msg, chatbot])
clear.click(clear_vectordb, [chatbot, msg], [chatbot, msg])
demo.launch(server_name='0.0.0.0', share= True)Here’s a step-by-step description of the code:
1. The code imports necessary libraries and modules, including transformers for loading the language model, LangChain for document processing and vector store, and Gradio for building the user interface.
2. The `load_llm()` function is defined to load the Mistral 7B language model using the AutoTokenizer and AutoModelForCausalLM classes from the Transformers library. It sets up the tokenizer and model with specific configurations and returns a text generation pipeline.
3. The `embeddings_model()` function is defined to load the sentence-transformers/all-mpnet-base-v2 embeddings model using the HuggingFaceEmbeddings class from LangChain.
4. The `initialize_vectorstore()` function is defined to initialize an empty Weaviate vector store using the provided Weaviate URL and the loaded embeddings model.
5. The `text_splitter()` function is defined to create a RecursiveCharacterTextSplitter object for splitting text into chunks of a specified size and overlap.
6. The `add_pdfs_to_vectorstore()` function is defined to process uploaded PDF files. It iterates over each file, extracts the filename, and checks if it is a PDF. If it is a PDF, it loads the file using PyPDFLoader, splits the text into chunks using the text splitter, and adds the chunks to the vectorstore. It returns a success message with the count of added PDF files.
7. The `weaviate_client()` function is defined to create a Weaviate client using the provided URL.
8. The `answer_query()` function is defined to handle user queries. It takes the user’s message and the chat history as input. It performs a similarity search on the vector store to find the most relevant context documents based on the query. It then constructs a prompt template with the context and the question, passes it to the language model for generating an answer, and appends the question-answer pair to the chat history. It returns the updated chat history.
9. The `clear_vectordb()` function is defined to clear the vector store and chat history when the “Clear VectorDB and Chat” button is clicked.
10. The code initializes the language model, embeddings model, Weaviate client, vector store, and text splitter using the respective functions.
11. The code sets up the Gradio user interface using the `gr.Blocks()` context manager. It defines the layout and components of the interface, including:
- A file upload component for uploading PDF files.
- A success message text component to display the count of added PDF files.
- A chatbot component to display the conversation history.
- A textbox component for entering user queries.
- A button component to clear the vector store and chat history.
12. The code sets up event handlers for the interface components:
- When files are uploaded, the `add_pdfs_to_vectorstore()` function is called to process and add the PDF files to the vector store.
- When the user submits a query, the `answer_query()` function is called to generate an answer and update the chat history.
- When the “Clear VectorDB and Chat” button is clicked, the `clear_vectordb()` function is called to clear the vector store and chat history.
13. Finally, the code launches the Gradio interface, making it accessible via a web browser. It specifies the server name as ‘0.0.0.0’ and enables sharing of the interface.
Overall, this code sets up a conversational AI system that allows users to upload PDF files, stores the text content in a Weaviate vector store, and enables users to ask questions based on the uploaded documents.
Example Use-Case: Querying on the Leave Policy Document of a Company
I used AI Claude to generate a standard document of a company’s leave policy. It looks something like this:
Then I saved this in PDF format.
By running the following command in the terminal, I launched my RAG application.
gradio app.py I then uploaded the pdf file onto my chatbot
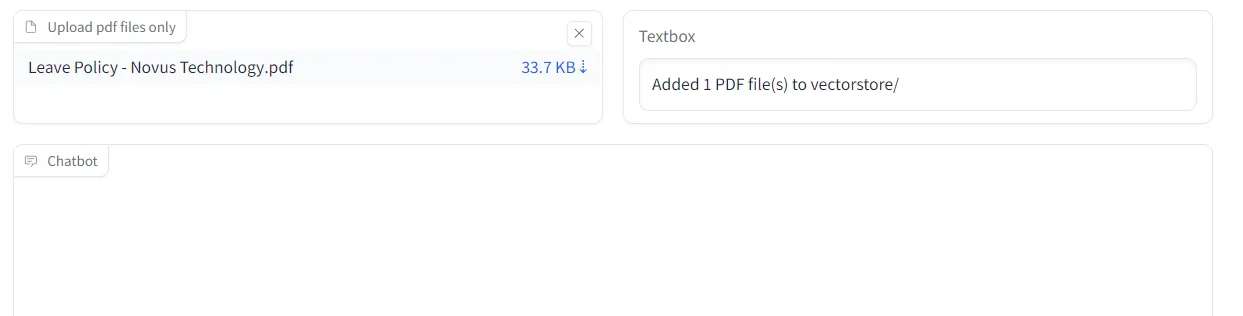
After that, I could query the chatbot and receive my answers as desired.
