Introduction
A Knowledge Graph is a method to represent data in a structured way in the form of graphs, where entities, concepts, and their relationships are represented as nodes and edges.
- Node: It represents specific entities or objects in the real world, such as people, organizations, cities, locations, etc.
- Edge: It represents the relationship, directionality, and weight between two nodes.
Knowledge Graphs provide a structured representation of knowledge, allowing language models to better understand the context and relationships between entities and concepts mentioned in the text. Knowledge Graphs are like organized maps of information. They help computers understand connections between different things, like people, places, and ideas. By using these graphs, computers can better understand what’s being talked about and how things relate to each other. This helps them give more accurate answers and make sense of complex topics. For example, if you ask a computer a question, it can look at the Knowledge Graph to find the right information and give you a helpful answer. Overall, Knowledge Graphs are a powerful tool for computers to understand and explain things in a way that makes sense to us.
I have used an AI model called the Rebel Model to convert unstructured data into a Knowledge Graph.
In this tutorial, we are going to generate Cypher queries from any PDF URL, or you can also upload a PDF from your own device to generate a Cypher query.
To build an API that can take a PDF URL or a PDF as input and return a Cypher query, we have used Flask.
A Cypher query is a query written in the Cypher language that can generate a Knowledge Graph. To execute a Cypher query, you need to use Neo4j Aura (a cloud service) or the Neo4j Desktop application.
Rebel Model
REBEL is a text-to-text model developed by Babelscape through the fine-tuning of the BART model. It is designed to parse sentences containing entities and implicit relationships, converting them into explicit relational triplets. Trained on over 200 distinct types of relations, REBEL’s training utilized a bespoke dataset drawn from Wikipedia abstracts and Wikidata’s relational data. This dataset was refined with the assistance of a RoBERTa-based Natural Language Inference model, ensuring the quality and relevance of the included entities and relations.
The dataset used for REBEL’s pre-training is accessible on the Hugging Face Hub, as detailed in the paper outlining its development process. REBEL has demonstrated impressive performance across several benchmarks in both Relation Extraction and Relation Classification tasks.
Flask API
Flask is a Python web framework that allows you to build web applications easily. To learn the basics, one can follow the Flask tutorial. Flask supports many HTTP methods; in this context, we are using the GET and POST methods.
To see your API working, you need to download Postman.
Flask API to Upload PDF File
Below is the code for a Flask API to upload files.
import os
from flask import Flask, flash, request, redirect, url_for, send_from_directory
from werkzeug.utils import secure_filename
# Define the folder to which files will be uploaded
UPLOAD_FOLDER = '/Users/kundankumar/Documents/code'
# Define the set of allowed file extensions
ALLOWED_EXTENSIONS = {'txt', 'pdf', 'png', 'jpg', 'jpeg', 'gif'}
# Initialize the Flask application
app = Flask(__name__)
