Introduction
AI-powered chatbots are transforming the healthcare industry by offering a range of benefits for both patients and medical providers. BioMistral-7B is a specialized large language model (LLM) designed for the medical domain. It is specifically trained on medical text data, including information from PubMed Central, a vast resource of biomedical and life sciences literature. This allows it to understand and process medical concepts and language more effectively than general-purpose LLMs. BioMistral-7B is publicly available and free to use. This fosters research and development in medical AI and allows others to build applications on top of this LLM. The potential applications of this LLM includes medical research, diagnostics, drug discovery and more.
Outline of the Current Project
This project aims to build a chatbot that talks to users and answers their health questions. Here’s how it works:
-
The Brains (LLM): BioMistral is a free, open-source large language model (LLM) specially trained to understand medical topics. To run it efficiently on your computer (CPU), the project uses a smaller, faster and lighter version of the model, which is achieved through quantization and model merging approaches that is also called a quantized model. It surpasses other open medical AI and even rivals private models. Researchers released everything used to create BioMistral, making it a powerful tool for the medical field.
-
Understanding Text (Embedding Model): PubMedBert is another powerful open-source model used in this project. It’s like a translator, turning written text (questions and documents) into a special code (768-dimensional vectors) that the computer can understand better. This PubMedBert model is particularly good at handling medical text.
-
Storing Information (Database): Qdrant is a free, open-source database specifically designed for storing these special codes (vectors). This allows the chatbot to find documents related to your question quickly.
-
Putting It All Together (Framework): LangChain and Llama CPP are like the directors of this play. They tell each part (LLM, database) what to do and when, ensuring everything runs smoothly.
Overall, this project uses freely available tools to create a chatbot that can answer your health questions by understanding your text, searching through related information, and using a powerful language model to provide helpful answers. The project will also support a graphical user interface that runs on the local system to summarize the entire understanding of the system, as well as show a working model.
Prerequisites
The project was created on a Windows system and there are certain tools and installations that are needed prior to executing the code. Install the following software:
-
Conda is an open-source package and environment management system that runs on Windows, macOS, and Linux. Conda quickly installs, runs, and updates packages and their dependencies. It also easily creates, saves, loads, and switches between environments on your local computer. It was created for Python programs, but it can package and distribute software for any language.
-
Once installation of Conda is done, also ensure that the Conda Windows prompt is available.
It is a special command prompt window specifically designed to work with Conda. It allows you to use Conda commands to manage software packages and environments on your Windows machine. Occasionally, the prompt might not be instantly available on searching from the Start Menu. Follow the steps mentioned here to get the prompt in the Start Menu.
-
Docker Desktop is a secure, out-of-the-box containerization software offering developers and teams a robust, hybrid toolkit to build, share, and run applications anywhere. Once Docker is installed, start the app and ensure it is running on the system.
-
To further Run/Install certain modules for the steps shared below, CMAKE needs to be available on the Windows system. It is recommended to install the Windows 10 SDK.
-
Download and keep the quantized version of BioMistral from here to the project directory. Note that the Quantized models are available here.