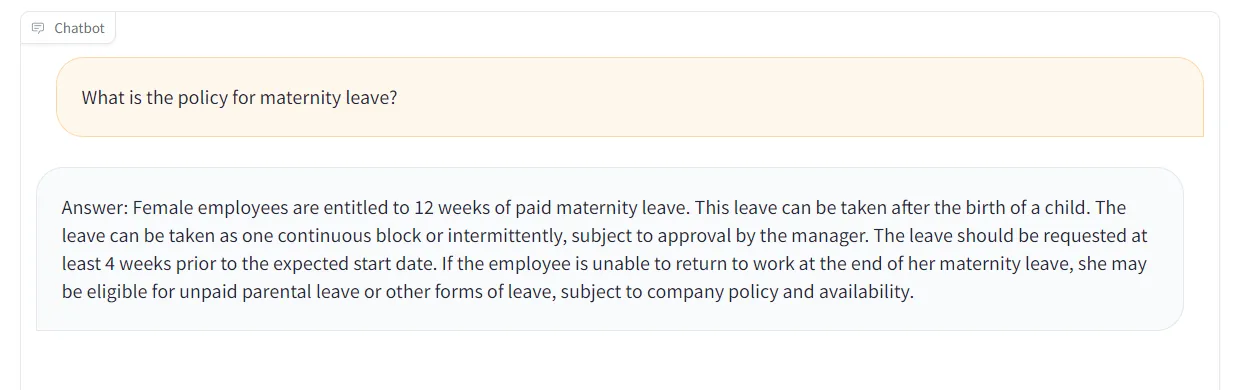
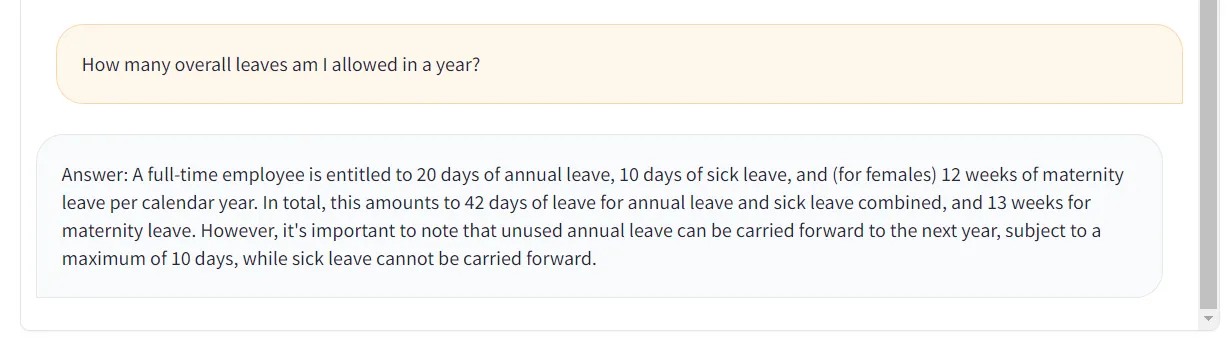
I also implemented a button to clear the chat, and the associated information in the vector DB, in case the user wants to upload fresh new information.

GitHub
The code for the article is publicly available here: https://github.com/vardhanam/RAG_Mistral_Weaviate_Gradio
About Superteams.ai
Superteams.ai connects top AI talent with companies seeking accelerated product and content development. Superteamers offer individual or team-based solutions for projects involving cutting-edge technologies like fine-tuning combined with RAG pipelines, text-to-image synthesis, object detection and more. To explore partnership opportunities, please write to [email protected] or visit this link.
-Feature-Image.CjBFdO7y_Z1JlSjK.webp)