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
def allowed_file(filename):
# Check if the filename has one of the allowed extensions.
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
@app.route('/', methods=['GET', 'POST'])
def upload_file():
"""
Handle file upload via POST request.
If the request method is GET, it returns the upload form.
"""
if request.method == 'POST':
# Check if the post request has the file part
if 'file' not in request.files:
flash('No file part')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('No selected file')
return redirect(request.url)
# Check if the file is allowed and save it securely
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))
return redirect(url_for('download_file', name=filename))
return '''
<!doctype html>
<title>Upload new File</title>
<h1>Upload new File</h1>
<form method=post enctype=multipart/form-data>
<input type=file name=file>
<input type=submit value=Upload>
</form>
'''
@app.route('/uploads/<name>')
def download_file(name):
return send_from_directory(app.config["UPLOAD_FOLDER"], name)
# Add URL rule to download the file
app.add_url_rule(
"/uploads/<name>", endpoint="download_file", build_only=True
)
if __name__ == '__main__':
# Run the Flask app in debug mode
app.run(debug=True)
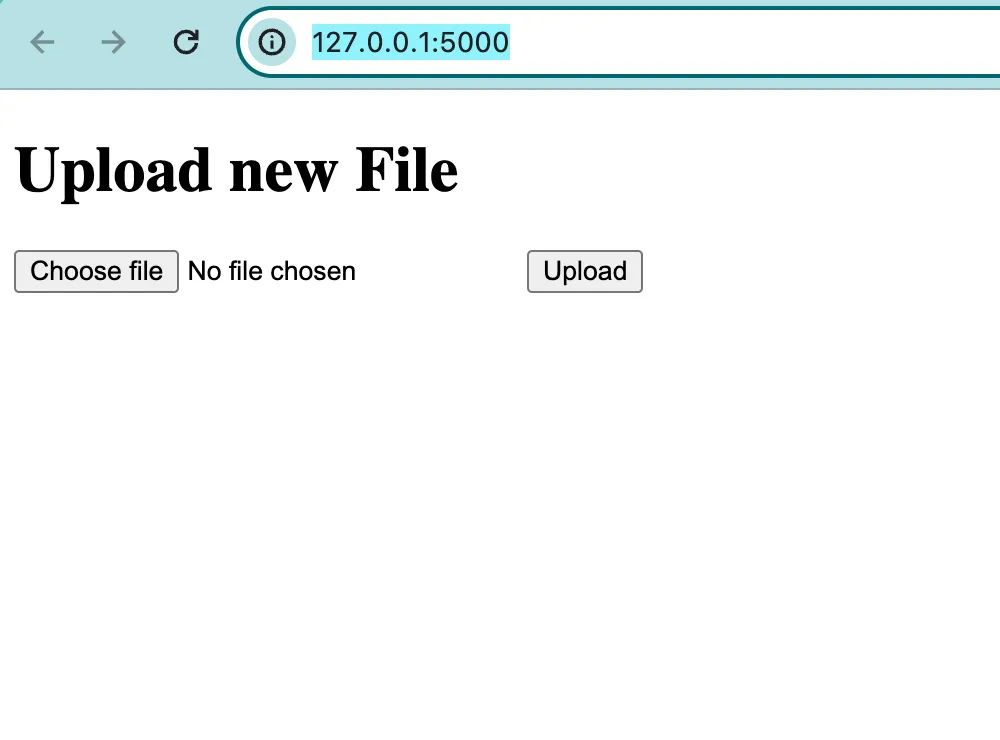
After running the above code you get the URL http://127.0.0.1:5000/; when you search this URL in your web browser, you get a web page where you can upload the PDF.
Now we create a Flask API to upload the PDF URL and get text back. For this, we use the POST HTTP method. To see how your URL is working, you need to download the Postman application. Below is the code:
from flask import Flask, request, jsonify
import urllib.request
from PyPDF2 import PdfReader
# Initialize the Flask application
app = Flask(__name__)
# Function to extract text from a PDF file given its URL
def extract_text_from_pdf(pdf_url):
text = ""
try:
# Download the PDF file from the given URL
with urllib.request.urlopen(pdf_url) as response:
with open("temp.pdf", "wb") as pdf_file:
pdf_file.write(response.read())
# Open the downloaded PDF file
with open("temp.pdf", "rb") as pdf_file:
pdf_reader = PdfReader(pdf_file)
# Extract text from each page of the PDF
for page_num in range(len(pdf_reader.pages)):
text += pdf_reader.pages[page_num].extract_text()
except Exception as e:
# Handle any exceptions that occur during the PDF processing
raise RuntimeError(f"Failed to extract text from PDF: {e}")
return text
# Define a route to handle text extraction requests
@app.route('/extract-text', methods=['POST'])
def extract_text():
# Get the JSON payload from the request
data = request.get_json()
# Check if the 'url' key is present in the JSON payload
if 'url' not in data:
return jsonify({'error': 'URL not provided in payload'}), 400
pdf_url = data['url']
try:
# Extract text from the PDF at the given URL
extracted_text = extract_text_from_pdf(pdf_url)
return jsonify({'text': extracted_text}), 200
except Exception as e:
# Return an error response if something goes wrong
return jsonify({'error': str(e)}), 500
# Run the Flask application
if __name__ == '__main__':
app.run(debug=True)When we run this code we will get the URL http://127.0.0.1:5000/extract-text. If you try to access this URL in your web browser, you will encounter an error.
Follow these steps:
- Open the Postman application.
- On the top left, set the HTTP method option to POST.