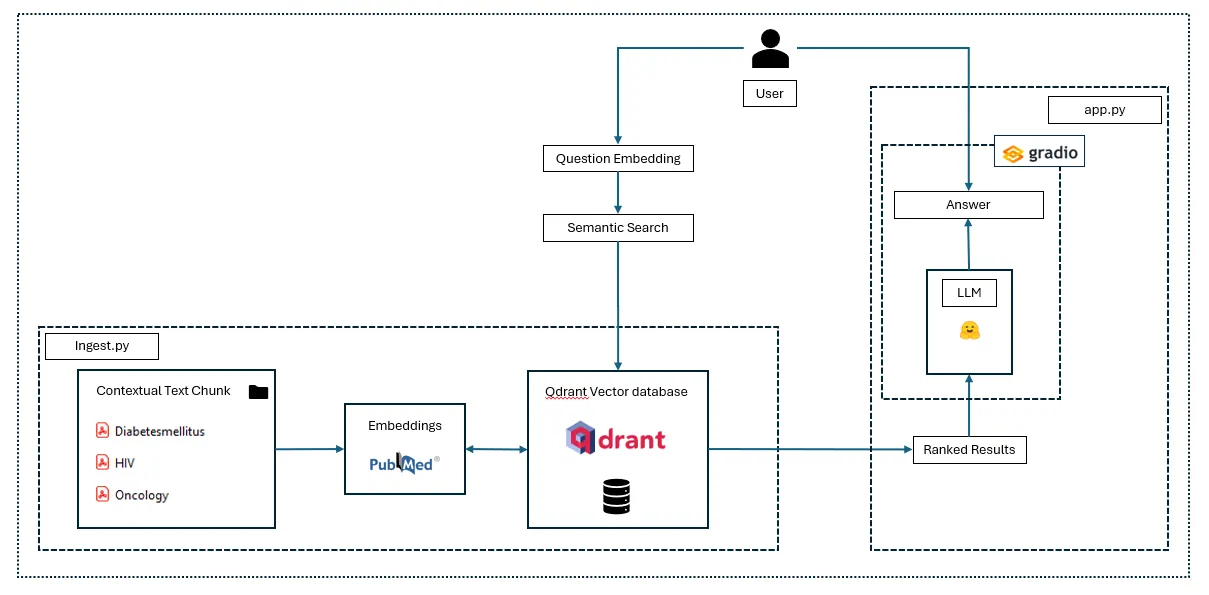
Architecture
1. Preprocessing and Document Storage:
- All contextual documents are converted into numerical representations called “vector embeddings” using a script named ingest.py. The system relies on these contextual data files that are run through a chosen model. Each text chunk is run through the chosen model. The model analyzes the text and generates a numerical vector representation (embedding) for each chunk. This vector captures the semantic meaning and relationships between words within the chunk. The contextual files are stored in the “data folder” and currently includes three PDF files. You can add more documents in any format for the system to learn from.
- These embeddings are stored in the vector database Qdrant for efficient retrieval.
2. User Query and Retrieval:
- When a user submits a question, the system searches the database for documents with the most similar embeddings (meaning most relevant topics).
3. Limited Context for LLM:
- These retrieved documents (instead of the entire document collection) become the context for the Large Language Model (LLM). This reduces the amount of information the LLM needs to process at once.
4. Conversational Retrieval Chain (CRC):
- To improve memory and context for the LLM, a Conversational Retrieval Chain (CRC) is used.
- The CRC feeds the LLM with both the current user query and the previous question-answer pair from the conversation history.
5. Improved LLM Responses:
- By providing this broader context, the LLM can understand the conversation flow and user intent better, leading to more relevant and informative responses.
Step by Step Implementation
Step 1: Set up the virtual environment
- Open the Conda command prompt and create a new Python environment
conda create -n myenv python=3.9- Activate the Python Environment
conda activate myenvStep 2: Install the required libraries using the requirement.txt file
- Add the required library names and versions to the requirements.txt file:
langchain==0.1.9
langchain_community==0.0.24
sentence_transformers==2.4.0
unstructured
unstructured[pdf]
qdrant-client
llama-cpp-python
gradio- Run the install command:
pip install -r requirements.txtStep 3: Set up Qdrant
This step involves setting up the Docker Image of Qdrant
- Set the Path Variable for the present working directory in the List of Path Variables
conda env config vars set pwd=[present working directory]
E.g. if the current working directory is “C:\Users\JohnDoe\Work\ChatBot”, then the above command should be conda env config vars set
pwd=C:/Users/JohnDoe/Work/ChatBot- Pull the Docker Image for Qdrant
docker pull qdrant/qdrant- Start the Qdrant Container
docker run -p 6333:6333 -p 6334:6334 -v $(pwd)/qdrant_storage:/qdrant/storage:z
qdrant/qdrant- Note the LocalHost URL on which the service is running. This will be available from the Conda prompt
- The same can also be verified from the Images section of Docker Desktop
Step 4: Ensure that the downloaded quantized file is available in the project setup directory
- Copy the downloaded file “BioMistral-7B.Q4_K_M.gguf” to the project directory
Step 5: Ingest data to the Qdrant collection
- Create a Python File “ingest.py” and create the following code in the file
- Import Libraries
import os
from langchain_community.embeddings import SentenceTransformerEmbeddings
from langchain_community.document_loaders import UnstructuredFileLoader, DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Qdrant- os: Accesses operating system functionalities for things like file path handling.