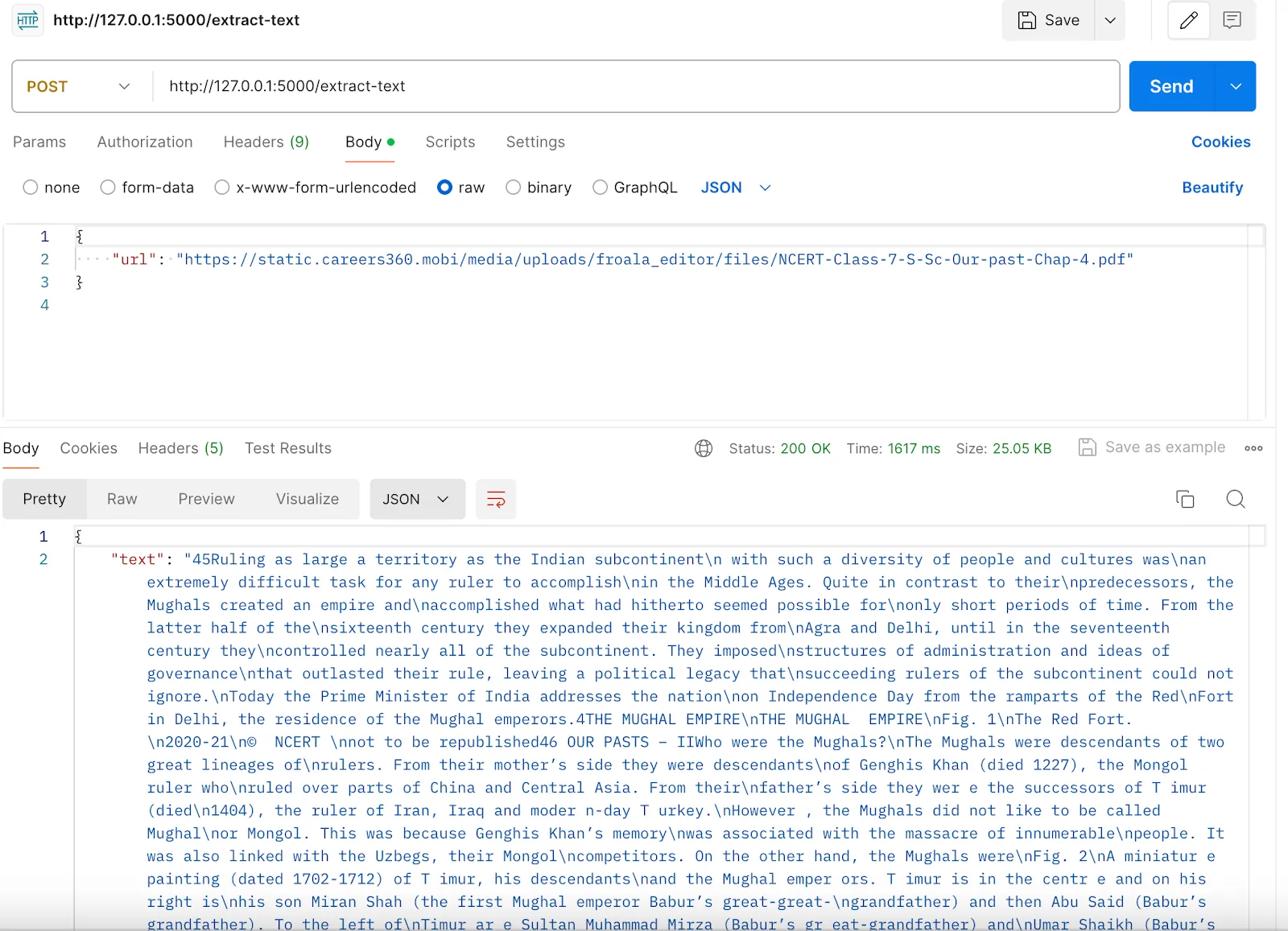
3. Select “raw” and then choose the “JSON” option from the dropdown.
4. Provide the URL in JSON format and hit the “Send” button.
After this, we are all set to create Cypher queries that generate a Knowledge Graph.
Loading all the libraries:
from flask import Flask, flash, request, redirect, jsonify
from werkzeug.utils import secure_filename
from KnowledgeGraphExtractor import KnowledgeGraphExtractor, KB
import os
Now in the Upload folder, provide the address of your folder.
# Configuration
UPLOAD_FOLDER = '/path/to/the/uploads'
ALLOWED_EXTENSIONS = {'txt', 'pdf'} # Define the allowed file extensions
# Create a new Flask application instance
app = Flask(__name__)
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
# Instantiate the knowledge graph extractor
kg_extractor = KnowledgeGraphExtractor()
#flask API that will take pdf URL as input in Jason format and return all the cypher queries
@app.route('/extract-and-create-kb', methods=['POST'])
def extract_and_create_kb():
data = request.get_json() # Get JSON data from the request body
# Check if the URL is provided in the request payload
if 'url' not in data:
return jsonify({'error': 'URL not provided in payload'}), 400
pdf_url = data['url'] # Extract the URL from the request data
try:
extracted_text = kg_extractor.extract_text_from_url(pdf_url)
# Split the extracted text into smaller chunks
chunks = kg_extractor.text_splitter.split_text(extracted_text)
cypher_queries = [] # Initialize a list to store Cypher queries
for chunk in chunks:
kb = kg_extractor.from_small_text_to_kb(chunk)
for relation in kb.relations:
head = relation['head'] # Extract the head of the relation
relationship = relation['type']
tail = relation['tail'] # Extract the tail of the relation
cypher = (
f"MERGE (h:`{head}`)"
+ f" MERGE (t:`{tail}`)"
+ f" MERGE (h)-[:`{relationship}`]->(t)"
)
cypher_queries.append(cypher)
return jsonify({'cypher_queries': cypher_queries}), 200
except Exception as e:
return jsonify({'error': str(e)}), 500
# Flask route to upload a file and get Cypher queries back
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
# Check if the post request has the file parted file extensions
if 'file' not in request.files:
flash('No file part')
return redirect(request.url)
file = request.files['file']
# Check if the filename is empty
if file.filename == '':
flash('No selected file')
return redirect(request.url)
# Check if the file has an allowed extension
if file and kg_extractor.allowed_file(file.filename):
filename = secure_filename(file.filename)
file_path = os.path.join(app.config['UPLOAD_FOLDER'], filename)
file.save(file_path)
try:
if filename.rsplit('.', 1)[1].lower() == 'pdf':
extracted_text = kg_extractor.extract_text_from_pdf(file_path)
elif filename.rsplit('.', 1)[1].lower() == 'txt':
extracted_text = kg_extractor.extract_text_from_txt(file_path)
else:
return jsonify({'error': 'Unsupported file type'}), 400
# Split the extracted text into chunks
chunks = kg_extractor.text_splitter.split_text(extracted_text)
cypher_queries = []
for chunk in chunks:
kb = kg_extractor.from_small_text_to_kb(chunk)
for relation in kb.relations:
head = relation['head']
relationship = relation['type']
tail = relation['tail']
# Create a Cypher query
cypher = (
f"MERGE (h:`{head}`)"
+ f" MERGE (t:`{tail}`)"
+ f" MERGE (h)-[:`{relationship}`]->(t)"
)
cypher_queries.append(cypher)
return jsonify({'cypher_queries': cypher_queries}), 200
except Exception as e:
return jsonify({'error': str(e)}), 500
return '''
<!doctype html>
<title>Upload new File</title>
<h1>Upload new File</h1>
<form method=post enctype=multipart/form-data>
<input type=file name=file>
<input type=submit value=Upload>
</form>
'''
if __name__ == '__main__':
app.run(debug=True) # Run the Flask application in debug modeTo check, upload the URL to get Cypher queries; you will need to use Postman again. Pass the PDF URL in JSON format to receive the Cypher queries.