- SentenceTransformerEmbeddings: Used for generating sentence embeddings, a way to represent text as numerical vectors.
- UnstructuredFileLoader, DirectoryLoader: Tools for loading documents from files and directories.
- RecursiveCharacterTextSplitter: Splits text into smaller chunks for embedding.
- Qdrant: Connects to a vector database (Qdrant) for storing and searching embeddings.
- Load the embedding model:
embeddings = SentenceTransformerEmbeddings(model_name="NeuML/pubmedbert-base-embeddings")- Loads a pre-trained sentence embedding model called “NeuML/pubmedbert-base-embeddings”, specifically designed for biomedical text.
- Load PDF Documents:
loader = DirectoryLoader('data/', glob="**/*.pdf", show_progress=True, loader_cls=UnstructuredFileLoader)
documents = loader.load()- Loads the PDF documents from the ‘data/’ directory (including subdirectories due to ”**/*.pdf” pattern).
- Uses UnstructuredFileLoader for handling unstructured text files like PDFs.
- Split text into chunks:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=700, chunk_overlap=70)
texts = text_splitter.split_documents(documents)- Breaks down longer text into smaller chunks of 700 characters with a 70-character overlap to preserve context.
- Longer text is better handled in smaller segments for embedding.
- Create the Vector Database:
url = "http://localhost:6333" # This is the same URL that must match Step 4d
qdrant = Qdrant.from_documents(
texts,
embeddings,
url=url,
prefer_grpc=False,
collection_name="vector_db"
)- Connects to a Qdrant vector database at the specified URL.
- Embeds the text chunks using the chosen model.
- Stores the embeddings and creates a searchable database called “vector_db”.
- Add a print message for successful Vector database creation
print("Vector DB Successfully Created!")
- Execute the code to ingest the actual file:
python ingest.py- Verify that the code executed and completed with the message as depicted in Step g

![]()
Step 6: Create the interface using Gradio that will query the model
-
Create a file called “app.py” to run the UI interface
-
In the file setup the necessary libraries for language models, question answering, vector databases, templating, and Gradio interface.
from langchain import PromptTemplate
from langchain_community.llms import LlamaCpp
from langchain.chains import RetrievalQA
from langchain.chains import ConversationalRetrievalChain
from langchain.prompts import SystemMessagePromptTemplate
from langchain_community.embeddings import SentenceTransformerEmbeddings
from fastapi import FastAPI, Request, Form, Response
from fastapi.responses import HTMLResponse
from fastapi.templating import Jinja2Templates
from fastapi.staticfiles import StaticFiles
from fastapi.encoders import jsonable_encoder
from qdrant_client import QdrantClient
from langchain_community.vectorstores import Qdrant
import os
import json
import gradio as gr- Load a local BioMistral LLM model with specified settings.
local_llm = "BioMistral-7B.Q4_K_M.gguf"
llm = LlamaCpp(model_path=
local_llm,temperature=0.3,max_tokens=2048,top_p=1,n_ctx= 2048)- Define a prompt template to guide LLM responses.
prompt_template = """Use the following pieces of information to answer the user's question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Chat History: {chat_history}
Question: {question}
Only return the helpful answer. Answer must be detailed and well explained.