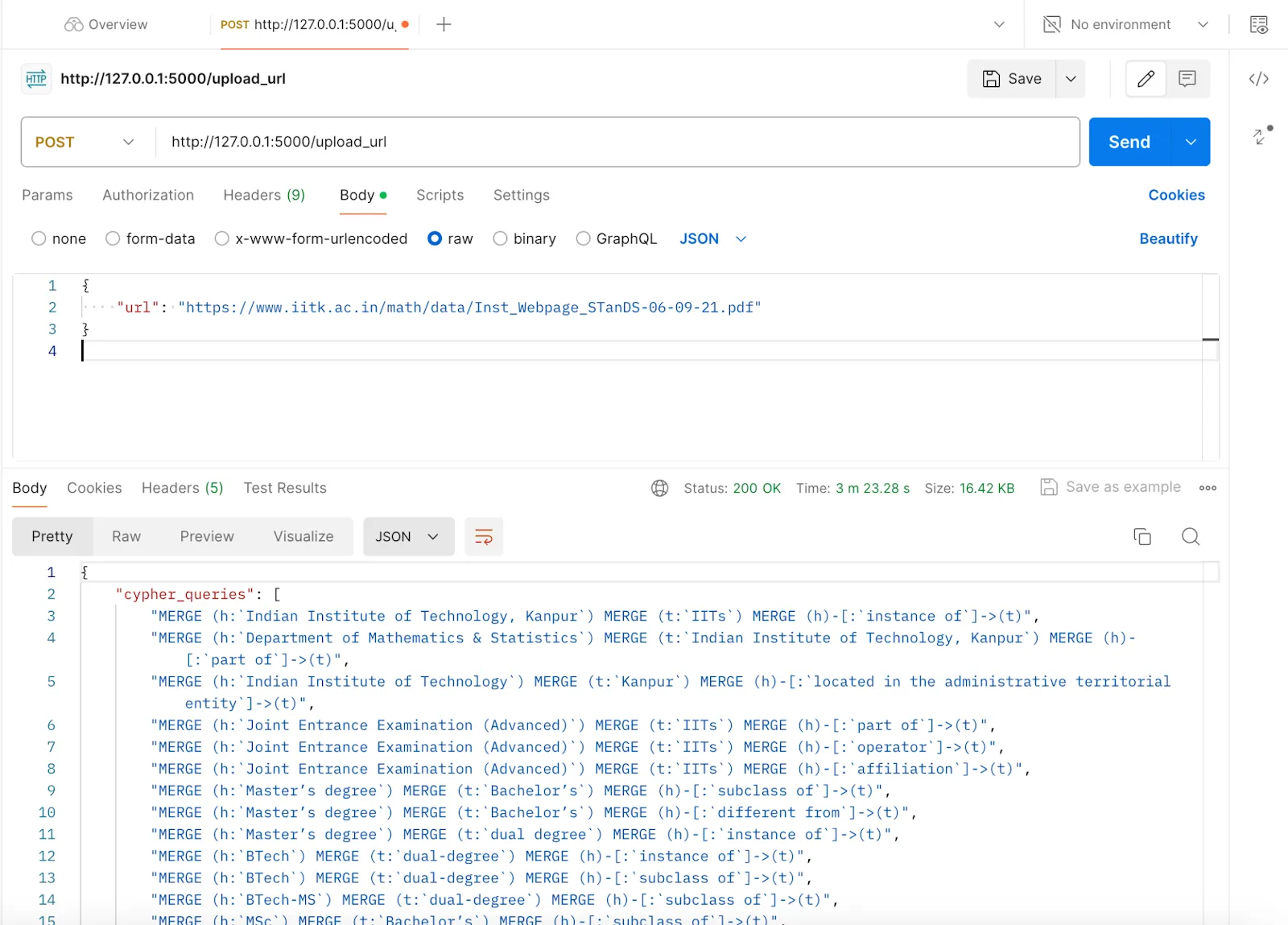
To check, upload the file to get Cypher queries. Again, you need to go to your web browser and visit the URL http://127.0.0.1:5000/upload_file. Choose the file and upload it. Then you will receive the Cypher queries.
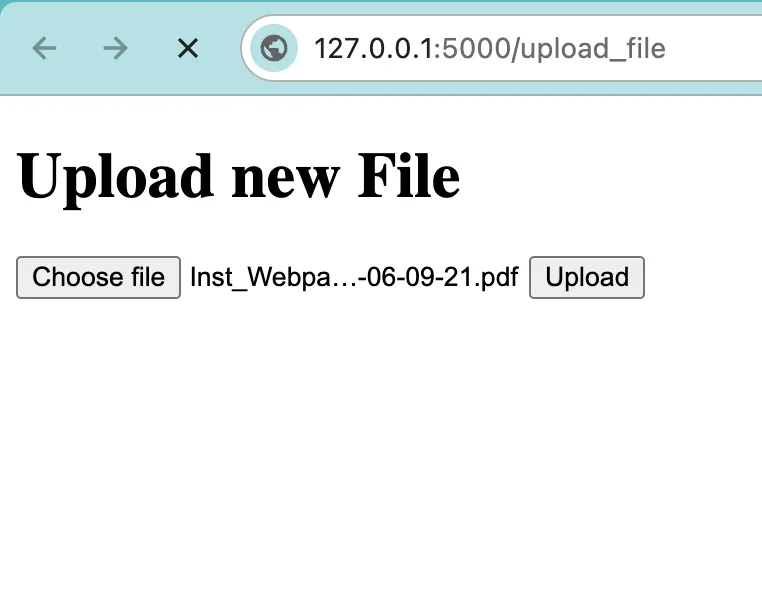
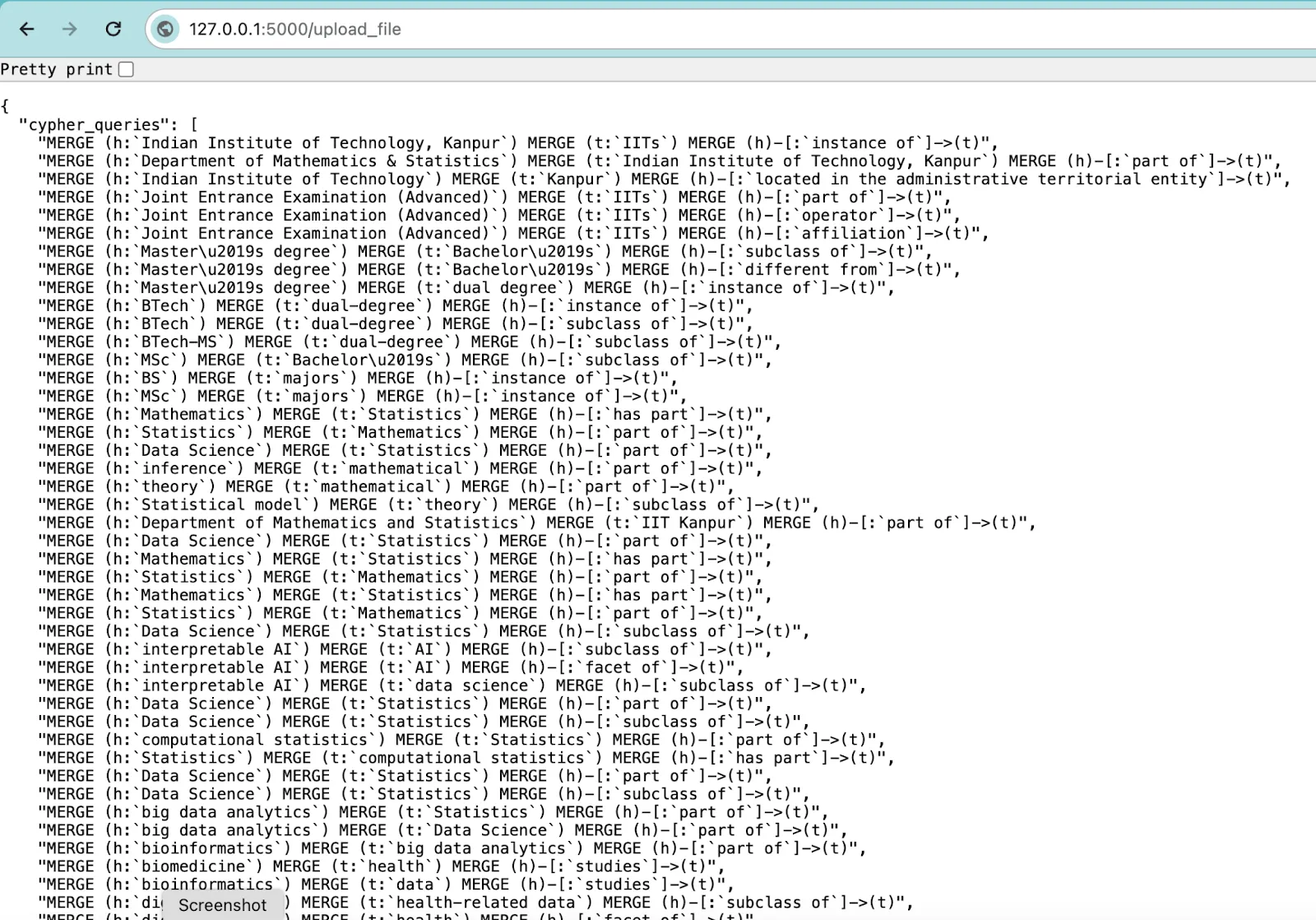
After you get all the Cypher queries, you can run them on the Neo4j Aura console or the Neo4j Desktop. Once you have run all the Cypher queries, then execute the following command:
MATCH (n)
RETURN nYou will now get to see your Knowledge Graph.
The circles represent the nodes and the arrows between them represent the relation between them.
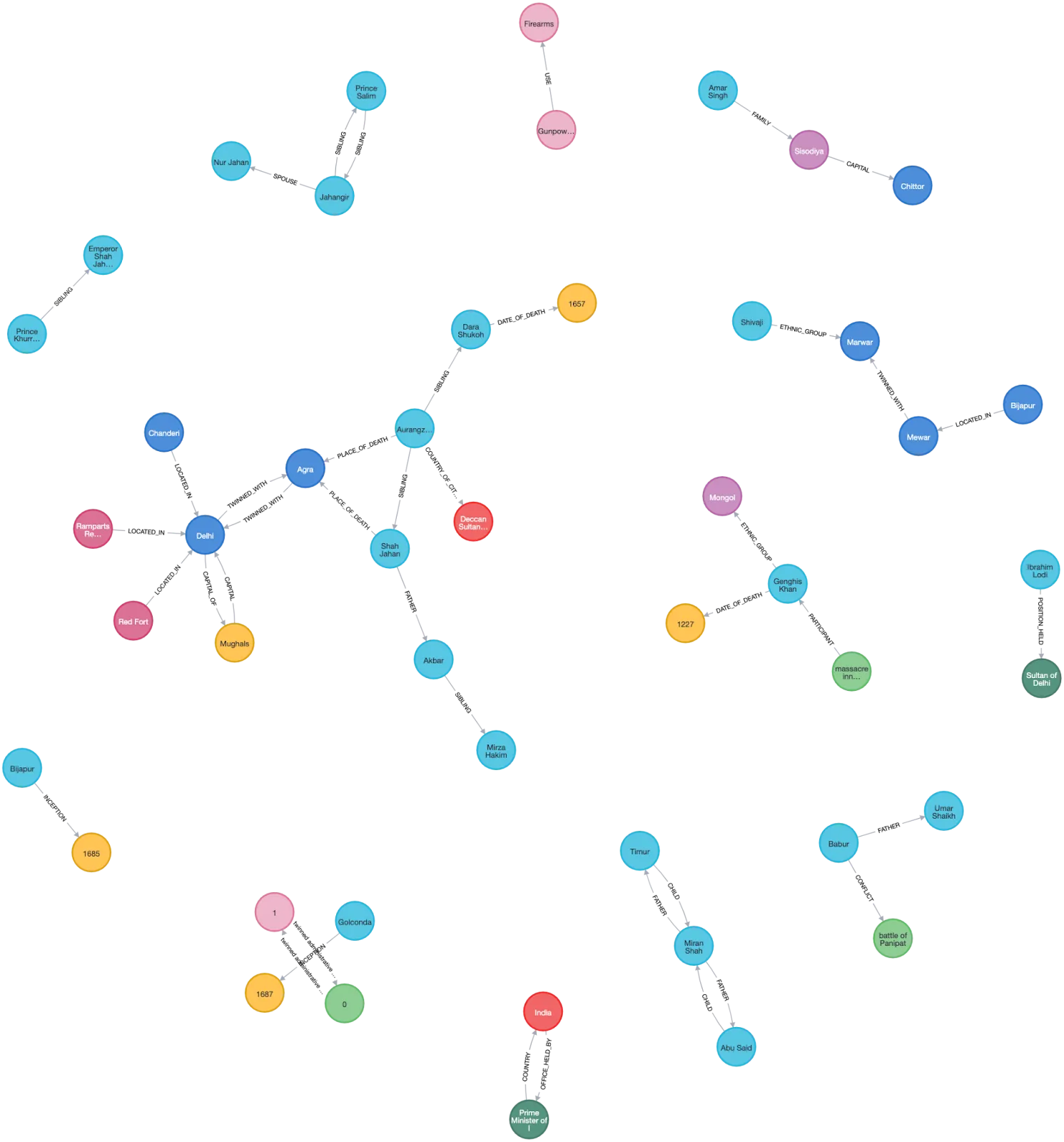
Now we will understand the two Python classes that we are importing; the first is KnowledgeGraphExtractor.