Helpful answer:
"""
- Create sentence embeddings model for representing text as vectors.
embeddings =
SentenceTransformerEmbeddings(model_name="NeuML/pubmedbert-base-embeddings")- Connect to a Qdrant vector database for storing and retrieving information.
url = "http://localhost:6333"
client = QdrantClient(url=url, prefer_grpc=False)
db = Qdrant(client=client, embeddings=embeddings, collection_name="vector_db")- Initialize a retriever for searching within the database.
retriever = db.as_retriever(search_kwargs={"k":1})- Create an empty chat history list to track conversation. Note that this will be used for the LLM model. This list will store list of tuples.
chat_history = []- Create a ConversationalRetrievalChain, combining LLM and retriever for context-aware answers. Note that this needs to be outside the chatbot message function so that the context is not reset with every question and answer.
# Create the custom chain
if llm is not None and db is not None:
chain =
ConversationalRetrievalChain.from_llm(llm=llm,retriever=retriever)
else:
print("LLM or Vector Database not initialized")- Define the actual prediction function that will carry on the chatbot conversation. The function takes a user message and conversation history as input. The history information is a list of lists that stored the questions that were asked to the chatbot and the answers that were received.
def predict(message, history):- Format history for compatibility with LangChain.
history_langchain_format = []- Guide LLM with prompt and conversation history to generate a response.
prompt = PromptTemplate(template=prompt_template,
input_variables=["chat_history", 'message'])
response = chain({"question": message, "chat_history": chat_history})- Update chat history with the current turn (message and answer).
answer = response['answer']- Format and add the current message and reply for the LLM list. Note this is the list of tuples that were discussed earlier.
chat_history.append((message, answer))- Format history for Gradio interface display. Note this is the ‘list of lists’ that was earlier discussed in #’j’ above
temp = []
for input_question, bot_answer in history:
temp.append(input_question)