from PyPDF2 import PdfReader
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
from langchain_text_splitters import RecursiveCharacterTextSplitter
import urllib.request
import os
import tempfile
class KnowledgeGraphExtractor:
#Now loading the REBEL model
def __init__(self):
self.tokenizer = AutoTokenizer.from_pretrained("Babelscape/rebel-large")
self.model = AutoModelForSeq2SeqLM.from_pretrained("Babelscape/rebel-large")
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, length_function=len, is_separator_regex=False)
# Method to extract text from a PDF file
def extract_text_from_pdf(self, file_path):
text = ""
with open(file_path, "rb") as pdf_file:
pdf_reader = PdfReader(pdf_file)
for page_num in range(len(pdf_reader.pages)):
text += pdf_reader.pages[page_num].extract_text()
return text
# Method to extract text from a TXT file
def extract_text_from_txt(self, file_path):
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
# Method to extract text from a PDF URL
def extract_text_from_url(self, url):
# Create a temporary file that persists after it is closed
with tempfile.NamedTemporaryFile(delete=False) as temp_file:
# Get the path of the temporary file
temp_file_path = temp_file.name
# Download the file from the URL and save it to the temporary file
urllib.request.urlretrieve(url, temp_file_path)
try:
# Extract text from the downloaded PDF file
return self.extract_text_from_pdf(temp_file_path)
finally:
# Ensure the temporary file is removed after processing
os.remove(temp_file_path)Below is the helper function (available from the model’s Hugging Face page) that takes the text and returns a triplet containing an entity pair and their relationship.
# Method to extract triplets from text
def extract_triplets(self, text):
triplets = [] # Initialize an empty list to store the extracted triplets
relation, subject, object_ = '', '', ''
text = text.strip() # Remove leading and trailing whitespace from the text
current = 'x'
for token in text.replace("<s>", "").replace("<pad>", "").replace("</s>", "").split():
if token == "<triplet>": # Start of a new triplet
current = 't'
if relation != '': # If there's an ongoing relation, save the previous triplet
triplets.append({'head': subject.strip(), 'type': relation.strip(), 'tail': object_.strip()})
relation = '' # Reset the relation
subject = '' # Reset the subject
elif token == "<subj>": # Start of a new subject
current = 's'
if relation != '':
triplets.append({'head': subject.strip(), 'type': relation.strip(), 'tail': object_.strip()})
object_ = '' # Reset the object
elif token == "<obj>":
current = 'o'
relation = ''
else:
if current == 't':
subject += ' ' + token
elif current == 's':
object_ += ' ' + token
elif current == 'o':
relation += ' ' + token
# After the loop, check if there's an unfinished triplet and append it
if subject != '' and relation != '' and object_ != '':
triplets.append({'head': subject.strip(), 'type': relation.strip(), 'tail': object_.strip()})
return triplets
Wrapping all the above into a single function that takes text as input and returns the Knowledge Graph for that text. We will explain the KB class after this function.
# Method to create a knowledge base from text
def from_small_text_to_kb(self, text, verbose=False):
kb = KB() # Initialize a new knowledge base object
model_inputs = self.tokenizer(text, max_length=512, padding=True, truncation=True, return_tensors='pt')
if verbose:
print(f"Num tokens: {len(model_inputs['input_ids'][0])}")
# Generate predictions using the model
generated_tokens = self.model.generate(
**model_inputs,
max_length=216,
length_penalty=0,
num_beams=3,
num_return_sequences=3
)
decoded_preds = self.tokenizer.batch_decode(generated_tokens, skip_special_tokens=False)
# Extract triplets from each predicted sentence and add them to the knowledge base
for sentence_pred in decoded_preds:
relations = self.extract_triplets(sentence_pred)
for r in relations:
kb.add_relation(r)
return kb
# Helper function to check if a file is allowed based on its extension
def allowed_file(self, filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in {'txt', 'pdf'}
Now we will explain the second Python class that we are importing: KB. This function creates a Knowledge Graph class to store information about the nodes and the edges.
class KB():
def __init__(self):
self.relations = [] # Initialize an empty list to store relations
# Method to check if two relations are equal by comparing their 'head', 'type', and 'tail' attributes
def are_relations_equal(self, r1, r2):
return all(r1[attr] == r2[attr] for attr in ["head", "type", "tail"])
# Method to check if a given relation already exists in the knowledge base
def exists_relation(self, r1):
return any(self.are_relations_equal(r1, r2) for r2 in self.relations)
# add a new relation to the knowledge base if it doesn't already exist
def add_relation(self, r):
if not self.exists_relation(r):
self.relations.append(r)
def print(self):
print("Relations:")
for r in self.relations:
print(f" {r}")Conclusion
This project utilizes the REBEL model and Flask API to convert unstructured PDF data into Cypher queries for generating Knowledge Graphs. This enables better data comprehension and analysis through Neo4j’s graph database system.
Now you can use these Knowledge Graph Cypher queries for retrieval-augmented generation for your LLM.



-Feature-Image.CjBFdO7y_Z1bTNvg.webp)