temp.append(bot_answer)
history_langchain_format.append(temp)
temp.clear()
temp.append(message)
temp.append(answer)
history_langchain_format.append(temp)- Returns the generated answer.
return answer- Create a chat interface using Gradio, powered by the predict function for user interaction. Launch the interface, allowing users to converse with the system.
gr.ChatInterface(predict).launch()- Run the code “app.py”
gradio app.py- Note the URL on which the server is running and open the same from the browser.

- Converse with the chatbot
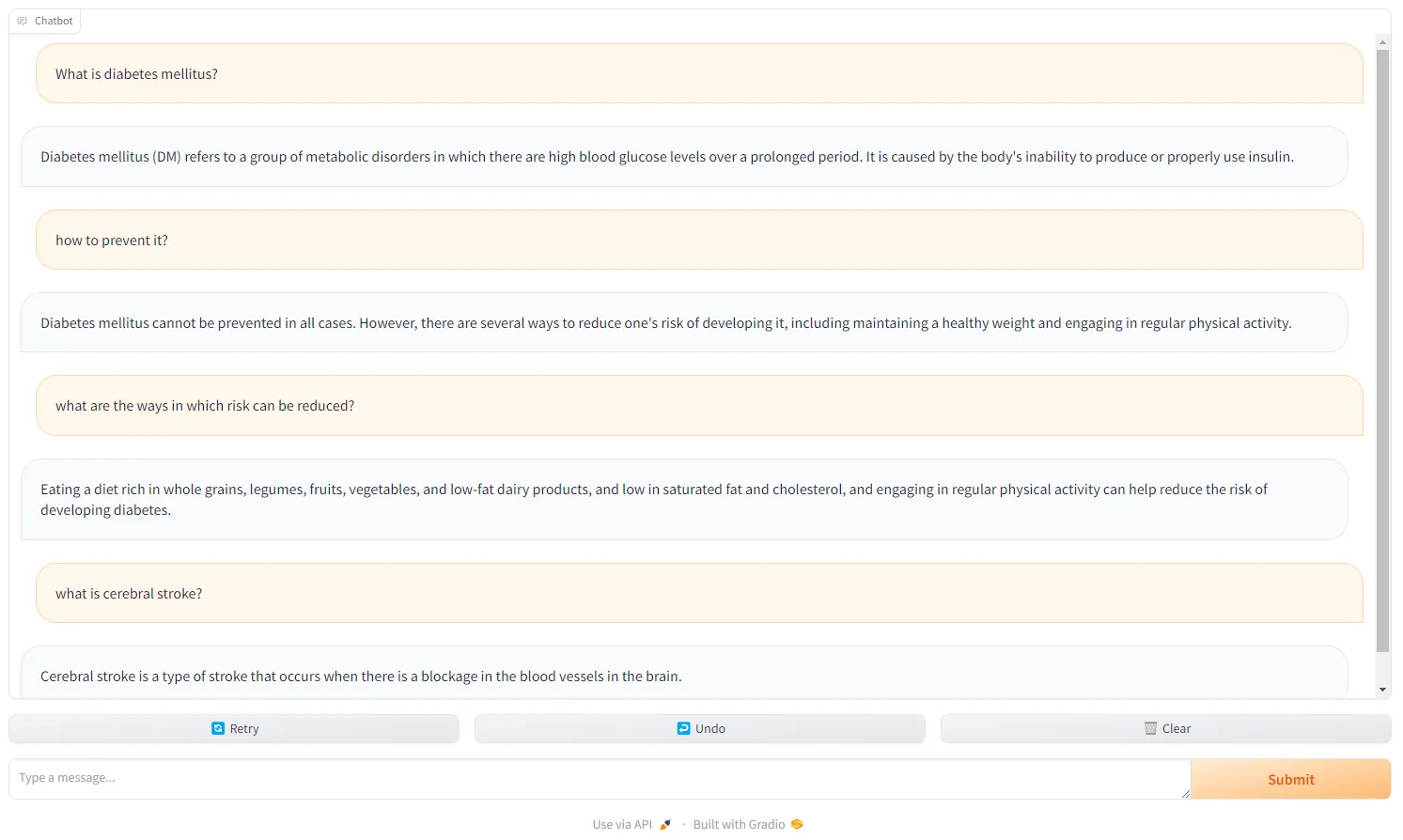
Conclusion
- The code establishes a question-answering chatbot that leverages both a language model (BioMistral) and a vector database (Qdrant).
- It maintains conversation history to provide context for LLM responses.
- The Gradio interface enables a user-friendly chat experience.
References
- https://www.toolify.ai/ai-news/building-a-medical-rag-chatbot-with-biomistral-the-ultimate-ai-guide-2428902#google_vignette
- https://www.youtube.com/watch?v=LbT1yp6quS8
- https://huggingface.co/BioMistral/BioMistral-7B
- https://www.gradio.app/guides/quickstart
- https://github.com/joyceannie/Medical_ChatBot?tab=readme-ov-file
- https://huggingface.co/MaziyarPanahi/BioMistral-7B-GGUF/tree/main
- https://saturncloud.io/blog/how-to-install-python-39-with-conda-a-guide-for-data-scientists/
- https://monovm.com/blog/conda-command-not-found-fixed/#:~:text=How%20to%20fix%20Conda%20command%20not%20found%20error%20in%20Windows,Users%5Cusername%5CAnaconda3%5C’.
- https://qdrant.tech/documentation/quick-start/
- https://conda.io/projects/conda/en/latest/commands/env/config/vars/index.html
- https://stackoverflow.com/questions/77267346/error-while-installing-python-package-llama-cpp-python
- https://www.docker.com/products/docker-desktop/
- https://developer.microsoft.com/en-us/windows/downloads/windows-sdk/
- https://learn.microsoft.com/en-us/cpp/build/cmake-projects-in-visual-studio?view=msvc-170
- https://www.researchgate.net/publication/270283336_Diabetes_mellitus
- https://stackoverflow.com/questions/76722077/why-doesnt-langchain-conversationalretrievalchain-remember-the-chat-history-ev



-Feature-Image.CjBFdO7y_Z1bTNvg.webp)